 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Reinforcement Learning from Offline Observation Alone
Paper and Code
Jun 11, 2024
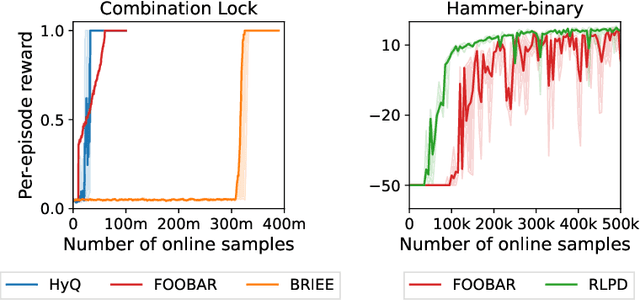

We consider the hybrid reinforcement learning setting where the agent has access to both offline data and online interactive access. While Reinforcement Learning (RL) research typically assumes offline data contains complete action, reward and transition information, datasets with only state information (also known as observation-only datasets) are more general, abundant and practical. This motivates our study of the hybrid RL with observation-only offline dataset framework. While the task of competing with the best policy "covered" by the offline data can be solved if a reset model of the environment is provided (i.e., one that can be reset to any state), we show evidence of hardness when only given the weaker trace model (i.e., one can only reset to the initial states and must produce full traces through the environment), without further assumption of admissibility of the offline data. Under the admissibility assumptions -- that the offline data could actually be produced by the policy class we consider -- we propose the first algorithm in the trace model setting that provably matches the performance of algorithms that leverage a reset model. We also perform proof-of-concept experiments that suggest the effectiveness of our algorithm in practice.