 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding the Capabilities of Reinforcement Learning via Text Feedback
Feb 02, 2026The success of RL for LLM post-training stems from an unreasonably uninformative source: a single bit of information per rollout as binary reward or preference label. At the other extreme, distillation offers dense supervision but requires demonstrations, which are costly and difficult to scale. We study text feedback as an intermediate signal: richer than scalar rewards, yet cheaper than complete demonstrations. Textual feedback is a natural mode of human interaction and is already abundant in many real-world settings, where users, annotators, and automated judges routinely critique LLM outputs. Towards leveraging text feedback at scale, we formalize a multi-turn RL setup, RL from Text Feedback (RLTF), where text feedback is available during training but not at inference. Therefore, models must learn to internalize the feedback in order to improve their test-time single-turn performance. To do this, we propose two methods: Self Distillation (RLTF-SD), which trains the single-turn policy to match its own feedback-conditioned second-turn generations; and Feedback Modeling (RLTF-FM), which predicts the feedback as an auxiliary objective. We provide theoretical analysis on both methods, and empirically evaluate on reasoning puzzles, competition math, and creative writing tasks. Our results show that both methods consistently outperform strong baselines across benchmarks, highlighting the potential of RL with an additional source of rich supervision at scale.
All Roads Lead to Likelihood: The Value of Reinforcement Learning in Fine-Tuning
Mar 03, 2025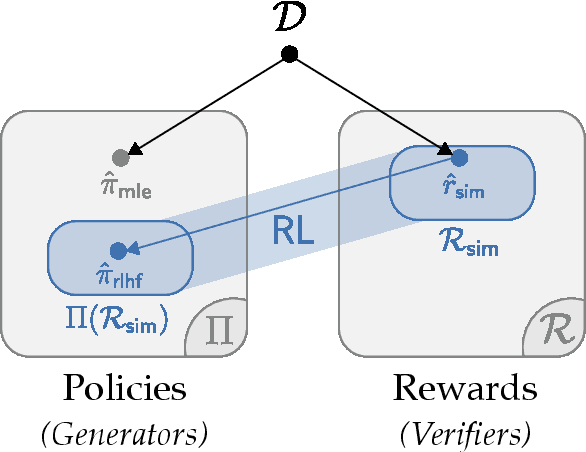

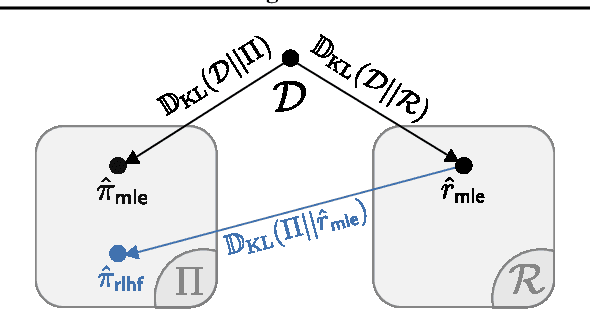

From a first-principles perspective, it may seem odd that the strongest results in foundation model fine-tuning (FT) are achieved via a relatively complex, two-stage training procedure. Specifically, one first trains a reward model (RM) on some dataset (e.g. human preferences) before using it to provide online feedback as part of a downstream reinforcement learning (RL) procedure, rather than directly optimizing the policy parameters on the dataset via offline maximum likelihood estimation. In fact, from an information-theoretic perspective, we can only lose information via passing through a reward model and cannot create any new information via on-policy sampling. To explain this discrepancy, we scrutinize several hypotheses on the value of RL in FT through both theoretical and empirical lenses. Of the hypotheses considered, we find the most support for the explanation that on problems with a generation-verification gap, the combination of the ease of learning the relatively simple RM (verifier) from the preference data, coupled with the ability of the downstream RL procedure to then filter its search space to the subset of policies (generators) that are optimal for relatively simple verifiers is what leads to the superior performance of online FT.
