 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA KL-regularization framework for learning to plan with adaptive priors
Oct 05, 2025Effective exploration remains a central challenge in model-based reinforcement learning (MBRL), particularly in high-dimensional continuous control tasks where sample efficiency is crucial. A prominent line of recent work leverages learned policies as proposal distributions for Model-Predictive Path Integral (MPPI) planning. Initial approaches update the sampling policy independently of the planner distribution, typically maximizing a learned value function with deterministic policy gradient and entropy regularization. However, because the states encountered during training depend on the MPPI planner, aligning the sampling policy with the planner improves the accuracy of value estimation and long-term performance. To this end, recent methods update the sampling policy by minimizing KL divergence to the planner distribution or by introducing planner-guided regularization into the policy update. In this work, we unify these MPPI-based reinforcement learning methods under a single framework by introducing Policy Optimization-Model Predictive Control (PO-MPC), a family of KL-regularized MBRL methods that integrate the planner's action distribution as a prior in policy optimization. By aligning the learned policy with the planner's behavior, PO-MPC allows more flexibility in the policy updates to trade off Return maximization and KL divergence minimization. We clarify how prior approaches emerge as special cases of this family, and we explore previously unstudied variations. Our experiments show that these extended configurations yield significant performance improvements, advancing the state of the art in MPPI-based RL.
Automatic Differentiation of Agent-Based Models
Sep 03, 2025Agent-based models (ABMs) simulate complex systems by capturing the bottom-up interactions of individual agents comprising the system. Many complex systems of interest, such as epidemics or financial markets, involve thousands or even millions of agents. Consequently, ABMs often become computationally demanding and rely on the calibration of numerous free parameters, which has significantly hindered their widespread adoption. In this paper, we demonstrate that automatic differentiation (AD) techniques can effectively alleviate these computational burdens. By applying AD to ABMs, the gradients of the simulator become readily available, greatly facilitating essential tasks such as calibration and sensitivity analysis. Specifically, we show how AD enables variational inference (VI) techniques for efficient parameter calibration. Our experiments demonstrate substantial performance improvements and computational savings using VI on three prominent ABMs: Axtell's model of firms; Sugarscape; and the SIR epidemiological model. Our approach thus significantly enhances the practicality and scalability of ABMs for studying complex systems.
Emergent Risk Awareness in Rational Agents under Resource Constraints
May 29, 2025Advanced reasoning models with agentic capabilities (AI agents) are deployed to interact with humans and to solve sequential decision-making problems under (approximate) utility functions and internal models. When such problems have resource or failure constraints where action sequences may be forcibly terminated once resources are exhausted, agents face implicit trade-offs that reshape their utility-driven (rational) behaviour. Additionally, since these agents are typically commissioned by a human principal to act on their behalf, asymmetries in constraint exposure can give rise to previously unanticipated misalignment between human objectives and agent incentives. We formalise this setting through a survival bandit framework, provide theoretical and empirical results that quantify the impact of survival-driven preference shifts, identify conditions under which misalignment emerges and propose mechanisms to mitigate the emergence of risk-seeking or risk-averse behaviours. As a result, this work aims to increase understanding and interpretability of emergent behaviours of AI agents operating under such survival pressure, and offer guidelines for safely deploying such AI systems in critical resource-limited environments.
