 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Virtues of Laziness in Model-based RL: A Unified Objective and Algorithms
Mar 01, 2023

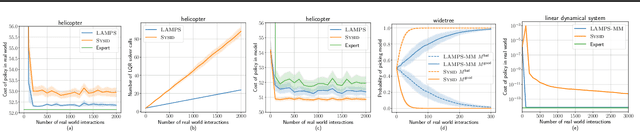

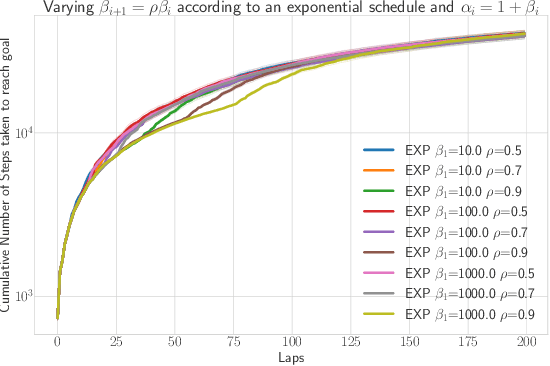
We propose a novel approach to addressing two fundamental challenges in Model-based Reinforcement Learning (MBRL): the computational expense of repeatedly finding a good policy in the learned model, and the objective mismatch between model fitting and policy computation. Our "lazy" method leverages a novel unified objective, Performance Difference via Advantage in Model, to capture the performance difference between the learned policy and expert policy under the true dynamics. This objective demonstrates that optimizing the expected policy advantage in the learned model under an exploration distribution is sufficient for policy computation, resulting in a significant boost in computational efficiency compared to traditional planning methods. Additionally, the unified objective uses a value moment matching term for model fitting, which is aligned with the model's usage during policy computation. We present two no-regret algorithms to optimize the proposed objective, and demonstrate their statistical and computational gains compared to existing MBRL methods through simulated benchmarks.
On the Effectiveness of Iterative Learning Control
Nov 27, 2021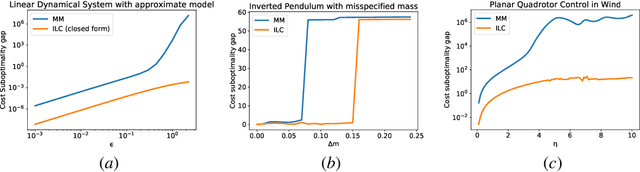
Iterative learning control (ILC) is a powerful technique for high performance tracking in the presence of modeling errors for optimal control applications. There is extensive prior work showing its empirical effectiveness in applications such as chemical reactors, industrial robots and quadcopters. However, there is little prior theoretical work that explains the effectiveness of ILC even in the presence of large modeling errors, where optimal control methods using the misspecified model (MM) often perform poorly. Our work presents such a theoretical study of the performance of both ILC and MM on Linear Quadratic Regulator (LQR) problems with unknown transition dynamics. We show that the suboptimality gap, as measured with respect to the optimal LQR controller, for ILC is lower than that for MM by higher order terms that become significant in the regime of high modeling errors. A key part of our analysis is the perturbation bounds for the discrete Ricatti equation in the finite horizon setting, where the solution is not a fixed point and requires tracking the error using recursive bounds. We back our theoretical findings with empirical experiments on a toy linear dynamical system with an approximate model, a nonlinear inverted pendulum system with misspecified mass, and a nonlinear planar quadrotor system in the presence of wind. Experiments show that ILC outperforms MM significantly, in terms of the cost of computed trajectories, when modeling errors are high.
Improved Soft Duplicate Detection in Search-Based Motion Planning
Sep 25, 2021



