 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePure Exploration for Constrained Best Mixed Arm Identification with a Fixed Budget
May 23, 2024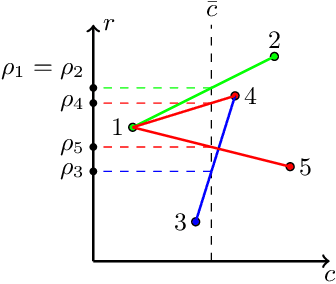
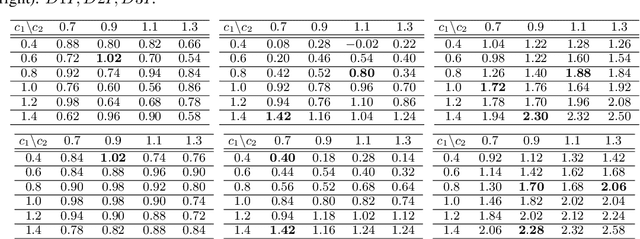
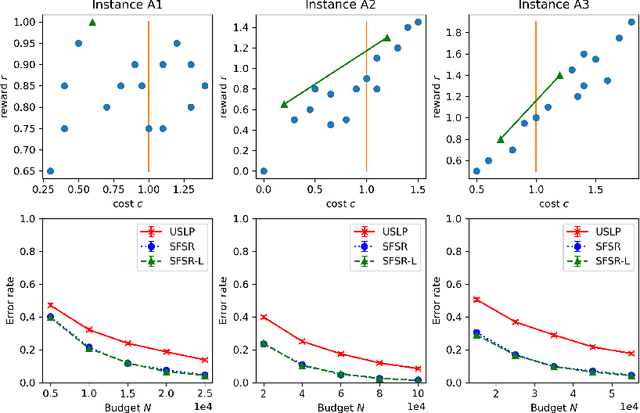
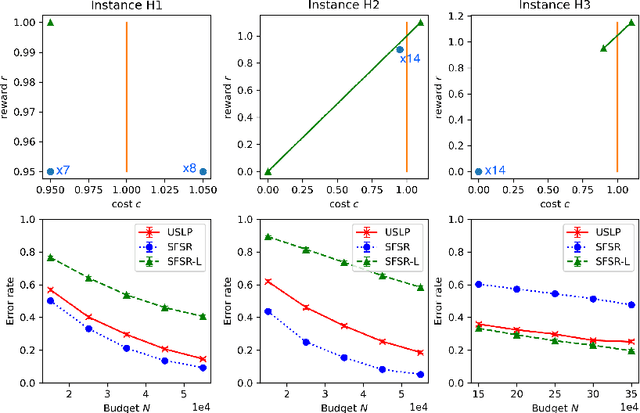
In this paper, we introduce the constrained best mixed arm identification (CBMAI) problem with a fixed budget. This is a pure exploration problem in a stochastic finite armed bandit model. Each arm is associated with a reward and multiple types of costs from unknown distributions. Unlike the unconstrained best arm identification problem, the optimal solution for the CBMAI problem may be a randomized mixture of multiple arms. The goal thus is to find the best mixed arm that maximizes the expected reward subject to constraints on the expected costs with a given learning budget $N$. We propose a novel, parameter-free algorithm, called the Score Function-based Successive Reject (SFSR) algorithm, that combines the classical successive reject framework with a novel score-function-based rejection criteria based on linear programming theory to identify the optimal support. We provide a theoretical upper bound on the mis-identification (of the the support of the best mixed arm) probability and show that it decays exponentially in the budget $N$ and some constants that characterize the hardness of the problem instance. We also develop an information theoretic lower bound on the error probability that shows that these constants appropriately characterize the problem difficulty. We validate this empirically on a number of average and hard instances.
Efficient Online Learning with Offline Datasets for Infinite Horizon MDPs: A Bayesian Approach
Oct 17, 2023In this paper, we study the problem of efficient online reinforcement learning in the infinite horizon setting when there is an offline dataset to start with. We assume that the offline dataset is generated by an expert but with unknown level of competence, i.e., it is not perfect and not necessarily using the optimal policy. We show that if the learning agent models the behavioral policy (parameterized by a competence parameter) used by the expert, it can do substantially better in terms of minimizing cumulative regret, than if it doesn't do that. We establish an upper bound on regret of the exact informed PSRL algorithm that scales as $\tilde{O}(\sqrt{T})$. This requires a novel prior-dependent regret analysis of Bayesian online learning algorithms for the infinite horizon setting. We then propose an approximate Informed RLSVI algorithm that we can interpret as performing imitation learning with the offline dataset, and then performing online learning.
