 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAVER: A Toolbox for Sampling-Based, Probabilistic Verification of Neural Networks
Dec 04, 2024



We present a neural network verification toolbox to 1) assess the probability of satisfaction of a constraint, and 2) synthesize a set expansion factor to achieve the probability of satisfaction. Specifically, the tool box establishes with a user-specified level of confidence whether the output of the neural network for a given input distribution is likely to be contained within a given set. Should the tool determine that the given set cannot satisfy the likelihood constraint, the tool also implements an approach outlined in this paper to alter the constraint set to ensure that the user-defined satisfaction probability is achieved. The toolbox is comprised of sampling-based approaches which exploit the properties of signed distance function to define set containment.
Optimal Control of Logically Constrained Partially Observable and Multi-Agent Markov Decision Processes
May 24, 2023Autonomous systems often have logical constraints arising, for example, from safety, operational, or regulatory requirements. Such constraints can be expressed using temporal logic specifications. The system state is often partially observable. Moreover, it could encompass a team of multiple agents with a common objective but disparate information structures and constraints. In this paper, we first introduce an optimal control theory for partially observable Markov decision processes (POMDPs) with finite linear temporal logic constraints. We provide a structured methodology for synthesizing policies that maximize a cumulative reward while ensuring that the probability of satisfying a temporal logic constraint is sufficiently high. Our approach comes with guarantees on approximate reward optimality and constraint satisfaction. We then build on this approach to design an optimal control framework for logically constrained multi-agent settings with information asymmetry. We illustrate the effectiveness of our approach by implementing it on several case studies.
Model-Free Reinforcement Learning for Optimal Control of MarkovDecision Processes Under Signal Temporal Logic Specifications
Sep 27, 2021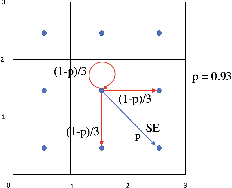
We present a model-free reinforcement learning algorithm to find an optimal policy for a finite-horizon Markov decision process while guaranteeing a desired lower bound on the probability of satisfying a signal temporal logic (STL) specification. We propose a method to effectively augment the MDP state space to capture the required state history and express the STL objective as a reachability objective. The planning problem can then be formulated as a finite-horizon constrained Markov decision process (CMDP). For a general finite horizon CMDP problem with unknown transition probability, we develop a reinforcement learning scheme that can leverage any model-free RL algorithm to provide an approximately optimal policy out of the general space of non-stationary randomized policies. We illustrate the effectiveness of our approach in the context of robotic motion planning for complex missions under uncertainty and performance objectives.
A Sample-Efficient Algorithm for Episodic Finite-Horizon MDP with Constraints
Sep 23, 2020Constrained Markov Decision Processes (CMDPs) formalize sequential decision-making problems whose objective is to minimize a cost function while satisfying constraints on various cost functions. In this paper, we consider the setting of episodic fixed-horizon CMDPs. We propose an online algorithm which leverages the linear programming formulation of finite-horizon CMDP for repeated optimistic planning to provide a probably approximately correct (PAC) guarantee on the number of episodes needed to ensure an $\epsilon$-optimal policy, i.e., with resulting objective value within $\epsilon$ of the optimal value and satisfying the constraints within $\epsilon$-tolerance, with probability at least $1-\delta$. The number of episodes needed is shown to be of the order $\tilde{\mathcal{O}}\big(\frac{|S||A|C^{2}H^{2}}{\epsilon^{2}}\log\frac{1}{\delta}\big)$, where $C$ is the upper bound on the number of possible successor states for a state-action pair. Therefore, if $C \ll |S|$, the number of episodes needed have a linear dependence on the state and action space sizes $|S|$ and $|A|$, respectively, and quadratic dependence on the time horizon $H$.