 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelect and Improve: Understanding the Mechanics of Post-Training for Reasoning
Jun 11, 2026Reinforcement learning has rapidly emerged as a key component in the training of reasoning and coding models, yet it remains poorly understood from a mechanistic perspective. We study how and through what underlying processes capabilities are acquired or enhanced via reinforcement learning post-training. Our analysis, based on controlled math reasoning experiments with Qwen-2.5-1.5B, reveals two core mechanisms: strategy selection and strategy improvement. Our results highlight the role of SFT data and reinforcement learning data in activating these mechanisms, in particular showing how supervising the model on diverse reasoning strategies can enable strategy selection and how increasing difficulty in reinforcement learning data can enable strategy improvement. Taken together, our results provide mechanistic insight into RL training and suggest practical interventions to continue scaling reasoning capabilities.
Learning to Reason with Curriculum I: Provable Benefits of Autocurriculum
Mar 18, 2026Chain-of-thought reasoning, where language models expend additional computation by producing thinking tokens prior to final responses, has driven significant advances in model capabilities. However, training these reasoning models is extremely costly in terms of both data and compute, as it involves collecting long traces of reasoning behavior from humans or synthetic generators and further post-training the model via reinforcement learning. Are these costs fundamental, or can they be reduced through better algorithmic design? We show that autocurriculum, where the model uses its own performance to decide which problems to focus training on, provably improves upon standard training recipes for both supervised fine-tuning (SFT) and reinforcement learning (RL). For SFT, we show that autocurriculum requires exponentially fewer reasoning demonstrations than non-adaptive fine-tuning, by focusing teacher supervision on prompts where the current model struggles. For RL fine-tuning, autocurriculum decouples the computational cost from the quality of the reference model, reducing the latter to a burn-in cost that is nearly independent of the target accuracy. These improvements arise purely from adaptive data selection, drawing on classical techniques from boosting and learning from counterexamples, and requiring no assumption on the distribution or difficulty of prompts.
What One Cannot, Two Can: Two-Layer Transformers Provably Represent Induction Heads on Any-Order Markov Chains
Aug 10, 2025In-context learning (ICL) is a hallmark capability of transformers, through which trained models learn to adapt to new tasks by leveraging information from the input context. Prior work has shown that ICL emerges in transformers due to the presence of special circuits called induction heads. Given the equivalence between induction heads and conditional k-grams, a recent line of work modeling sequential inputs as Markov processes has revealed the fundamental impact of model depth on its ICL capabilities: while a two-layer transformer can efficiently represent a conditional 1-gram model, its single-layer counterpart cannot solve the task unless it is exponentially large. However, for higher order Markov sources, the best known constructions require at least three layers (each with a single attention head) - leaving open the question: can a two-layer single-head transformer represent any kth-order Markov process? In this paper, we precisely address this and theoretically show that a two-layer transformer with one head per layer can indeed represent any conditional k-gram. Thus, our result provides the tightest known characterization of the interplay between transformer depth and Markov order for ICL. Building on this, we further analyze the learning dynamics of our two-layer construction, focusing on a simplified variant for first-order Markov chains, illustrating how effective in-context representations emerge during training. Together, these results deepen our current understanding of transformer-based ICL and illustrate how even shallow architectures can surprisingly exhibit strong ICL capabilities on structured sequence modeling tasks.
The Space Complexity of Learning-Unlearning Algorithms
Jun 16, 2025We study the memory complexity of machine unlearning algorithms that provide strong data deletion guarantees to the users. Formally, consider an algorithm for a particular learning task that initially receives a training dataset. Then, after learning, it receives data deletion requests from a subset of users (of arbitrary size), and the goal of unlearning is to perform the task as if the learner never received the data of deleted users. In this paper, we ask how many bits of storage are needed to be able to delete certain training samples at a later time. We focus on the task of realizability testing, where the goal is to check whether the remaining training samples are realizable within a given hypothesis class \(\mathcal{H}\). Toward that end, we first provide a negative result showing that the VC dimension is not a characterization of the space complexity of unlearning. In particular, we provide a hypothesis class with constant VC dimension (and Littlestone dimension), but for which any unlearning algorithm for realizability testing needs to store \(\Omega(n)\)-bits, where \(n\) denotes the size of the initial training dataset. In fact, we provide a stronger separation by showing that for any hypothesis class \(\mathcal{H}\), the amount of information that the learner needs to store, so as to perform unlearning later, is lower bounded by the \textit{eluder dimension} of \(\mathcal{H}\), a combinatorial notion always larger than the VC dimension. We complement the lower bound with an upper bound in terms of the star number of the underlying hypothesis class, albeit in a stronger ticketed-memory model proposed by Ghazi et al. (2023). Since the star number for a hypothesis class is never larger than its Eluder dimension, our work highlights a fundamental separation between central and ticketed memory models for machine unlearning.