Predictability Awareness for Efficient and Robust Multi-Agent Coordination
Nov 09, 2024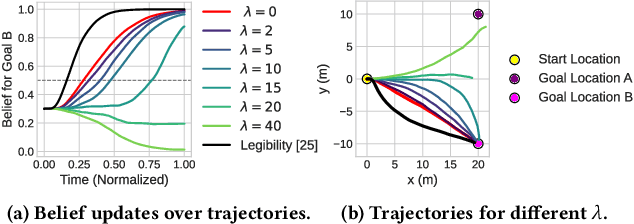
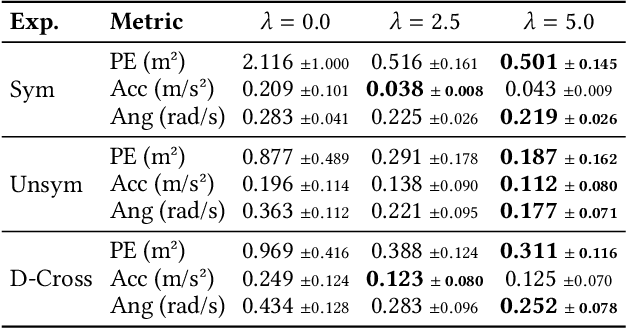
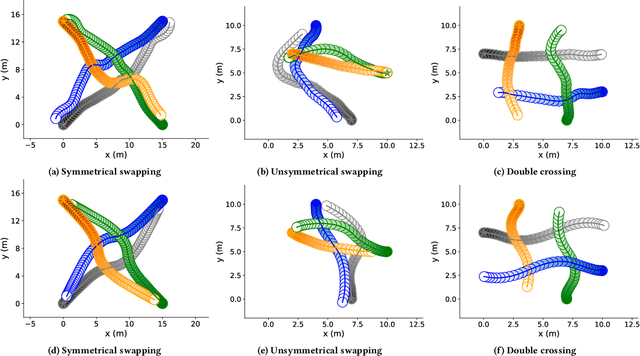
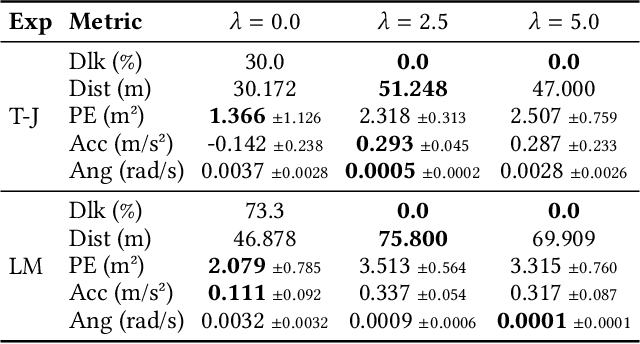
To safely and efficiently solve motion planning problems in multi-agent settings, most approaches attempt to solve a joint optimization that explicitly accounts for the responses triggered in other agents. This often results in solutions with an exponential computational complexity, making these methods intractable for complex scenarios with many agents. While sequential predict-and-plan approaches are more scalable, they tend to perform poorly in highly interactive environments. This paper proposes a method to improve the interactive capabilities of sequential predict-and-plan methods in multi-agent navigation problems by introducing predictability as an optimization objective. We interpret predictability through the use of general prediction models, by allowing agents to predict themselves and estimate how they align with these external predictions. We formally introduce this behavior through the free-energy of the system, which reduces under appropriate bounds to the Kullback-Leibler divergence between plan and prediction, and use this as a penalty for unpredictable trajectories.The proposed interpretation of predictability allows agents to more robustly leverage prediction models, and fosters a soft social convention that accelerates agreement on coordination strategies without the need of explicit high level control or communication. We show how this predictability-aware planning leads to lower-cost trajectories and reduces planning effort in a set of multi-robot problems, including autonomous driving experiments with human driver data, where we show that the benefits of considering predictability apply even when only the ego-agent uses this strategy.
RACP: Risk-Aware Contingency Planning with Multi-Modal Predictions
Feb 27, 2024



For an autonomous vehicle to operate reliably within real-world traffic scenarios, it is imperative to assess the repercussions of its prospective actions by anticipating the uncertain intentions exhibited by other participants in the traffic environment. Driven by the pronounced multi-modal nature of human driving behavior, this paper presents an approach that leverages Bayesian beliefs over the distribution of potential policies of other road users to construct a novel risk-aware probabilistic motion planning framework. In particular, we propose a novel contingency planner that outputs long-term contingent plans conditioned on multiple possible intents for other actors in the traffic scene. The Bayesian belief is incorporated into the optimization cost function to influence the behavior of the short-term plan based on the likelihood of other agents' policies. Furthermore, a probabilistic risk metric is employed to fine-tune the balance between efficiency and robustness. Through a series of closed-loop safety-critical simulated traffic scenarios shared with human-driven vehicles, we demonstrate the practical efficacy of our proposed approach that can handle multi-vehicle scenarios.
