 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Evaluation Gap: Standardized Benchmarks for Multi-Objective Search
Mar 25, 2026Empirical evaluation in multi-objective search (MOS) has historically suffered from fragmentation, relying on heterogeneous problem instances with incompatible objective definitions that make cross-study comparisons difficult. This standardization gap is further exacerbated by the realization that DIMACS road networks, a historical default benchmark for the field, exhibit highly correlated objectives that fail to capture diverse Pareto-front structures. To address this, we introduce the first comprehensive, standardized benchmark suite for exact and approximate MOS. Our suite spans four structurally diverse domains: real-world road networks, structured synthetic graphs, game-based grid environments, and high-dimensional robotic motion-planning roadmaps. By providing fixed graph instances, standardized start-goal queries, and both exact and approximate reference Pareto-optimal solution sets, this suite captures a full spectrum of objective interactions: from strongly correlated to strictly independent. Ultimately, this benchmark provides a common foundation to ensure future MOS evaluations are robust, reproducible, and structurally comprehensive.
Scalable Inspection Planning via Flow-based Mixed Integer Linear Programming
Mar 17, 2026Inspection planning is concerned with computing the shortest robot path to inspect a given set of points of interest (POIs) using the robot's sensors. This problem arises in a wide range of applications from manufacturing to medical robotics. To alleviate the problem's complexity, recent methods rely on sampling-based methods to obtain a more manageable (discrete) graph inspection planning (GIP) problem. Unfortunately, GIP still remains highly difficult to solve at scale as it requires simultaneously satisfying POI-coverage and path-connectivity constraints, giving rise to a challenging optimization problem, particularly at scales encountered in real-world scenarios. In this work, we present highly scalable Mixed Integer Linear Programming (MILP) solutions for GIP that significantly advance the state-of-the-art in both runtime and solution quality. Our key insight is a reformulation of the problem's core constraints as a network flow, which enables effective MILP models and a specialized Branch-and-Cut solver that exploits the combinatorial structure of flows. We evaluate our approach on medical and infrastructure benchmarks alongside large-scale synthetic instances. Across all scenarios, our method produces substantially tighter lower bounds than existing formulations, reducing optimality gaps by 30-50% on large instances. Furthermore, our solver demonstrates unprecedented scalability: it provides non-trivial solutions for problems with up to 15,000 vertices and thousands of POIs, where prior state-of-the-art methods typically exhaust memory or fail to provide any meaningful optimality guarantees.
DigiArm: An Anthropomorphic 3D-Printed Prosthetic Hand with Enhanced Dexterity for Typing Tasks
Feb 26, 2026Despite recent advancements, existing prosthetic limbs are unable to replicate the dexterity and intuitive control of the human hand. Current control systems for prosthetic hands are often limited to grasping, and commercial prosthetic hands lack the precision needed for dexterous manipulation or applications that require fine finger motions. Thus, there is a critical need for accessible and replicable prosthetic designs that enable individuals to interact with electronic devices and perform precise finger pressing, such as keyboard typing or piano playing, while preserving current prosthetic capabilities. This paper presents a low-cost, lightweight, 3D-printed robotic prosthetic hand, specifically engineered for enhanced dexterity with electronic devices such as a computer keyboard or piano, as well as general object manipulation. The robotic hand features a mechanism to adjust finger abduction/adduction spacing, a 2-D wrist with the inclusion of controlled ulnar/radial deviation optimized for typing, and control of independent finger pressing. We conducted a study to demonstrate how participants can use the robotic hand to perform keyboard typing and piano playing in real time, with different levels of finger and wrist motion. This supports the notion that our proposed design can allow for the execution of key typing motions more effectively than before, aiming to enhance the functionality of prosthetic hands.
Joint Task Assistance Planning via Nested Branch and Bound (Extended Version)
Feb 15, 2026We introduce and study the Joint Task Assistance Planning problem which generalizes prior work on optimizing assistance in robotic collaboration. In this setting, two robots operate over predefined roadmaps, each represented as a graph corresponding to its configuration space. One robot, the task robot, must execute a timed mission, while the other, the assistance robot, provides sensor-based support that depends on their spatial relationship. The objective is to compute a path for both robots that maximizes the total duration of assistance given. Solving this problem is challenging due to the combinatorial explosion of possible path combinations together with the temporal nature of the problem (time needs to be accounted for as well). To address this, we propose a nested branch-and-bound framework that efficiently explores the space of robot paths in a hierarchical manner. We empirically evaluate our algorithm and demonstrate a speedup of up to two orders of magnitude when compared to a baseline approach.