Search-based techniques have shown great success in motion planning problems such as robotic navigation by discretizing the state space and precomputing motion primitives. However in domains with complex dynamic constraints, constructing motion primitives in a discretized state space is non-trivial. This requires operating in continuous space which can be challenging for search-based planners as they can get stuck in local minima regions. Previous work on planning in continuous spaces introduced soft duplicate detection which requires search to compute the duplicity of a state with respect to previously seen states to avoid exploring states that are likely to be duplicates, especially in local minima regions. They propose a simple metric utilizing the euclidean distance between states, and proximity to obstacles to compute the duplicity. In this paper, we improve upon this metric by introducing a kinodynamically informed metric, subtree overlap, between two states as the similarity between their successors that can be reached within a fixed time horizon using kinodynamic motion primitives. This captures the intuition that, due to robot dynamics, duplicate states can be far in euclidean distance and result in very similar successor states, while non-duplicate states can be close and result in widely different successors.
CMAX++ : Leveraging Experience in Planning and Execution using Inaccurate Models
Oct 15, 2020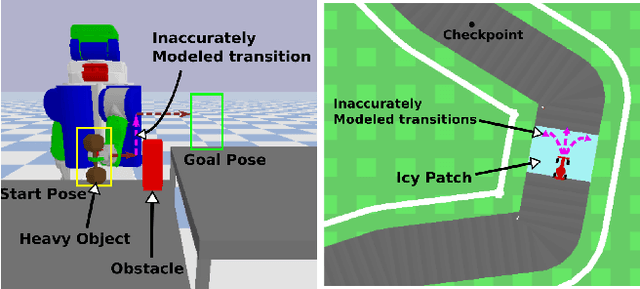