Hybrid Reinforcement Learning from Offline Observation Alone
Jun 11, 2024
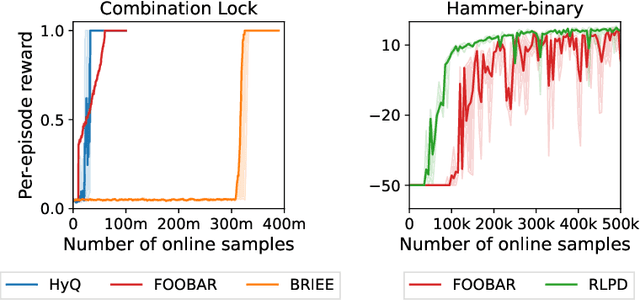

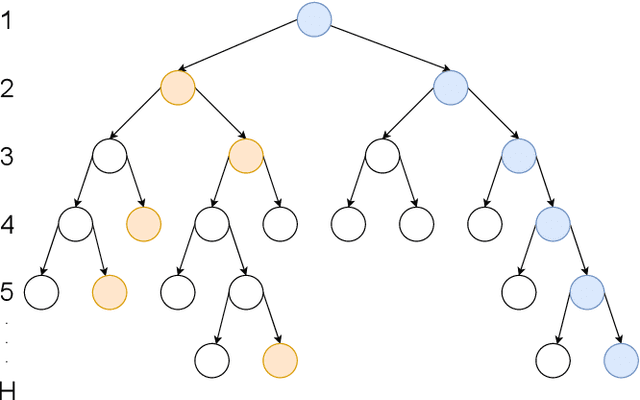
We consider the hybrid reinforcement learning setting where the agent has access to both offline data and online interactive access. While Reinforcement Learning (RL) research typically assumes offline data contains complete action, reward and transition information, datasets with only state information (also known as observation-only datasets) are more general, abundant and practical. This motivates our study of the hybrid RL with observation-only offline dataset framework. While the task of competing with the best policy "covered" by the offline data can be solved if a reset model of the environment is provided (i.e., one that can be reset to any state), we show evidence of hardness when only given the weaker trace model (i.e., one can only reset to the initial states and must produce full traces through the environment), without further assumption of admissibility of the offline data. Under the admissibility assumptions -- that the offline data could actually be produced by the policy class we consider -- we propose the first algorithm in the trace model setting that provably matches the performance of algorithms that leverage a reset model. We also perform proof-of-concept experiments that suggest the effectiveness of our algorithm in practice.
Understanding Preference Fine-Tuning Through the Lens of Coverage
Jun 03, 2024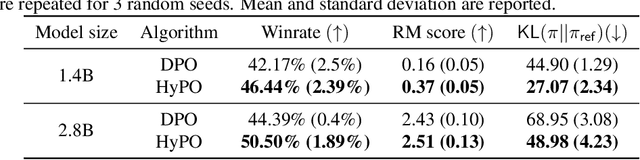
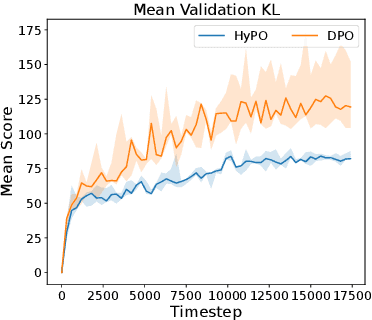

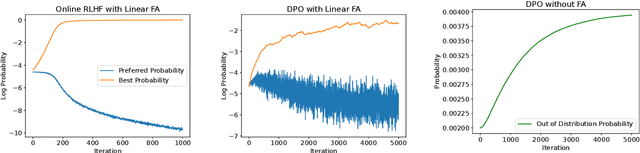
Learning from human preference data has emerged as the dominant paradigm for fine-tuning large language models (LLMs). The two most common families of techniques -- online reinforcement learning (RL) such as Proximal Policy Optimization (PPO) and offline contrastive methods such as Direct Preference Optimization (DPO) -- were positioned as equivalent in prior work due to the fact that both have to start from the same offline preference dataset. To further expand our theoretical understanding of the similarities and differences between online and offline techniques for preference fine-tuning, we conduct a rigorous analysis through the lens of dataset coverage, a concept that captures how the training data covers the test distribution and is widely used in RL. We prove that a global coverage condition is both necessary and sufficient for offline contrastive methods to converge to the optimal policy, but a weaker partial coverage condition suffices for online RL methods. This separation provides one explanation of why online RL methods can perform better than offline methods, especially when the offline preference data is not diverse enough. Finally, motivated by our preceding theoretical observations, we derive a hybrid preference optimization (HyPO) algorithm that uses offline data for contrastive-based preference optimization and online data for KL regularization. Theoretically and empirically, we demonstrate that HyPO is more performant than its pure offline counterpart DPO, while still preserving its computation and memory efficiency.