Predictable Reinforcement Learning Dynamics through Entropy Rate Minimization
Nov 30, 2023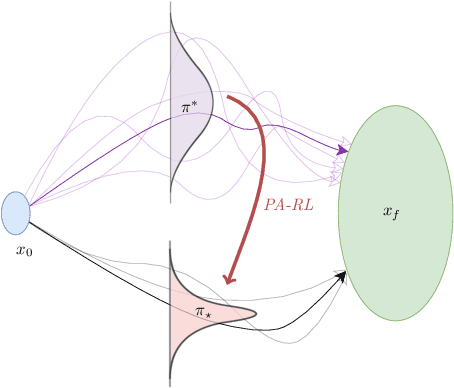
In Reinforcement Learning (RL), agents have no incentive to exhibit predictable behaviors, and are often pushed (through e.g. policy entropy regularization) to randomize their actions in favor of exploration. From a human perspective, this makes RL agents hard to interpret and predict, and from a safety perspective, even harder to formally verify. We propose a novel method to induce predictable behavior in RL agents, referred to as Predictability-Aware RL (PA-RL), which employs the state sequence entropy rate as a predictability measure. We show how the entropy rate can be formulated as an average reward objective, and since its entropy reward function is policy-dependent, we introduce an action-dependent surrogate entropy enabling the use of PG methods. We prove that deterministic policies minimizing the average surrogate reward exist and also minimize the actual entropy rate, and show how, given a learned dynamical model, we are able to approximate the value function associated to the true entropy rate. Finally, we demonstrate the effectiveness of the approach in RL tasks inspired by human-robot use-cases, and show how it produces agents with more predictable behavior while achieving near-optimal rewards.
Observational Robustness and Invariances in Reinforcement Learning via Lexicographic Objectives
Sep 30, 2022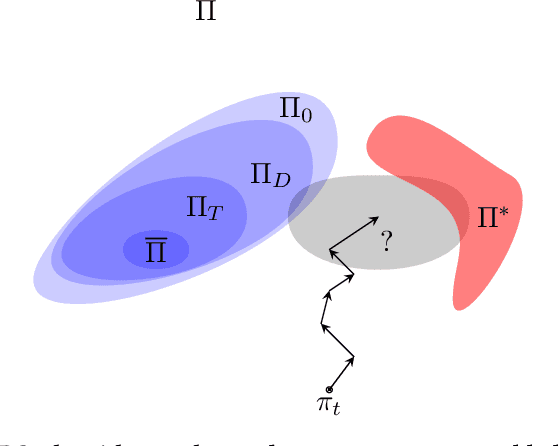
Policy robustness in Reinforcement Learning (RL) may not be desirable at any price; the alterations caused by robustness requirements from otherwise optimal policies should be explainable and quantifiable. Policy gradient algorithms that have strong convergence guarantees are usually modified to obtain robust policies in ways that do not preserve algorithm guarantees, which defeats the purpose of formal robustness requirements. In this work we study a notion of robustness in partially observable MDPs where state observations are perturbed by a noise-induced stochastic kernel. We characterise the set of policies that are maximally robust by analysing how the policies are altered by this kernel. We then establish a connection between such robust policies and certain properties of the noise kernel, as well as with structural properties of the underlying MDPs, constructing sufficient conditions for policy robustness. We use these notions to propose a robustness-inducing scheme, applicable to any policy gradient algorithm, to formally trade off the reward achieved by a policy with its robustness level through lexicographic optimisation, which preserves convergence properties of the original algorithm. We test the the proposed approach through numerical experiments on safety-critical RL environments, and show how the proposed method helps achieve high robustness when state errors are introduced in the policy roll-out.
Robust Event-Driven Interactions in Cooperative Multi-Agent Learning
Apr 07, 2022
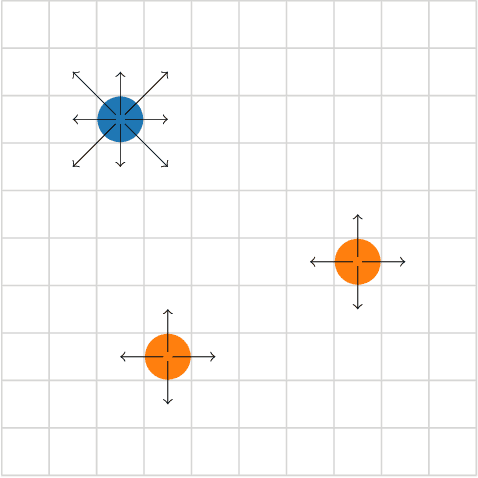
We present an approach to reduce the communication required between agents in a Multi-Agent learning system by exploiting the inherent robustness of the underlying Markov Decision Process. We compute so-called robustness surrogate functions (off-line), that give agents a conservative indication of how far their state measurements can deviate before they need to update other agents in the system. This results in fully distributed decision functions, enabling agents to decide when it is necessary to update others. We derive bounds on the optimality of the resulting systems in terms of the discounted sum of rewards obtained, and show these bounds are a function of the design parameters. Additionally, we extend the results for the case where the robustness surrogate functions are learned from data, and present experimental results demonstrating a significant reduction in communication events between agents.