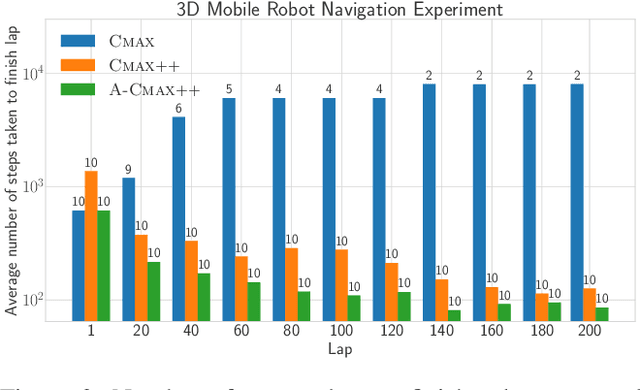
Given access to accurate dynamical models, modern planning approaches are effective in computing feasible and optimal plans for repetitive robotic tasks. However, it is difficult to model the true dynamics of the real world before execution, especially for tasks requiring interactions with objects whose parameters are unknown. A recent planning approach, CMAX, tackles this problem by adapting the planner online during execution to bias the resulting plans away from inaccurately modeled regions. CMAX, while being provably guaranteed to reach the goal, requires strong assumptions on the accuracy of the model used for planning and fails to improve the quality of the solution over repetitions of the same task. In this paper we propose CMAX++, an approach that leverages real-world experience to improve the quality of resulting plans over successive repetitions of a robotic task. CMAX++ achieves this by integrating model-free learning using acquired experience with model-based planning using the potentially inaccurate model. We provide provable guarantees on the completeness and asymptotic convergence of CMAX++ to the optimal path cost as the number of repetitions increases. CMAX++ is also shown to outperform baselines in simulated robotic tasks including 3D mobile robot navigation where the track friction is incorrectly modeled, and a 7D pick-and-place task where the mass of the object is unknown leading to discrepancy between true and modeled dynamics.
TRON: A Fast Solver for Trajectory Optimization with Non-Smooth Cost Functions
Apr 01, 2020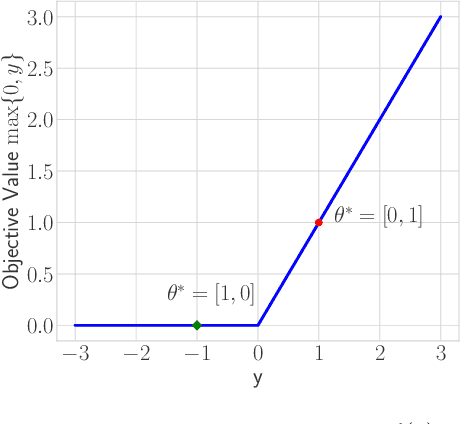
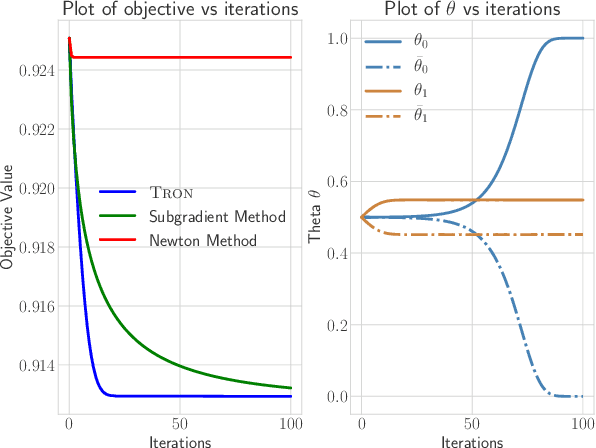
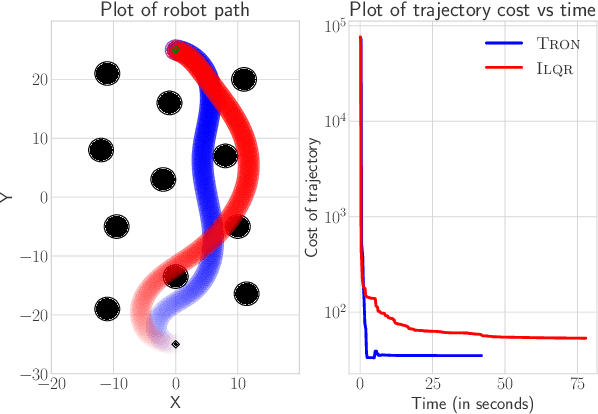
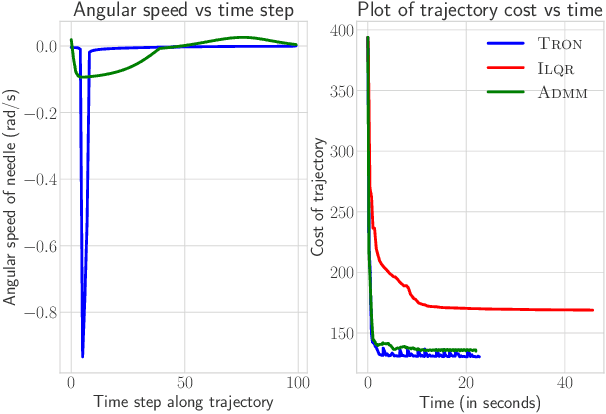
Trajectory optimization is an important tool for control and planning of complex, underactuated robots, and has shown impressive results in real world robotic tasks. However, in applications where the cost function to be optimized is non-smooth, modern trajectory optimization methods have extremely slow convergence. In this work, we present TRON, an iterative solver that can be used for efficient trajectory optimization in applications with non-smooth cost functions that are composed of smooth components. TRON achieves this by exploiting the structure of the objective to adaptively smooth the cost function, resulting in a sequence of objectives that can be efficiently optimized. TRON is provably guaranteed to converge to the global optimum of the non-smooth convex cost function when the dynamics are linear, and to a stationary point when the dynamics are nonlinear. Empirically, we show that TRON has faster convergence and lower final costs when compared to other trajectory optimization methods on a range of simulated tasks including collision-free motion planning for a mobile robot, sparse optimal control for surgical needle, and a satellite rendezvous problem.
Exploration in Action Space
Mar 31, 2020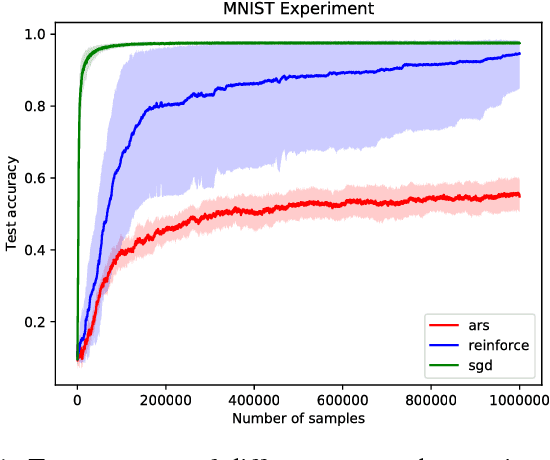

