 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite Neural Networks as Mixtures of Gaussian Processes: From Provable Error Bounds to Prior Selection
Jul 26, 2024Infinitely wide or deep neural networks (NNs) with independent and identically distributed (i.i.d.) parameters have been shown to be equivalent to Gaussian processes. Because of the favorable properties of Gaussian processes, this equivalence is commonly employed to analyze neural networks and has led to various breakthroughs over the years. However, neural networks and Gaussian processes are equivalent only in the limit; in the finite case there are currently no methods available to approximate a trained neural network with a Gaussian model with bounds on the approximation error. In this work, we present an algorithmic framework to approximate a neural network of finite width and depth, and with not necessarily i.i.d. parameters, with a mixture of Gaussian processes with error bounds on the approximation error. In particular, we consider the Wasserstein distance to quantify the closeness between probabilistic models and, by relying on tools from optimal transport and Gaussian processes, we iteratively approximate the output distribution of each layer of the neural network as a mixture of Gaussian processes. Crucially, for any NN and $\epsilon >0$ our approach is able to return a mixture of Gaussian processes that is $\epsilon$-close to the NN at a finite set of input points. Furthermore, we rely on the differentiability of the resulting error bound to show how our approach can be employed to tune the parameters of a NN to mimic the functional behavior of a given Gaussian process, e.g., for prior selection in the context of Bayesian inference. We empirically investigate the effectiveness of our results on both regression and classification problems with various neural network architectures. Our experiments highlight how our results can represent an important step towards understanding neural network predictions and formally quantifying their uncertainty.
BNN-DP: Robustness Certification of Bayesian Neural Networks via Dynamic Programming
Jun 19, 2023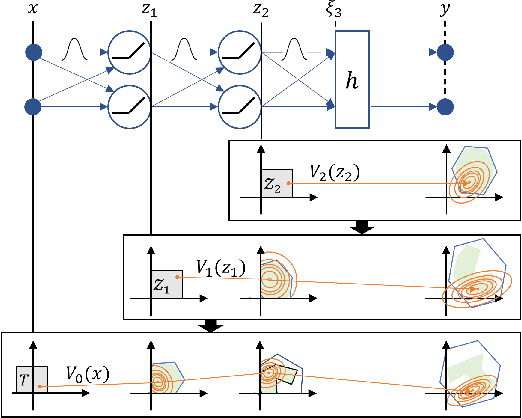
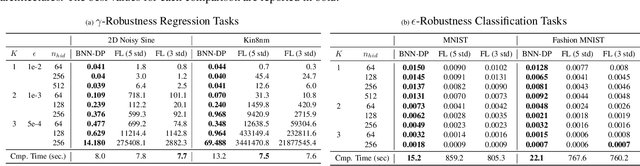
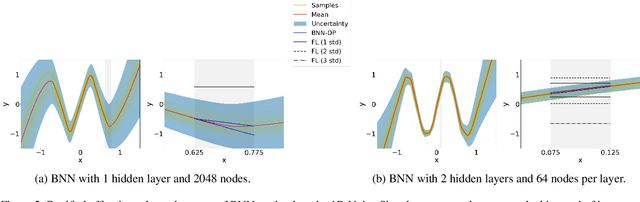
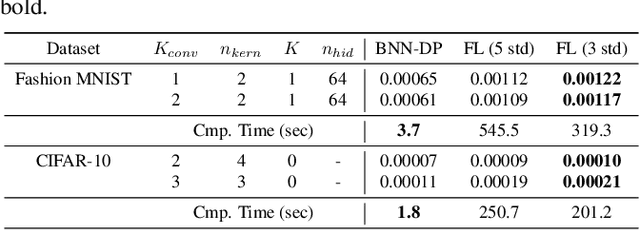
In this paper, we introduce BNN-DP, an efficient algorithmic framework for analysis of adversarial robustness of Bayesian Neural Networks (BNNs). Given a compact set of input points $T\subset \mathbb{R}^n$, BNN-DP computes lower and upper bounds on the BNN's predictions for all the points in $T$. The framework is based on an interpretation of BNNs as stochastic dynamical systems, which enables the use of Dynamic Programming (DP) algorithms to bound the prediction range along the layers of the network. Specifically, the method uses bound propagation techniques and convex relaxations to derive a backward recursion procedure to over-approximate the prediction range of the BNN with piecewise affine functions. The algorithm is general and can handle both regression and classification tasks. On a set of experiments on various regression and classification tasks and BNN architectures, we show that BNN-DP outperforms state-of-the-art methods by up to four orders of magnitude in both tightness of the bounds and computational efficiency.
A Self-Guided Approach for Navigation in a Minimalistic Foraging Robotic Swarm
May 21, 2021

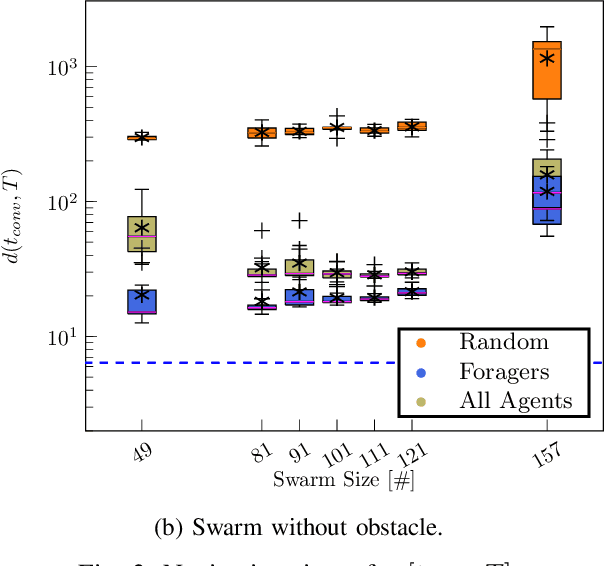
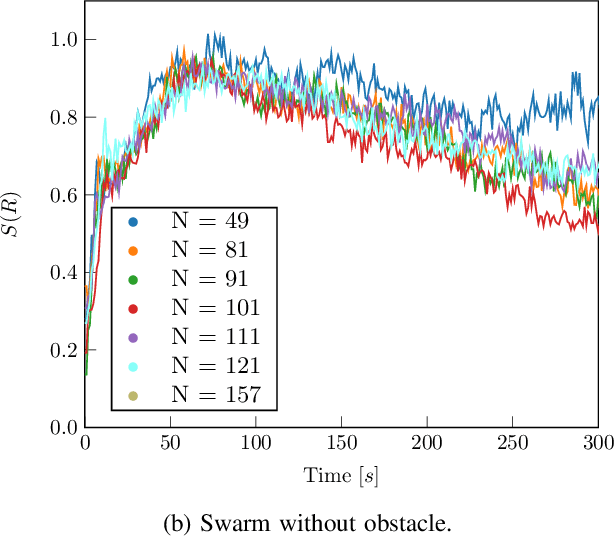
We present a biologically inspired design for swarm foraging based on ant's pheromone deployment, where the swarm is assumed to have very restricted capabilities. The robots do not require global or relative position measurements and the swarm is fully decentralized and needs no infrastructure in place. Additionally, the system only requires one-hop communication over the robot network, we do not make any assumptions about the connectivity of the communication graph and the transmission of information and computation is scalable versus the number of agents. This is done by letting the agents in the swarm act as foragers or as guiding agents (beacons). We present experimental results computed for a swarm of Elisa-3 robots on a simulator, and show how the swarm self-organizes to solve a foraging problem over an unknown environment, converging to trajectories around the shortest path. At last, we discuss the limitations of such a system and propose how the foraging efficiency can be increased.