Effective Game-Theoretic Motion Planning via Nested Search
Nov 11, 2025To facilitate effective, safe deployment in the real world, individual robots must reason about interactions with other agents, which often occur without explicit communication. Recent work has identified game theory, particularly the concept of Nash Equilibrium (NE), as a key enabler for behavior-aware decision-making. Yet, existing work falls short of fully unleashing the power of game-theoretic reasoning. Specifically, popular optimization-based methods require simplified robot dynamics and tend to get trapped in local minima due to convexification. Other works that rely on payoff matrices suffer from poor scalability due to the explicit enumeration of all possible trajectories. To bridge this gap, we introduce Game-Theoretic Nested Search (GTNS), a novel, scalable, and provably correct approach for computing NEs in general dynamical systems. GTNS efficiently searches the action space of all agents involved, while discarding trajectories that violate the NE constraint (no unilateral deviation) through an inner search over a lower-dimensional space. Our algorithm enables explicit selection among equilibria by utilizing a user-specified global objective, thereby capturing a rich set of realistic interactions. We demonstrate the approach on a variety of autonomous driving and racing scenarios where we achieve solutions in mere seconds on commodity hardware.
Generalizing Multi-Objective Search via Objective-Aggregation Functions
Sep 26, 2025Multi-objective search (MOS) has become essential in robotics, as real-world robotic systems need to simultaneously balance multiple, often conflicting objectives. Recent works explore complex interactions between objectives, leading to problem formulations that do not allow the usage of out-of-the-box state-of-the-art MOS algorithms. In this paper, we suggest a generalized problem formulation that optimizes solution objectives via aggregation functions of hidden (search) objectives. We show that our formulation supports the application of standard MOS algorithms, necessitating only to properly extend several core operations to reflect the specific aggregation functions employed. We demonstrate our approach in several diverse robotics planning problems, spanning motion-planning for navigation, manipulation and planning fr medical systems under obstacle uncertainty as well as inspection planning, and route planning with different road types. We solve the problems using state-of-the-art MOS algorithms after properly extending their core operations, and provide empirical evidence that they outperform by orders of magnitude the vanilla versions of the algorithms applied to the same problems but without objective aggregation.
A Preprocessing Framework for Efficient Approximate Bi-Objective Shortest-Path Computation in the Presence of Correlated Objectives
May 28, 2025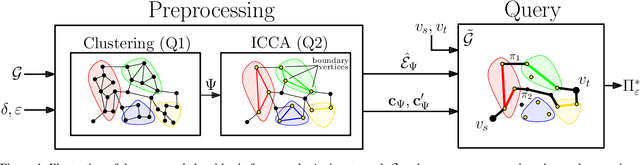



The bi-objective shortest-path (BOSP) problem seeks to find paths between start and target vertices of a graph while optimizing two conflicting objective functions. We consider the BOSP problem in the presence of correlated objectives. Such correlations often occur in real-world settings such as road networks, where optimizing two positively correlated objectives, such as travel time and fuel consumption, is common. BOSP is generally computationally challenging as the size of the search space is exponential in the number of objective functions and the graph size. Bounded sub-optimal BOSP solvers such as A*pex alleviate this complexity by approximating the Pareto-optimal solution set rather than computing it exactly (given a user-provided approximation factor). As the correlation between objective functions increases, smaller approximation factors are sufficient for collapsing the entire Pareto-optimal set into a single solution. We leverage this insight to propose an efficient algorithm that reduces the search effort in the presence of correlated objectives. Our approach for computing approximations of the entire Pareto-optimal set is inspired by graph-clustering algorithms. It uses a preprocessing phase to identify correlated clusters within a graph and to generate a new graph representation. This allows a natural generalization of A*pex to run up to five times faster on DIMACS dataset instances, a standard benchmark in the field. To the best of our knowledge, this is the first algorithm proposed that efficiently and effectively exploits correlations in the context of bi-objective search while providing theoretical guarantees on solution quality.