Computational Intractability of Strategizing against Online Learners
Mar 06, 2025Online learning algorithms are widely used in strategic multi-agent settings, including repeated auctions, contract design, and pricing competitions, where agents adapt their strategies over time. A key question in such environments is how an optimizing agent can best respond to a learning agent to improve its own long-term outcomes. While prior work has developed efficient algorithms for the optimizer in special cases - such as structured auction settings or contract design - no general efficient algorithm is known. In this paper, we establish a strong computational hardness result: unless $\mathsf{P} = \mathsf{NP}$, no polynomial-time optimizer can compute a near-optimal strategy against a learner using a standard no-regret algorithm, specifically Multiplicative Weights Update (MWU). Our result proves an $\Omega(T)$ hardness bound, significantly strengthening previous work that only showed an additive $\Theta(1)$ impossibility result. Furthermore, while the prior hardness result focused on learners using fictitious play - an algorithm that is not no-regret - we prove intractability for a widely used no-regret learning algorithm. This establishes a fundamental computational barrier to finding optimal strategies in general game-theoretic settings.
Scaling Test-Time Compute Without Verification or RL is Suboptimal
Feb 18, 2025



Despite substantial advances in scaling test-time compute, an ongoing debate in the community is how it should be scaled up to enable continued and efficient improvements with scaling. There are largely two approaches: first, distilling successful search or thinking traces; and second, using verification (e.g., 0/1 outcome rewards, reward models, or verifiers) to guide reinforcement learning (RL) and search algorithms. In this paper, we prove that finetuning LLMs with verifier-based (VB) methods based on RL or search is far superior to verifier-free (VF) approaches based on distilling or cloning search traces, given a fixed amount of compute/data budget. Further, we show that as we scale test-time compute (measured as the output token length) and training data, suboptimality of VF methods scales poorly compared to VB when the base pre-trained LLM presents a heterogeneous distribution over correct solution traces (e.g., different lengths, styles, etc.) and admits a non-sharp distribution over rewards on traces sampled from it. We formalize this condition using anti-concentration [Erd\H{o}s, 1945]. This implies a stronger result that VB methods scale better asymptotically, with the performance gap between VB and VF methods widening as test-time budget grows. We corroborate our theory empirically on both didactic and math reasoning problems with 3/8/32B-sized pre-trained LLMs, where we find verification is crucial for scaling test-time compute.
Transformers on Markov Data: Constant Depth Suffices
Jul 25, 2024



Attention-based transformers have been remarkably successful at modeling generative processes across various domains and modalities. In this paper, we study the behavior of transformers on data drawn from \kth Markov processes, where the conditional distribution of the next symbol in a sequence depends on the previous $k$ symbols observed. We observe a surprising phenomenon empirically which contradicts previous findings: when trained for sufficiently long, a transformer with a fixed depth and $1$ head per layer is able to achieve low test loss on sequences drawn from \kth Markov sources, even as $k$ grows. Furthermore, this low test loss is achieved by the transformer's ability to represent and learn the in-context conditional empirical distribution. On the theoretical side, our main result is that a transformer with a single head and three layers can represent the in-context conditional empirical distribution for \kth Markov sources, concurring with our empirical observations. Along the way, we prove that \textit{attention-only} transformers with $O(\log_2(k))$ layers can represent the in-context conditional empirical distribution by composing induction heads to track the previous $k$ symbols in the sequence. These results provide more insight into our current understanding of the mechanisms by which transformers learn to capture context, by understanding their behavior on Markov sources.
