 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling-based Task and Kinodynamic Motion Planning under Semantic Uncertainty
Apr 01, 2026This paper tackles the problem of integrated task and kinodynamic motion planning in uncertain environments. We consider a robot with nonlinear dynamics tasked with a Linear Temporal Logic over finite traces ($\ltlf$) specification operating in a partially observable environment. Specifically, the uncertainty is in the semantic labels of the environment. We show how the problem can be modeled as a Partially Observable Stochastic Hybrid System that captures the robot dynamics, $\ltlf$ task, and uncertainty in the environment state variables. We propose an anytime algorithm that takes advantage of the structure of the hybrid system, and combines the effectiveness of decision-making techniques and sampling-based motion planning. We prove the soundness and asymptotic optimality of the algorithm. Results show the efficacy of our algorithm in uncertain environments, and that it consistently outperforms baseline methods.
Kino-PAX$^+$: Near-Optimal Massively Parallel Kinodynamic Sampling-based Motion Planner
Feb 02, 2026Sampling-based motion planners (SBMPs) are widely used for robot motion planning with complex kinodynamic constraints in high-dimensional spaces, yet they struggle to achieve \emph{real-time} performance due to their serial computation design. Recent efforts to parallelize SBMPs have achieved significant speedups in finding feasible solutions; however, they provide no guarantees of optimizing an objective function. We introduce Kino-PAX$^{+}$, a massively parallel kinodynamic SBMP with asymptotic near-optimal guarantees. Kino-PAX$^{+}$ builds a sparse tree of dynamically feasible trajectories by decomposing traditionally serial operations into three massively parallel subroutines. The algorithm focuses computation on the most promising nodes within local neighborhoods for propagation and refinement, enabling rapid improvement of solution cost. We prove that, while maintaining probabilistic $δ$-robust completeness, this focus on promising nodes ensures asymptotic $δ$-robust near-optimality. Our results show that Kino-PAX$^{+}$ finds solutions up to three orders of magnitude faster than existing serial methods and achieves lower solution costs than a state-of-the-art GPU-based planner.
Scalable Formal Verification via Autoencoder Latent Space Abstraction
Dec 16, 2025Finite Abstraction methods provide a powerful formal framework for proving that systems satisfy their specifications. However, these techniques face scalability challenges for high-dimensional systems, as they rely on state-space discretization which grows exponentially with dimension. Learning-based approaches to dimensionality reduction, utilizing neural networks and autoencoders, have shown great potential to alleviate this problem. However, ensuring the correctness of the resulting verification results remains an open question. In this work, we provide a formal approach to reduce the dimensionality of systems via convex autoencoders and learn the dynamics in the latent space through a kernel-based method. We then construct a finite abstraction from the learned model in the latent space and guarantee that the abstraction contains the true behaviors of the original system. We show that the verification results in the latent space can be mapped back to the original system. Finally, we demonstrate the effectiveness of our approach on multiple systems, including a 26D system controlled by a neural network, showing significant scalability improvements without loss of rigor.
Universal Learning of Stochastic Dynamics for Exact Belief Propagation using Bernstein Normalizing Flows
Sep 19, 2025Predicting the distribution of future states in a stochastic system, known as belief propagation, is fundamental to reasoning under uncertainty. However, nonlinear dynamics often make analytical belief propagation intractable, requiring approximate methods. When the system model is unknown and must be learned from data, a key question arises: can we learn a model that (i) universally approximates general nonlinear stochastic dynamics, and (ii) supports analytical belief propagation? This paper establishes the theoretical foundations for a class of models that satisfy both properties. The proposed approach combines the expressiveness of normalizing flows for density estimation with the analytical tractability of Bernstein polynomials. Empirical results show the efficacy of our learned model over state-of-the-art data-driven methods for belief propagation, especially for highly non-linear systems with non-additive, non-Gaussian noise.
Extended Version: Multi-Robot Motion Planning with Cooperative Localization
Apr 08, 2025We consider the uncertain multi-robot motion planning (MRMP) problem with cooperative localization (CL-MRMP), under both motion and measurement noise, where each robot can act as a sensor for its nearby teammates. We formalize CL-MRMP as a chance-constrained motion planning problem, and propose a safety-guaranteed algorithm that explicitly accounts for robot-robot correlations. Our approach extends a sampling-based planner to solve CL-MRMP while preserving probabilistic completeness. To improve efficiency, we introduce novel biasing techniques. We evaluate our method across diverse benchmarks, demonstrating its effectiveness in generating motion plans, with significant performance gains from biasing strategies.