REBEL: Reinforcement Learning via Regressing Relative Rewards
Apr 25, 2024While originally developed for continuous control problems, Proximal Policy Optimization (PPO) has emerged as the work-horse of a variety of reinforcement learning (RL) applications including the fine-tuning of generative models. Unfortunately, PPO requires multiple heuristics to enable stable convergence (e.g. value networks, clipping) and is notorious for its sensitivity to the precise implementation of these components. In response, we take a step back and ask what a minimalist RL algorithm for the era of generative models would look like. We propose REBEL, an algorithm that cleanly reduces the problem of policy optimization to regressing the relative rewards via a direct policy parameterization between two completions to a prompt, enabling strikingly lightweight implementation. In theory, we prove that fundamental RL algorithms like Natural Policy Gradient can be seen as variants of REBEL, which allows us to match the strongest known theoretical guarantees in terms of convergence and sample complexity in the RL literature. REBEL can also cleanly incorporate offline data and handle the intransitive preferences we frequently see in practice. Empirically, we find that REBEL provides a unified approach to language modeling and image generation with stronger or similar performance as PPO and DPO, all while being simpler to implement and more computationally tractable than PPO.
Hybrid Inverse Reinforcement Learning
Feb 13, 2024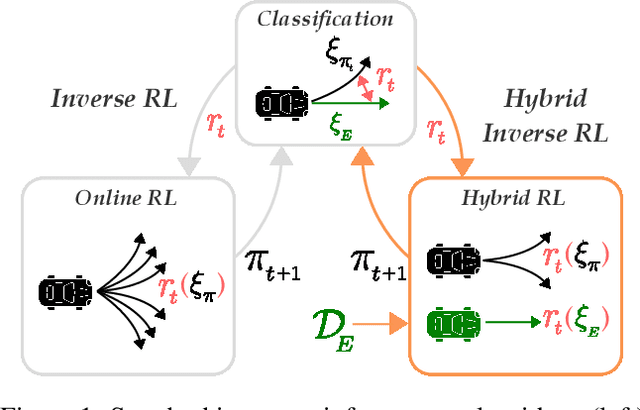


The inverse reinforcement learning approach to imitation learning is a double-edged sword. On the one hand, it can enable learning from a smaller number of expert demonstrations with more robustness to error compounding than behavioral cloning approaches. On the other hand, it requires that the learner repeatedly solve a computationally expensive reinforcement learning (RL) problem. Often, much of this computation is wasted searching over policies very dissimilar to the expert's. In this work, we propose using hybrid RL -- training on a mixture of online and expert data -- to curtail unnecessary exploration. Intuitively, the expert data focuses the learner on good states during training, which reduces the amount of exploration required to compute a strong policy. Notably, such an approach doesn't need the ability to reset the learner to arbitrary states in the environment, a requirement of prior work in efficient inverse RL. More formally, we derive a reduction from inverse RL to expert-competitive RL (rather than globally optimal RL) that allows us to dramatically reduce interaction during the inner policy search loop while maintaining the benefits of the IRL approach. This allows us to derive both model-free and model-based hybrid inverse RL algorithms with strong policy performance guarantees. Empirically, we find that our approaches are significantly more sample efficient than standard inverse RL and several other baselines on a suite of continuous control tasks.
