 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Simple Regret Algorithms for Stochastic Contextual Bandits
Jan 29, 2026We study stochastic contextual logistic bandits under the simple regret objective. While simple regret guarantees have been established for the linear case, no such results were previously known for the logistic setting. Building on ideas from contextual linear bandits and self-concordant analysis, we propose the first algorithm that achieves simple regret $\tilde{\mathcal{O}}(d/\sqrt{T})$. Notably, the leading term of our regret bound is free of the constant $κ= \mathcal O(\exp(S))$, where $S$ is a bound on the magnitude of the unknown parameter vector. The algorithm is shown to be fully tractable when the action set is finite. We also introduce a new variant of Thompson Sampling tailored to the simple-regret setting. This yields the first simple regret guarantee for randomized algorithms in stochastic contextual linear bandits, with regret $\tilde{\mathcal{O}}(d^{3/2}/\sqrt{T})$. Extending this method to the logistic case, we obtain a similarly structured Thompson Sampling algorithm that achieves the same regret bound -- $\tilde{\mathcal{O}}(d^{3/2}/\sqrt{T})$ -- again with no dependence on $κ$ in the leading term. The randomized algorithms, as expected, are cheaper to run than their deterministic counterparts. Finally, we conducted a series of experiments to empirically validate these theoretical guarantees.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Efficient Exploration for LLMs
Feb 01, 2024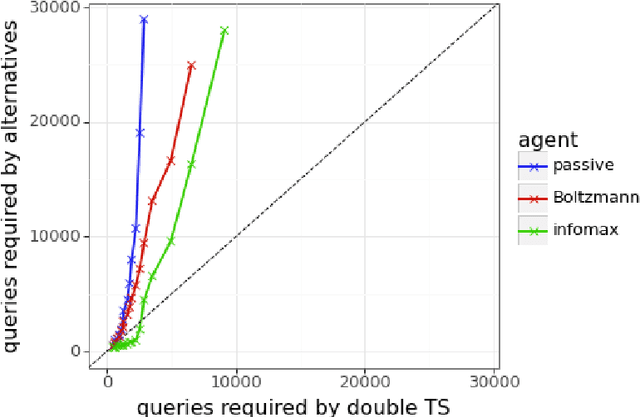
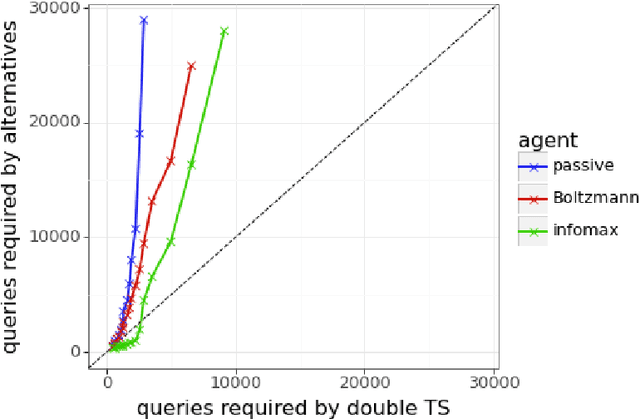
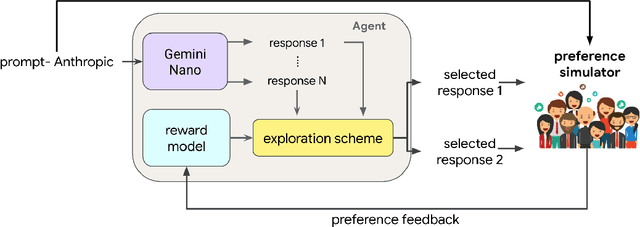
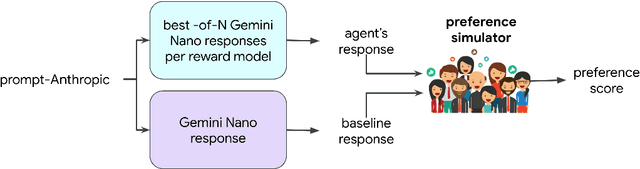
We present evidence of substantial benefit from efficient exploration in gathering human feedback to improve large language models. In our experiments, an agent sequentially generates queries while fitting a reward model to the feedback received. Our best-performing agent generates queries using double Thompson sampling, with uncertainty represented by an epistemic neural network. Our results demonstrate that efficient exploration enables high levels of performance with far fewer queries. Further, both uncertainty estimation and the choice of exploration scheme play critical roles.