Toward a Theory of Tokenization in LLMs
Apr 12, 2024



While there has been a large body of research attempting to circumvent tokenization for language modeling (Clark et al., 2022; Xue et al., 2022), the current consensus is that it is a necessary initial step for designing state-of-the-art performant language models. In this paper, we investigate tokenization from a theoretical point of view by studying the behavior of transformers on simple data generating processes. When trained on data drawn from certain simple $k^{\text{th}}$-order Markov processes for $k > 1$, transformers exhibit a surprising phenomenon - in the absence of tokenization, they empirically fail to learn the right distribution and predict characters according to a unigram model (Makkuva et al., 2024). With the addition of tokenization, however, we empirically observe that transformers break through this barrier and are able to model the probabilities of sequences drawn from the source near-optimally, achieving small cross-entropy loss. With this observation as starting point, we study the end-to-end cross-entropy loss achieved by transformers with and without tokenization. With the appropriate tokenization, we show that even the simplest unigram models (over tokens) learnt by transformers are able to model the probability of sequences drawn from $k^{\text{th}}$-order Markov sources near optimally. Our analysis provides a justification for the use of tokenization in practice through studying the behavior of transformers on Markovian data.
Greedy Pruning with Group Lasso Provably Generalizes for Matrix Sensing and Neural Networks with Quadratic Activations
Mar 20, 2023Pruning schemes have been widely used in practice to reduce the complexity of trained models with a massive number of parameters. Several practical studies have shown that pruning an overparameterized model and fine-tuning generalizes well to new samples. Although the above pipeline, which we refer to as pruning + fine-tuning, has been extremely successful in lowering the complexity of trained models, there is very little known about the theory behind this success. In this paper we address this issue by investigating the pruning + fine-tuning framework on the overparameterized matrix sensing problem, with the ground truth denoted $U_\star \in \mathbb{R}^{d \times r}$ and the overparameterized model $U \in \mathbb{R}^{d \times k}$ with $k \gg r$. We study the approximate local minima of the empirical mean square error, augmented with a smooth version of a group Lasso regularizer, $\sum_{i=1}^k \| U e_i \|_2$ and show that pruning the low $\ell_2$-norm columns results in a solution $U_{\text{prune}}$ which has the minimum number of columns $r$, yet is close to the ground truth in training loss. Initializing the subsequent fine-tuning phase from $U_{\text{prune}}$, the resulting solution converges linearly to a generalization error of $O(\sqrt{rd/n})$ ignoring lower order terms, which is statistically optimal. While our analysis provides insights into the role of regularization in pruning, we also show that running gradient descent in the absence of regularization results in models which {are not suitable for greedy pruning}, i.e., many columns could have their $\ell_2$ norm comparable to that of the maximum. Lastly, we extend our results for the training and pruning of two-layer neural networks with quadratic activation functions. Our results provide the first rigorous insights on why greedy pruning + fine-tuning leads to smaller models which also generalize well.
Beyond UCB: Statistical Complexity and Optimal Algorithms for Non-linear Ridge Bandits
Feb 12, 2023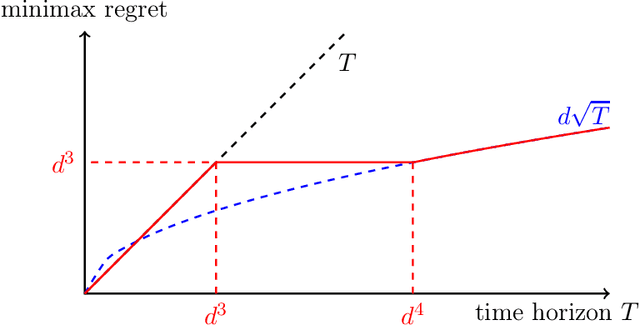
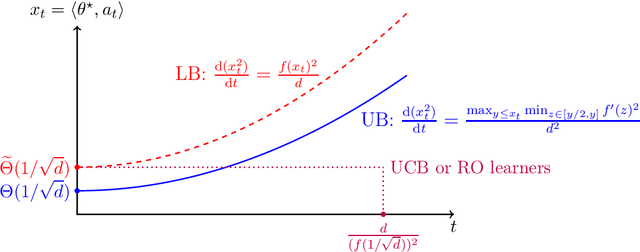
We consider the sequential decision-making problem where the mean outcome is a non-linear function of the chosen action. Compared with the linear model, two curious phenomena arise in non-linear models: first, in addition to the "learning phase" with a standard parametric rate for estimation or regret, there is an "burn-in period" with a fixed cost determined by the non-linear function; second, achieving the smallest burn-in cost requires new exploration algorithms. For a special family of non-linear functions named ridge functions in the literature, we derive upper and lower bounds on the optimal burn-in cost, and in addition, on the entire learning trajectory during the burn-in period via differential equations. In particular, a two-stage algorithm that first finds a good initial action and then treats the problem as locally linear is statistically optimal. In contrast, several classical algorithms, such as UCB and algorithms relying on regression oracles, are provably suboptimal.