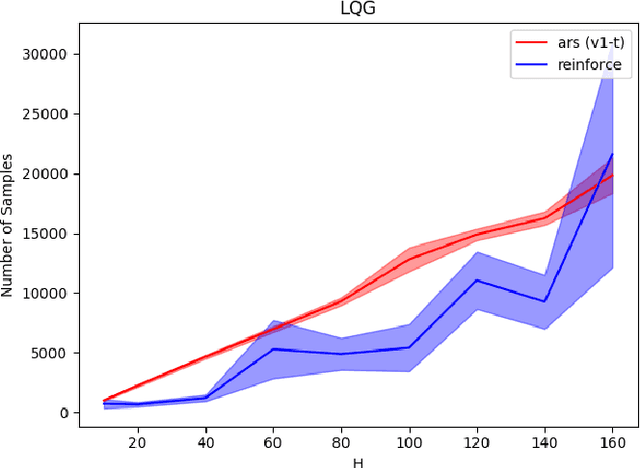
Parameter space exploration methods with black-box optimization have recently been shown to outperform state-of-the-art approaches in continuous control reinforcement learning domains. In this paper, we examine reasons why these methods work better and the situations in which they are worse than traditional action space exploration methods. Through a simple theoretical analysis, we show that when the parametric complexity required to solve the reinforcement learning problem is greater than the product of action space dimensionality and horizon length, exploration in action space is preferred. This is also shown empirically by comparing simple exploration methods on several toy problems.
Planning and Execution using Inaccurate Models with Provable Guarantees
Mar 15, 2020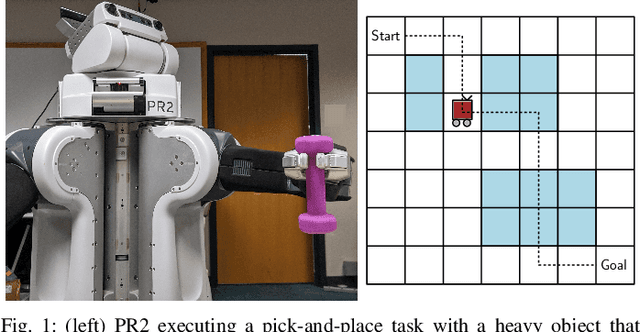
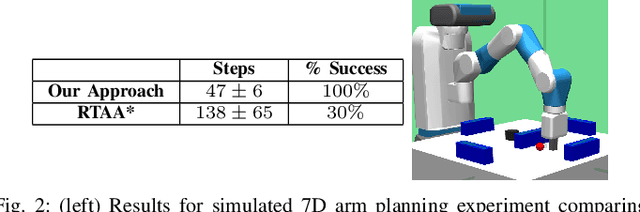


Models used in modern planning problems to simulate outcomes of real world action executions are becoming increasingly complex, ranging from simulators that do physics-based reasoning to precomputed analytical motion primitives. However, robots operating in the real world often face situations not modeled by these models before execution. This imperfect modeling can lead to highly suboptimal or even incomplete behavior during execution. In this paper, we propose an approach for interleaving planning and execution that adapts online using real world execution and accounts for any discrepancies in dynamics during planning, without requiring updates to the dynamics of the model. This is achieved by biasing the planner away from transitions whose dynamics are discovered to be inaccurately modeled, thereby leading to robot behavior that tries to complete the task despite having an inaccurate model. We provide provable guarantees on the completeness and efficiency of the proposed planning and execution framework under specific assumptions on the model, for both small and large state spaces. Our approach is shown to be efficient empirically in simulated robotic tasks including 4D planar pushing, and in real robotic experiments using PR2 involving a 3D pick-and-place task where the mass of the object is incorrectly modeled, and a 7D arm planning task where one of the joints is not operational leading to discrepancy in dynamics. Video can be found at https://youtu.be/eQmAeWIhjO8
Task-Informed Fidelity Management for Speeding Up Robotics Simulation
Oct 27, 2019