Efficient Online Learning with Offline Datasets for Infinite Horizon MDPs: A Bayesian Approach
Oct 17, 2023In this paper, we study the problem of efficient online reinforcement learning in the infinite horizon setting when there is an offline dataset to start with. We assume that the offline dataset is generated by an expert but with unknown level of competence, i.e., it is not perfect and not necessarily using the optimal policy. We show that if the learning agent models the behavioral policy (parameterized by a competence parameter) used by the expert, it can do substantially better in terms of minimizing cumulative regret, than if it doesn't do that. We establish an upper bound on regret of the exact informed PSRL algorithm that scales as $\tilde{O}(\sqrt{T})$. This requires a novel prior-dependent regret analysis of Bayesian online learning algorithms for the infinite horizon setting. We then propose an approximate Informed RLSVI algorithm that we can interpret as performing imitation learning with the offline dataset, and then performing online learning.
Sequential Best-Arm Identification with Application to Brain-Computer Interface
May 17, 2023A brain-computer interface (BCI) is a technology that enables direct communication between the brain and an external device or computer system. It allows individuals to interact with the device using only their thoughts, and holds immense potential for a wide range of applications in medicine, rehabilitation, and human augmentation. An electroencephalogram (EEG) and event-related potential (ERP)-based speller system is a type of BCI that allows users to spell words without using a physical keyboard, but instead by recording and interpreting brain signals under different stimulus presentation paradigms. Conventional non-adaptive paradigms treat each word selection independently, leading to a lengthy learning process. To improve the sampling efficiency, we cast the problem as a sequence of best-arm identification tasks in multi-armed bandits. Leveraging pre-trained large language models (LLMs), we utilize the prior knowledge learned from previous tasks to inform and facilitate subsequent tasks. To do so in a coherent way, we propose a sequential top-two Thompson sampling (STTS) algorithm under the fixed-confidence setting and the fixed-budget setting. We study the theoretical property of the proposed algorithm, and demonstrate its substantial empirical improvement through both synthetic data analysis as well as a P300 BCI speller simulator example.
Bridging Imitation and Online Reinforcement Learning: An Optimistic Tale
Mar 20, 2023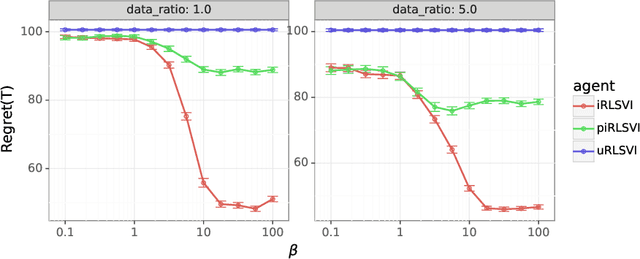
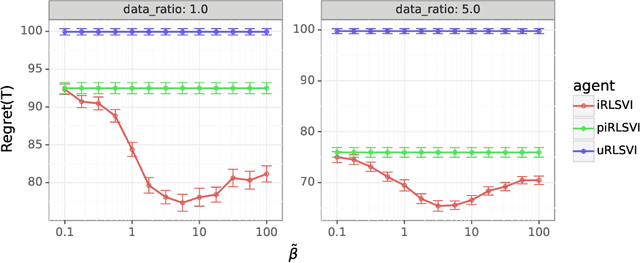
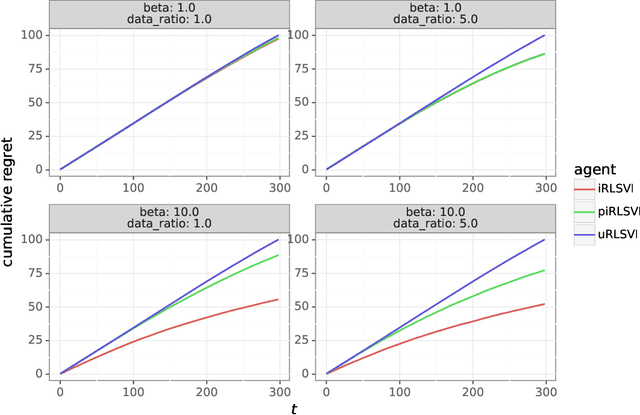
In this paper, we address the following problem: Given an offline demonstration dataset from an imperfect expert, what is the best way to leverage it to bootstrap online learning performance in MDPs. We first propose an Informed Posterior Sampling-based RL (iPSRL) algorithm that uses the offline dataset, and information about the expert's behavioral policy used to generate the offline dataset. Its cumulative Bayesian regret goes down to zero exponentially fast in N, the offline dataset size if the expert is competent enough. Since this algorithm is computationally impractical, we then propose the iRLSVI algorithm that can be seen as a combination of the RLSVI algorithm for online RL, and imitation learning. Our empirical results show that the proposed iRLSVI algorithm is able to achieve significant reduction in regret as compared to two baselines: no offline data, and offline dataset but used without information about the generative policy. Our algorithm bridges online RL and imitation learning for the first time.