Falsification of Autonomous Systems in Rich Environments
Dec 23, 2024Validating the behavior of autonomous Cyber-Physical Systems (CPS) and Artificial Intelligence (AI) agents, which rely on automated controllers, is an objective of great importance. In recent years, Neural-Network (NN) controllers have been demonstrating great promise. Unfortunately, such learned controllers are often not certified and can cause the system to suffer from unpredictable or unsafe behavior. To mitigate this issue, a great effort has been dedicated to automated verification of systems. Specifically, works in the category of ``black-box testing'' rely on repeated system simulations to find a falsifying counterexample of a system run that violates a specification. As running high-fidelity simulations is computationally demanding, the goal of falsification approaches is to minimize the simulation effort (NN inference queries) needed to return a falsifying example. This often proves to be a great challenge, especially when the tested controller is well-trained. This work contributes a novel falsification approach for autonomous systems under formal specification operating in uncertain environments. We are especially interested in CPS operating in rich, semantically-defined, open environments, which yield high-dimensional, simulation-dependent sensor observations. Our approach introduces a novel reformulation of the falsification problem as the problem of planning a trajectory for a ``meta-system,'' which wraps and encapsulates the examined system; we call this approach: meta-planning. This formulation can be solved with standard sampling-based motion-planning techniques (like RRT) and can gradually integrate domain knowledge to improve the search. We support the suggested approach with an experimental study on falsification of an obstacle-avoiding autonomous car with a NN controller, where meta-planning demonstrates superior performance over alternative approaches.
Error Bounds for Deep Learning-based Uncertainty Propagation in SDEs
Oct 28, 2024



Stochastic differential equations are commonly used to describe the evolution of stochastic processes. The uncertainty of such processes is best represented by the probability density function (PDF), whose evolution is governed by the Fokker-Planck partial differential equation (FP-PDE). However, it is generally infeasible to solve the FP-PDE in closed form. In this work, we show that physics-informed neural networks (PINNs) can be trained to approximate the solution PDF using existing methods. The main contribution is the analysis of the approximation error: we develop a theory to construct an arbitrary tight error bound with PINNs. In addition, we derive a practical error bound that can be efficiently constructed with existing training methods. Finally, we explain that this error-bound theory generalizes to approximate solutions of other linear PDEs. Several numerical experiments are conducted to demonstrate and validate the proposed methods.
Learning-Based Shielding for Safe Autonomy under Unknown Dynamics
Oct 07, 2024



Shielding is a common method used to guarantee the safety of a system under a black-box controller, such as a neural network controller from deep reinforcement learning (DRL), with simpler, verified controllers. Existing shielding methods rely on formal verification through Markov Decision Processes (MDPs), assuming either known or finite-state models, which limits their applicability to DRL settings with unknown, continuous-state systems. This paper addresses these limitations by proposing a data-driven shielding methodology that guarantees safety for unknown systems under black-box controllers. The approach leverages Deep Kernel Learning to model the systems' one-step evolution with uncertainty quantification and constructs a finite-state abstraction as an Interval MDP (IMDP). By focusing on safety properties expressed in safe linear temporal logic (safe LTL), we develop an algorithm that computes the maximally permissive set of safe policies on the IMDP, ensuring avoidance of unsafe states. The algorithms soundness and computational complexity are demonstrated through theoretical proofs and experiments on nonlinear systems, including a high-dimensional autonomous spacecraft scenario.
Admissibility Over Winning: A New Approach to Reactive Synthesis in Robotics
Oct 06, 2024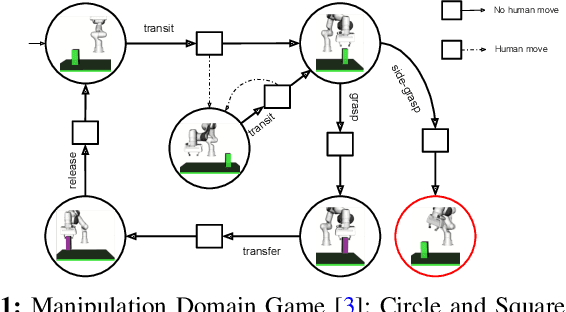
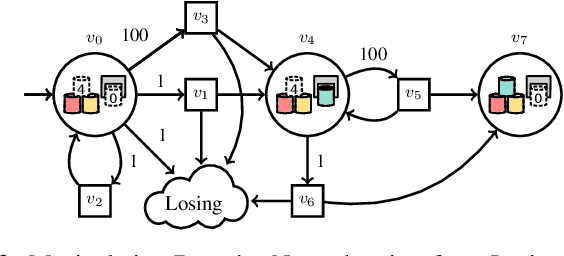
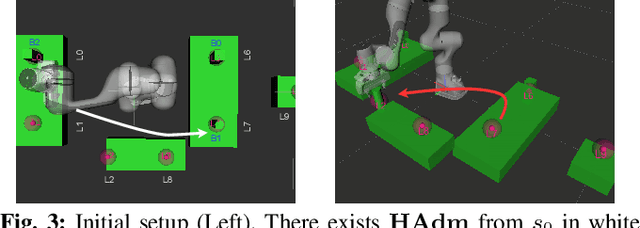

Reactive synthesis is a framework for modeling and automatically synthesizing strategies in robotics, typically through computing a \emph{winning} strategy in a 2-player game between the robot and the environment. Winning strategies, however, do not always exist, even in some simple cases. In such situations, it is still desirable for the robot to attempt its task rather than "giving up". In this work, we explore the notion of admissibility to define strategies beyond winning, tailored specifically for robotic systems. We introduce an ordering of admissible strategies and define \emph{admissibly rational strategies}, which aim to be winning and cooperative when possible, and non-violating and hopeful when necessary. We present an efficient synthesis algorithm and demonstrate that admissibly rational strategies produce desirable behaviors through case studies.