Regret Analysis of the Posterior Sampling-based Learning Algorithm for Episodic POMDPs
Oct 16, 2023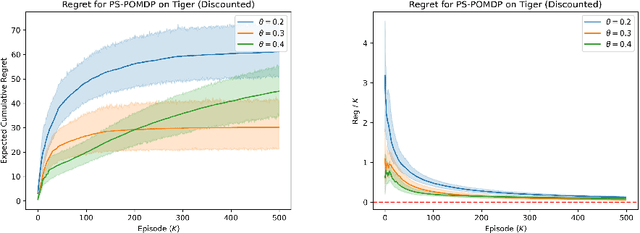


Compared to Markov Decision Processes (MDPs), learning in Partially Observable Markov Decision Processes (POMDPs) can be significantly harder due to the difficulty of interpreting observations. In this paper, we consider episodic learning problems in POMDPs with unknown transition and observation models. We consider the Posterior Sampling-based Reinforcement Learning (PSRL) algorithm for POMDPs and show that its Bayesian regret scales as the square root of the number of episodes. In general, the regret scales exponentially with the horizon length $H$, and we show that this is inevitable by providing a lower bound. However, under the condition that the POMDP is undercomplete and weakly revealing, we establish a polynomial Bayesian regret bound that improves the regret bound by a factor of $\Omega(H^2\sqrt{SA})$ over the recent result by arXiv:2204.08967.
A Novel Point-based Algorithm for Multi-agent Control Using the Common Information Approach
Apr 10, 2023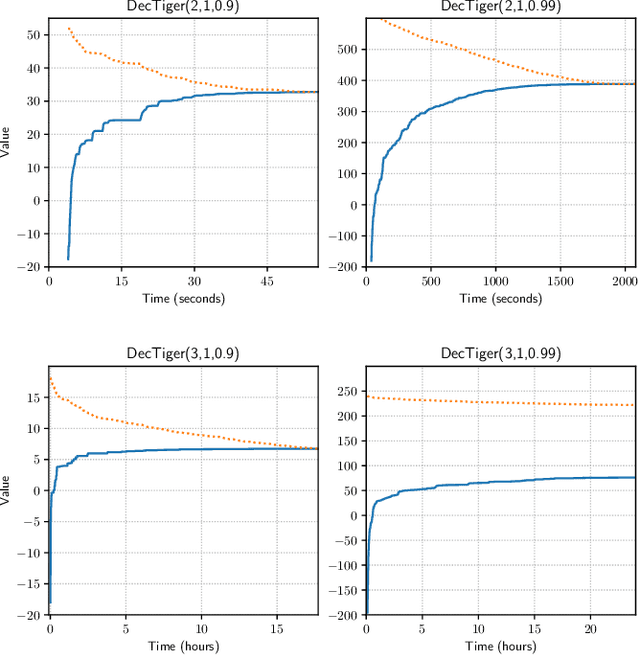
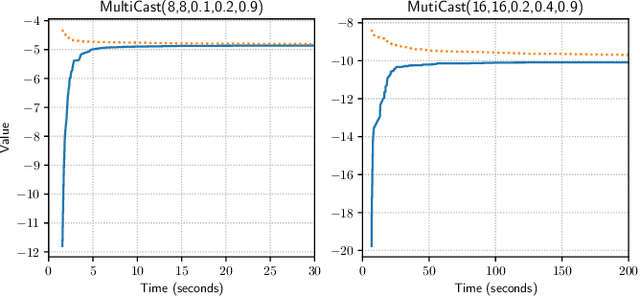
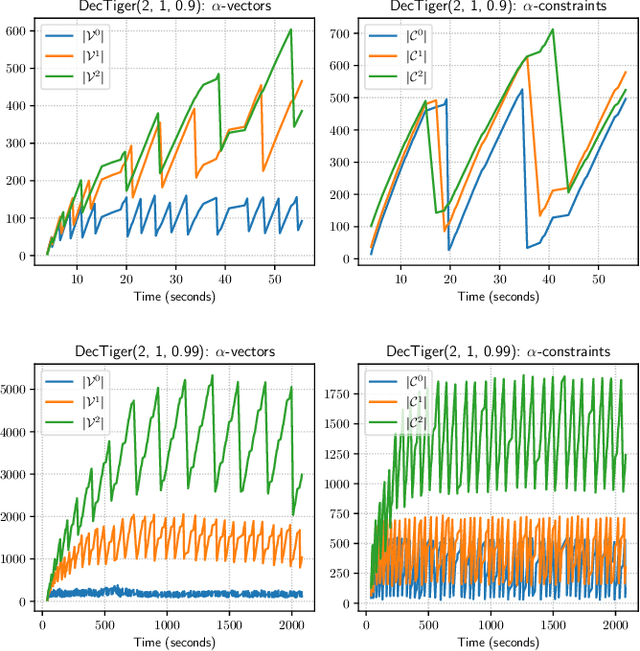
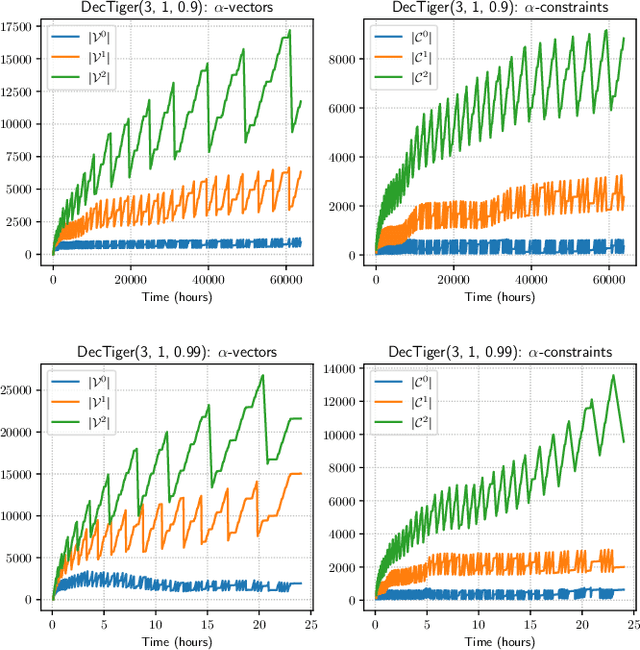
The Common Information (CI) approach provides a systematic way to transform a multi-agent stochastic control problem to a single-agent partially observed Markov decision problem (POMDP) called the coordinator's POMDP. However, such a POMDP can be hard to solve due to its extraordinarily large action space. We