From Configuration-Space Clearance to Feature-Space Margin: Sample Complexity in Learning-Based Collision Detection
Feb 06, 2025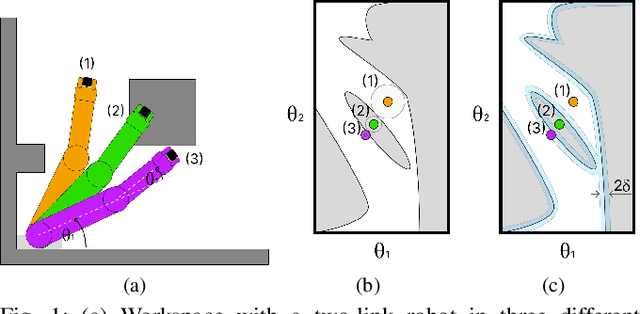
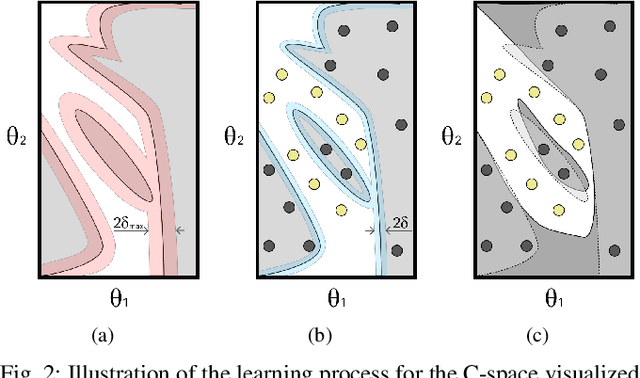
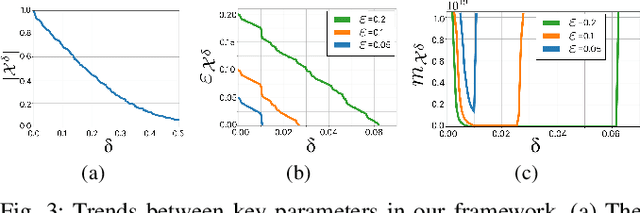
Motion planning is a central challenge in robotics, with learning-based approaches gaining significant attention in recent years. Our work focuses on a specific aspect of these approaches: using machine-learning techniques, particularly Support Vector Machines (SVM), to evaluate whether robot configurations are collision free, an operation termed ``collision detection''. Despite the growing popularity of these methods, there is a lack of theory supporting their efficiency and prediction accuracy. This is in stark contrast to the rich theoretical results of machine-learning methods in general and of SVMs in particular. Our work bridges this gap by analyzing the sample complexity of an SVM classifier for learning-based collision detection in motion planning. We bound the number of samples needed to achieve a specified accuracy at a given confidence level. This result is stated in terms relevant to robot motion-planning such as the system's clearance. Building on these theoretical results, we propose a collision-detection algorithm that can also provide statistical guarantees on the algorithm's error in classifying robot configurations as collision-free or not.
Offline Task Assistance Planning on a Graph:Theoretic and Algorithmic Foundations
Sep 10, 2024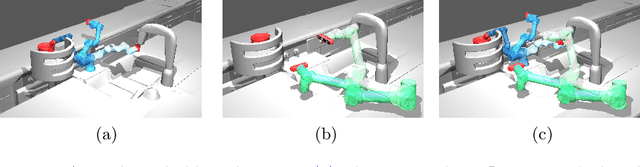

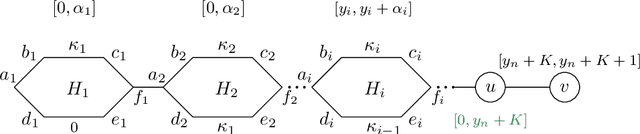
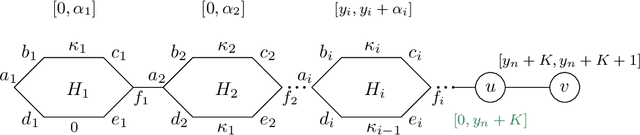
In this work we introduce the problem of task assistance planning where we are given two robots Rtask and Rassist. The first robot, Rtask, is in charge of performing a given task by executing a precomputed path. The second robot, Rassist, is in charge of assisting the task performed by Rtask using on-board sensors. The ability of Rassist to provide assistance to Rtask depends on the locations of both robots. Since Rtask is moving along its path, Rassist may also need to move to provide as much assistance as possible. The problem we study is how to compute a path for Rassist so as to maximize the portion of Rtask's path for which assistance is provided. We limit the problem to the setting where Rassist moves on a roadmap which is a graph embedded in its configuration space and show that this problem is NP-hard. Fortunately, we show that when Rassist moves on a given path, and all we have to do is compute the times at which Rassist should move from one configuration to the following one, we can solve the problem optimally in polynomial time. Together with carefully-crafted upper bounds, this polynomial-time algorithm is integrated into a Branch and Bound-based algorithm that can compute optimal solutions to the problem outperforming baselines by several orders of magnitude. We demonstrate our work empirically in simulated scenarios containing both planar manipulators and UR robots as well as in the lab on real robots.