Kino-PAX: Highly Parallel Kinodynamic Sampling-based Planner
Sep 10, 2024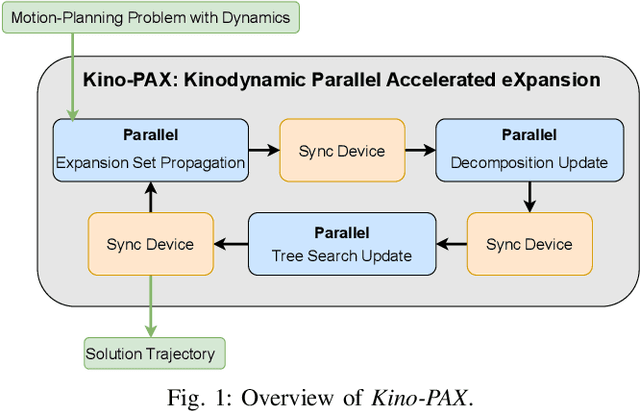
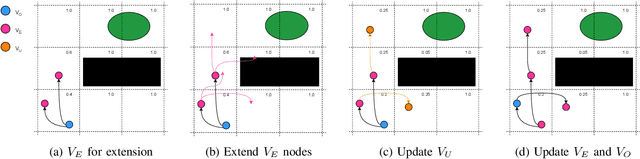
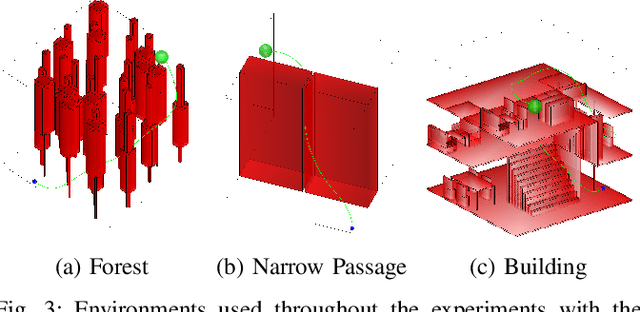
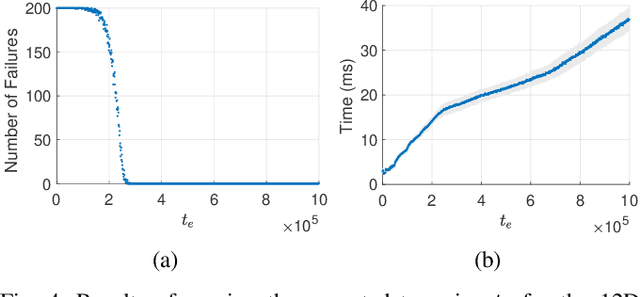
Sampling-based motion planners (SBMPs) are effective for planning with complex kinodynamic constraints in high-dimensional spaces, but they still struggle to achieve real-time performance, which is mainly due to their serial computation design. We present Kinodynamic Parallel Accelerated eXpansion (Kino-PAX), a novel highly parallel kinodynamic SBMP designed for parallel devices such as GPUs. Kino-PAX grows a tree of trajectory segments directly in parallel. Our key insight is how to decompose the iterative tree growth process into three massively parallel subroutines. Kino-PAX is designed to align with the parallel device execution hierarchies, through ensuring that threads are largely independent, share equal workloads, and take advantage of low-latency resources while minimizing high-latency data transfers and process synchronization. This design results in a very efficient GPU implementation. We prove that Kino-PAX is probabilistically complete and analyze its scalability with compute hardware improvements. Empirical evaluations demonstrate solutions in the order of 10 ms on a desktop GPU and in the order of 100 ms on an embedded GPU, representing up to 1000 times improvement compared to coarse-grained CPU parallelization of state-of-the-art sequential algorithms over a range of complex environments and systems.