propose a new algorithm for multi-agent stochastic control problems, called coordinator's heuristic search value iteration (CHSVI), that combines the CI approach and point-based POMDP algorithms for large action spaces. We demonstrate the algorithm through optimally solving several benchmark problems.
Bridging Imitation and Online Reinforcement Learning: An Optimistic Tale
Mar 20, 2023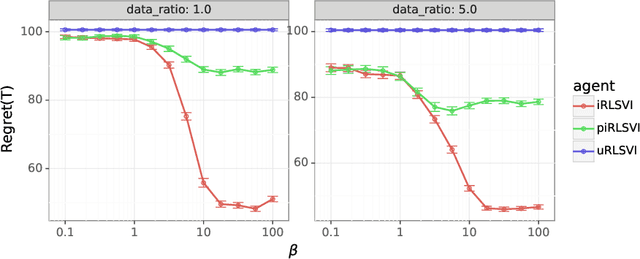
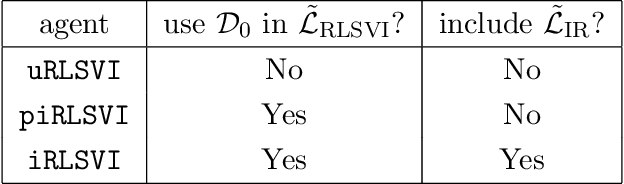
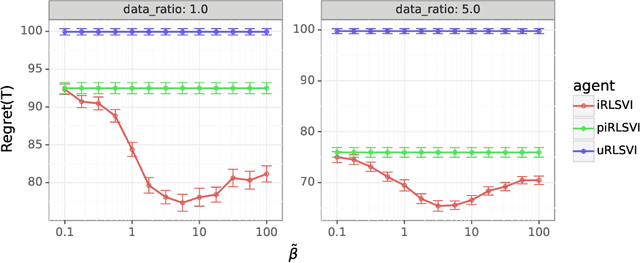
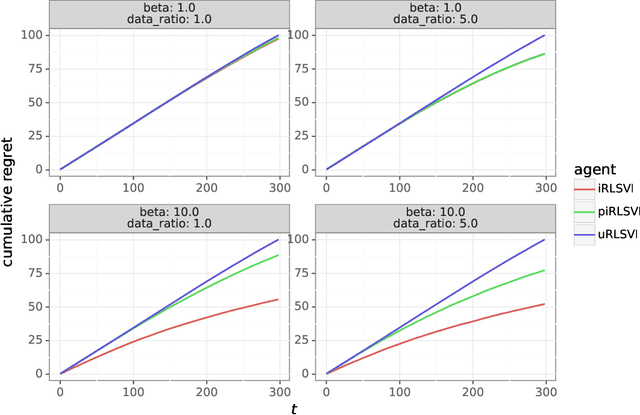
In this paper, we address the following problem: Given an offline demonstration dataset from an imperfect expert, what is the best way to leverage it to bootstrap online learning performance in MDPs. We first propose an Informed Posterior Sampling-based RL (iPSRL) algorithm that uses the offline dataset, and information about the expert's behavioral policy used to generate the offline dataset. Its cumulative Bayesian regret goes down to zero exponentially fast in N, the offline dataset size if the expert is competent enough. Since this algorithm is computationally impractical, we then propose the iRLSVI algorithm that can be seen as a combination of the RLSVI algorithm for online RL, and imitation learning. Our empirical results show that the proposed iRLSVI algorithm is able to achieve significant reduction in regret as compared to two baselines: no offline data, and offline dataset but used without information about the generative policy. Our algorithm bridges online RL and imitation learning for the first time.