Event-Based Communication in Multi-Agent Distributed Q-Learning
Sep 09, 2021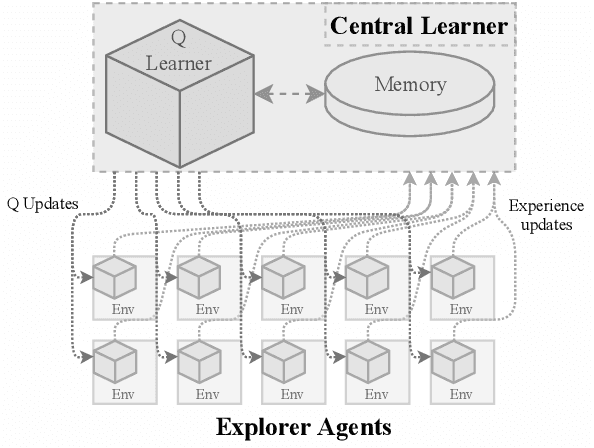
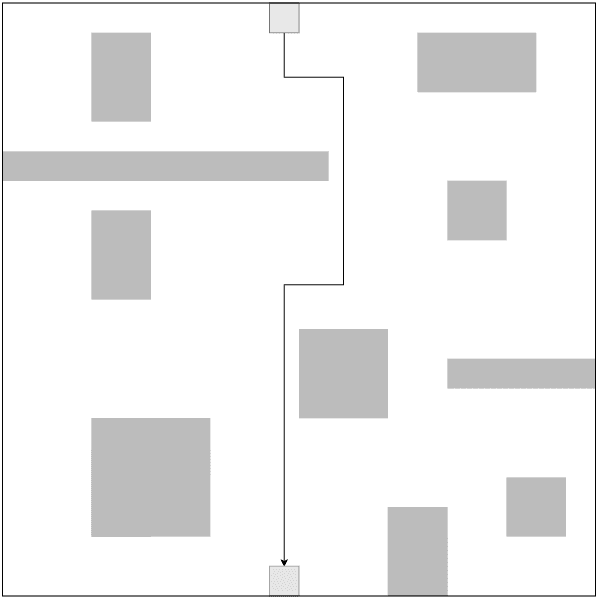
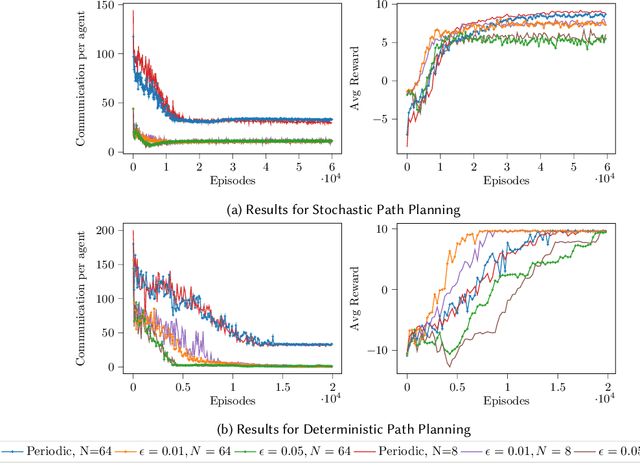
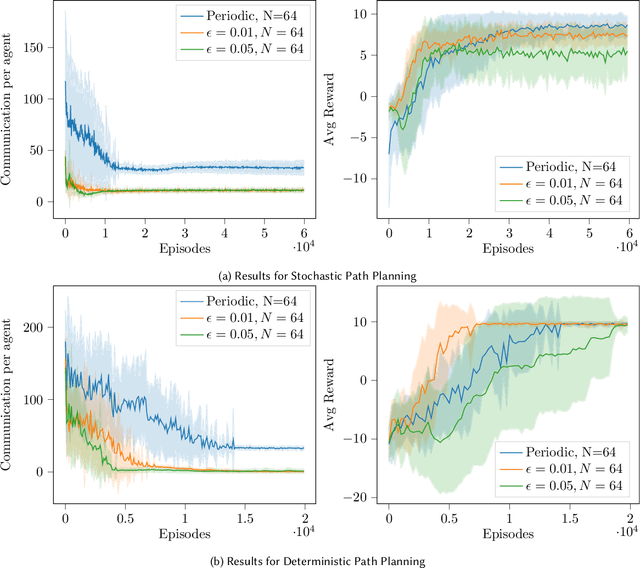
We present in this work an approach to reduce the communication of information needed on a multi-agent learning system inspired by Event Triggered Control (ETC) techniques. We consider a baseline scenario of a distributed Q-learning problem on a Markov Decision Process (MDP). Following an event-based approach, N agents explore the MDP and communicate experiences to a central learner only when necessary, which performs updates of the actor Q functions. We analyse the convergence guarantees retained with respect to a regular Q-learning algorithm, and present experimental results showing that event-based communication results in a substantial reduction of data transmission rates in such distributed systems. Additionally, we discuss what effects (desired and undesired) these event-based approaches have on the learning processes studied, and how they can be applied to more complex multi-agent learning systems.