Simulators are an important tool in robotics that is used to develop robot software and generate synthetic data for machine learning algorithms. Faster simulation can result in better software validation and larger amounts of data. Previous efforts for speeding up simulators have been performed at the level of simulator building blocks, and robot systems. Our key insight, motivating this work, is that further speedups can be obtained at the level of the robot task. Building on the observation that not all parts of a scene need to be simulated in high fidelity at all times, our approach is to toggle between high- and low-fidelity states for scene objects in a task-informed manner. Our contribution is a framework for speeding up robot simulation by exploiting task knowledge. The framework is agnostic to the underlying simulator, and preserves simulation fidelity. As a case study, we consider a complex material-handling task. For the associated simulation, which contains many of the characteristics that make robot simulation slow, we achieve a speedup that can be up to three times faster than high fidelity without compromising on the quality of the results. We also demonstrate that faster simulation allows us to train better policies for performing the task at hand in a short period of time. A video summarizing our contributions can be found at https://youtu.be/PEzypDyqc3o .
Planning, Learning and Reasoning Framework for Robot Truck Unloading
Oct 21, 2019

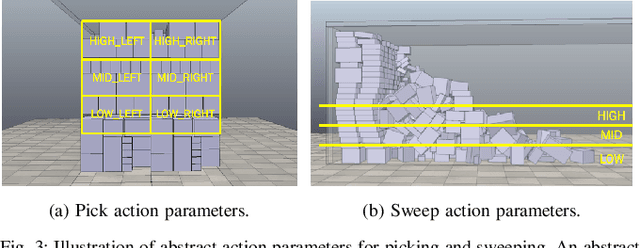

We consider the task of autonomously unloading boxes from trucks using an industrial manipulator robot. There are multiple challenges that arise: (1) real-time motion planning for a complex robotic system carrying two articulated mechanisms, an arm and a scooper, (2) decision-making in terms of what action to execute next given imperfect information about boxes such as their masses, (3) accounting for the sequential nature of the problem where current actions affect future state of the boxes, and (4) real-time execution that interleaves high-level decision-making with lower level motion planning. In this work, we propose a planning, learning, and reasoning framework to tackle these challenges, and describe its components including motion planning, belief space planning for offline learning, online decision-making based on offline learning, and an execution module to combine decision-making with motion planning. We analyze the performance of the framework on real-world scenarios. In particular, motion planning and execution modules are evaluated in simulation and on a real robot, while offline learning and online decision-making are evaluated in simulated real-world scenarios.
Provably Efficient Imitation Learning from Observation Alone
Jun 11, 2019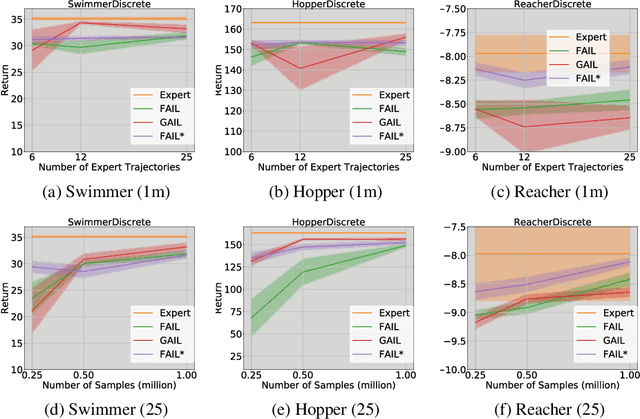
We study Imitation Learning (IL) from Observations alone (ILFO) in large-scale MDPs. While most IL algorithms rely on an expert to directly provide actions to the learner, in this setting the expert only supplies sequences of observations. We design a new model-free algorithm for ILFO, Forward Adversarial Imitation Learning (FAIL), which learns a sequence of time-dependent policies by minimizing an Integral Probability Metric between the observation distributions of the expert policy and the learner. FAIL is the first provably efficient algorithm in ILFO setting, which learns a near-optimal policy with a number of samples that is polynomial in all relevant parameters but independent of the number of unique observations. The resulting theory extends the domain of provably sample efficient learning algorithms beyond existing results, which typically only consider tabular reinforcement learning settings or settings that require access to a near-optimal reset distribution. We also investigate the extension of FAIL in a model-based setting. Finally we demonstrate the efficacy of FAIL on multiple OpenAI Gym control tasks.