Leveraging Demonstrations to Improve Online Learning: Quality Matters
Feb 08, 2023



We investigate the extent to which offline demonstration data can improve online learning. It is natural to expect some improvement, but the question is how, and by how much? We show that the degree of improvement must depend on the quality of the demonstration data. To generate portable insights, we focus on Thompson sampling (TS) applied to a multi-armed bandit as a prototypical online learning algorithm and model. The demonstration data is generated by an expert with a given competence level, a notion we introduce. We propose an informed TS algorithm that utilizes the demonstration data in a coherent way through Bayes' rule and derive a prior-dependent Bayesian regret bound. This offers insight into how pretraining can greatly improve online performance and how the degree of improvement increases with the expert's competence level. We also develop a practical, approximate informed TS algorithm through Bayesian bootstrapping and show substantial empirical regret reduction through experiments.
Sample Efficient Deep Reinforcement Learning via Local Planning
Jan 29, 2023



The focus of this work is sample-efficient deep reinforcement learning (RL) with a simulator. One useful property of simulators is that it is typically easy to reset the environment to a previously observed state. We propose an algorithmic framework, named uncertainty-first local planning (UFLP), that takes advantage of this property. Concretely, in each data collection iteration, with some probability, our meta-algorithm resets the environment to an observed state which has high uncertainty, instead of sampling according to the initial-state distribution. The agent-environment interaction then proceeds as in the standard online RL setting. We demonstrate that this simple procedure can dramatically improve the sample cost of several baseline RL algorithms on difficult exploration tasks. Notably, with our framework, we can achieve super-human performance on the notoriously hard Atari game, Montezuma's Revenge, with a simple (distributional) double DQN. Our work can be seen as an efficient approximate implementation of an existing algorithm with theoretical guarantees, which offers an interpretation of the positive empirical results.
Regret Bounds for Information-Directed Reinforcement Learning
Jun 09, 2022Information-directed sampling (IDS) has revealed its potential as a data-efficient algorithm for reinforcement learning (RL). However, theoretical understanding of IDS for Markov Decision Processes (MDPs) is still limited. We develop novel information-theoretic tools to bound the information ratio and cumulative information gain about the learning target. Our theoretical results shed light on the importance of choosing the learning target such that the practitioners can balance the computation and regret bounds. As a consequence, we derive prior-free Bayesian regret bounds for vanilla-IDS which learns the whole environment under tabular finite-horizon MDPs. In addition, we propose a computationally-efficient regularized-IDS that maximizes an additive form rather than the ratio form and show that it enjoys the same regret bound as vanilla-IDS. With the aid of rate-distortion theory, we improve the regret bound by learning a surrogate, less informative environment. Furthermore, we extend our analysis to linear MDPs and prove similar regret bounds for Thompson sampling as a by-product.