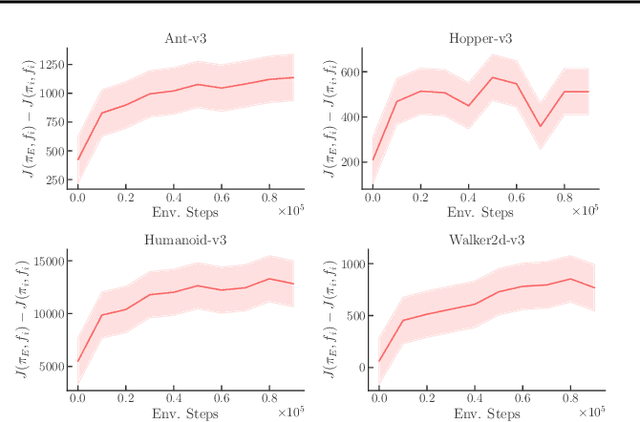
The Virtues of Pessimism in Inverse Reinforcement Learning
Feb 08, 2024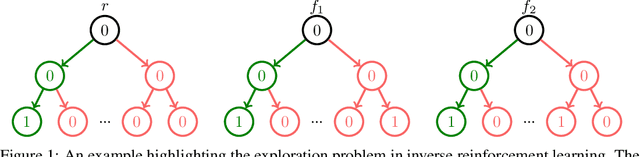

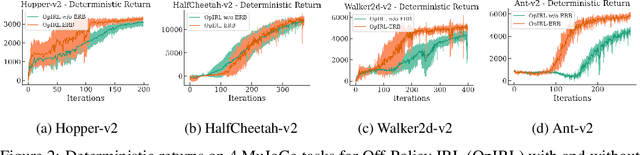
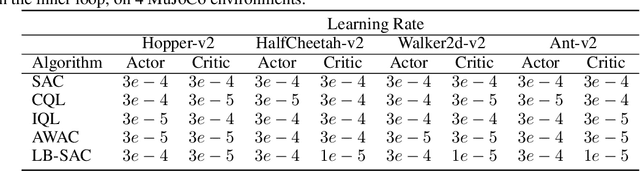
Inverse Reinforcement Learning (IRL) is a powerful framework for learning complex behaviors from expert demonstrations. However, it traditionally requires repeatedly solving a computationally expensive reinforcement learning (RL) problem in its inner loop. It is desirable to reduce the exploration burden by leveraging expert demonstrations in the inner-loop RL. As an example, recent work resets the learner to expert states in order to inform the learner of high-reward expert states. However, such an approach is infeasible in the real world. In this work, we consider an alternative approach to speeding up the RL subroutine in IRL: \emph{pessimism}, i.e., staying close to the expert's data distribution, instantiated via the use of offline RL algorithms. We formalize a connection between offline RL and IRL, enabling us to use an arbitrary offline RL algorithm to improve the sample efficiency of IRL. We validate our theory experimentally by demonstrating a strong correlation between the efficacy of an offline RL algorithm and how well it works as part of an IRL procedure. By using a strong offline RL algorithm as part of an IRL procedure, we are able to find policies that match expert performance significantly more efficiently than the prior art.
Inverse Reinforcement Learning without Reinforcement Learning
Mar 26, 2023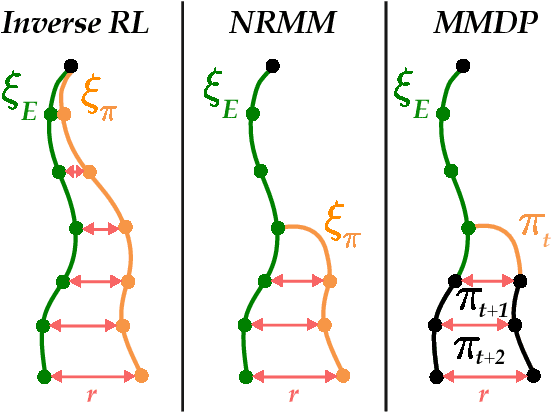
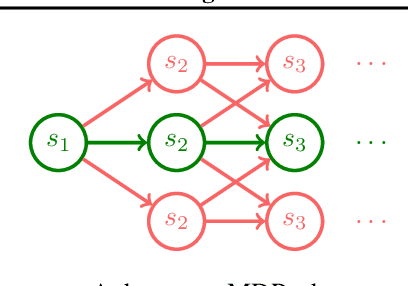
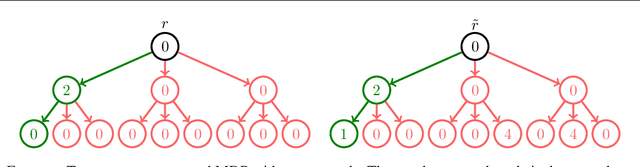
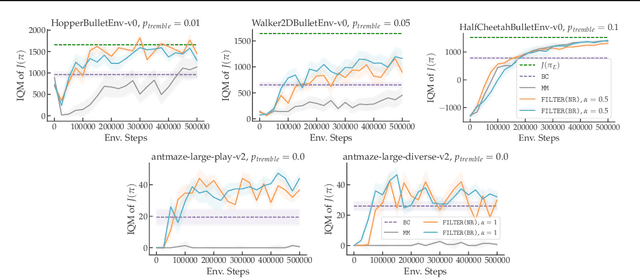
Inverse Reinforcement Learning (IRL) is a powerful set of techniques for imitation learning that aims to learn a reward function that rationalizes expert demonstrations. Unfortunately, traditional IRL methods suffer from a computational weakness: they require repeatedly solving a hard reinforcement learning (RL) problem as a subroutine. This is counter-intuitive from the viewpoint of reductions: we have reduced the easier problem of imitation learning to repeatedly solving the harder problem of RL. Another thread of work has proved that access to the side-information of the distribution of states where a strong policy spends time can dramatically reduce the sample and computational complexities of solving an RL problem. In this work, we demonstrate for the first time a more informed imitation learning reduction where we utilize the state distribution of the expert to alleviate the global exploration component of the RL subroutine, providing an exponential speedup in theory. In practice, we find that we are able to significantly speed up the prior art on continuous control tasks.