A Self-Guided Approach for Navigation in a Minimalistic Foraging Robotic Swarm
May 21, 2021

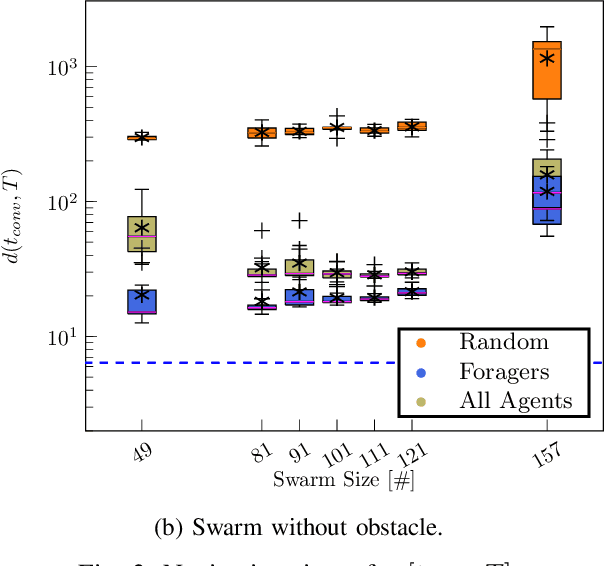
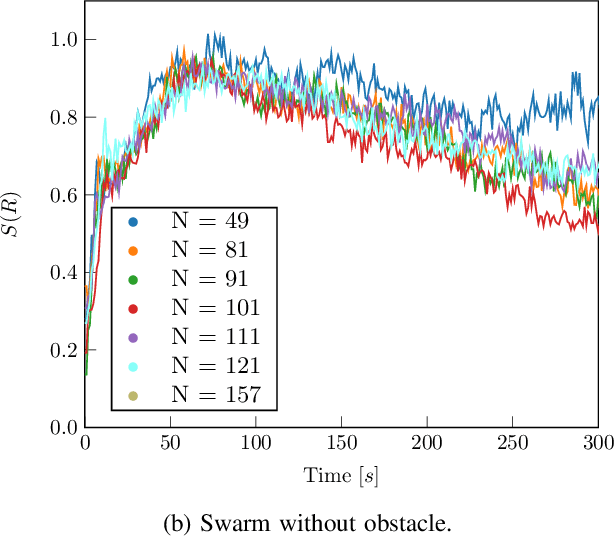
We present a biologically inspired design for swarm foraging based on ant's pheromone deployment, where the swarm is assumed to have very restricted capabilities. The robots do not require global or relative position measurements and the swarm is fully decentralized and needs no infrastructure in place. Additionally, the system only requires one-hop communication over the robot network, we do not make any assumptions about the connectivity of the communication graph and the transmission of information and computation is scalable versus the number of agents. This is done by letting the agents in the swarm act as foragers or as guiding agents (beacons). We present experimental results computed for a swarm of Elisa-3 robots on a simulator, and show how the swarm self-organizes to solve a foraging problem over an unknown environment, converging to trajectories around the shortest path. At last, we discuss the limitations of such a system and propose how the foraging efficiency can be increased.