Towards Contact-Aided Motion Planning for Tendon-Driven Continuum Robots
Feb 21, 2024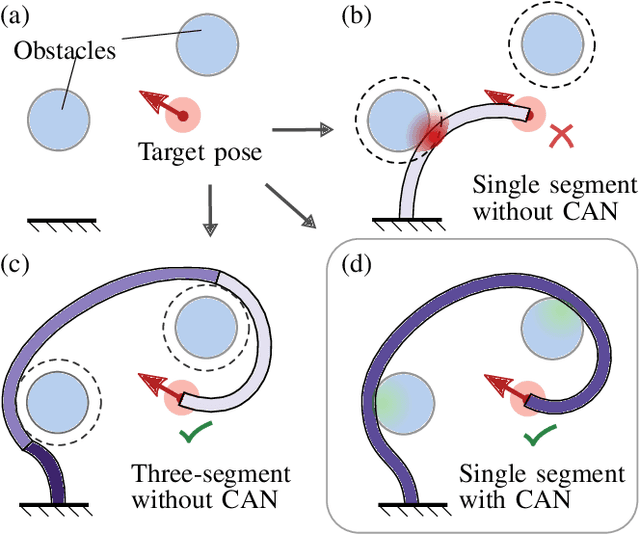
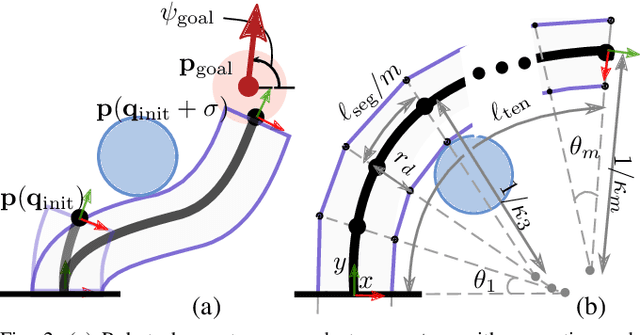
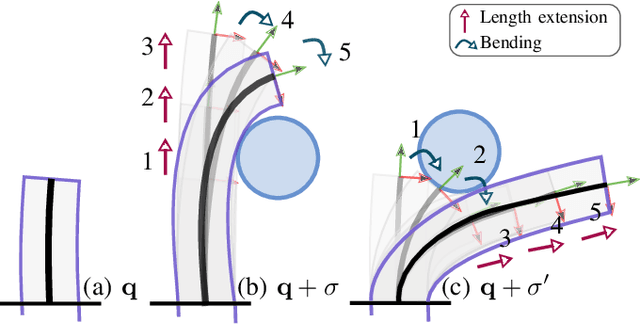
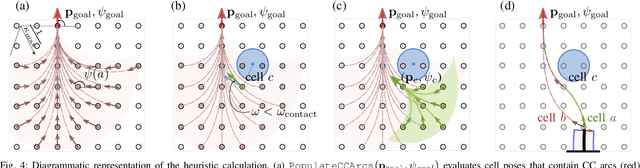
Tendon-driven continuum robots (TDCRs), with their flexible backbones, offer the advantage of being used for navigating complex, cluttered environments. However, to do so, they typically require multiple segments, often leading to complex actuation and control challenges. To this end, we propose a novel approach to navigate cluttered spaces effectively for a single-segment long TDCR which is the simplest topology from a mechanical point of view. Our key insight is that by leveraging contact with the environment we can achieve multiple curvatures without mechanical alterations to the robot. Specifically, we propose a search-based motion planner for a single-segment TDCR. This planner, guided by a specially designed heuristic, discretizes the configuration space and employs a best-first search. The heuristic, crucial for efficient navigation, provides an effective cost-to-go estimation while respecting the kinematic constraints of the TDCR and environmental interactions. We empirically demonstrate the efficiency of our planner-testing over 525 queries in environments with both convex and non-convex obstacles, our planner is demonstrated to have a success rate of about 80% while baselines were not able to obtain a success rate higher than 30%. The difference is attributed to our novel heuristic which is shown to significantly reduce the required search space.