The Virtues of Laziness in Model-based RL: A Unified Objective and Algorithms
Mar 01, 2023We propose a novel approach to addressing two fundamental challenges in Model-based Reinforcement Learning (MBRL): the computational expense of repeatedly finding a good policy in the learned model, and the objective mismatch between model fitting and policy computation. Our "lazy" method leverages a novel unified objective, Performance Difference via Advantage in Model, to capture the performance difference between the learned policy and expert policy under the true dynamics. This objective demonstrates that optimizing the expected policy advantage in the learned model under an exploration distribution is sufficient for policy computation, resulting in a significant boost in computational efficiency compared to traditional planning methods. Additionally, the unified objective uses a value moment matching term for model fitting, which is aligned with the model's usage during policy computation. We present two no-regret algorithms to optimize the proposed objective, and demonstrate their statistical and computational gains compared to existing MBRL methods through simulated benchmarks.
Hybrid RL: Using Both Offline and Online Data Can Make RL Efficient
Oct 13, 2022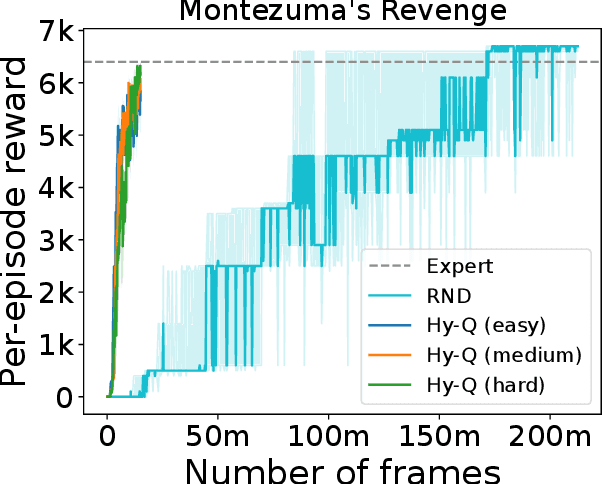
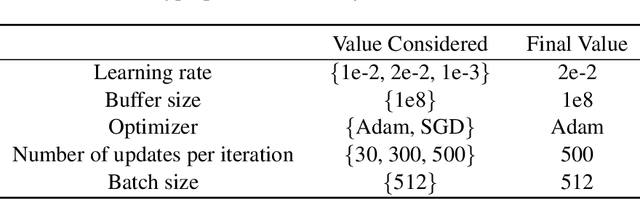
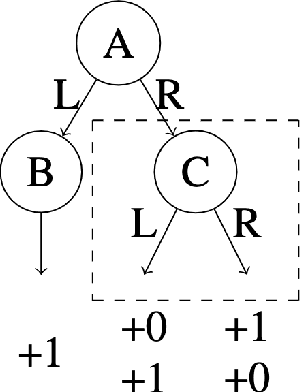
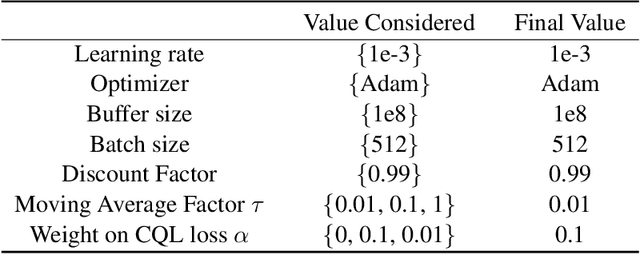
We consider a hybrid reinforcement learning setting (Hybrid RL), in which an agent has access to an offline dataset and the ability to collect experience via real-world online interaction. The framework mitigates the challenges that arise in both pure offline and online RL settings, allowing for the design of simple and highly effective algorithms, in both theory and practice. We demonstrate these advantages by adapting the classical Q learning/iteration algorithm to the hybrid setting, which we call Hybrid Q-Learning or Hy-Q. In our theoretical results, we prove that the algorithm is both computationally and statistically efficient whenever the offline dataset supports a high-quality policy and the environment has bounded bilinear rank. Notably, we require no assumptions on the coverage provided by the initial distribution, in contrast with guarantees for policy gradient/iteration methods. In our experimental results, we show that Hy-Q with neural network function approximation outperforms state-of-the-art online, offline, and hybrid RL baselines on challenging benchmarks, including Montezuma's Revenge.