 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictable Reinforcement Learning Dynamics through Entropy Rate Minimization
Nov 30, 2023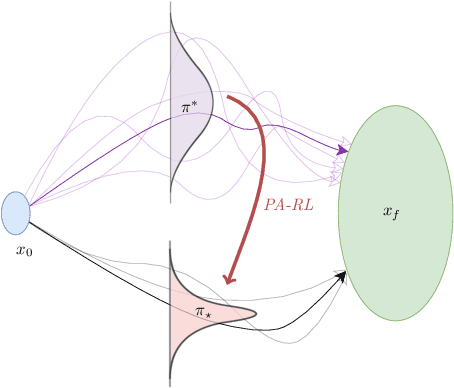
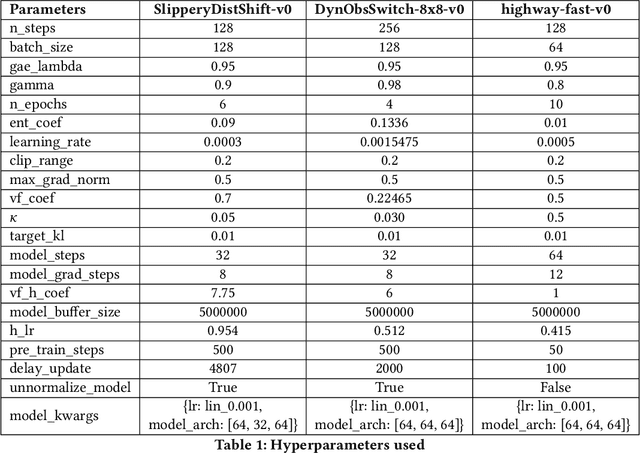
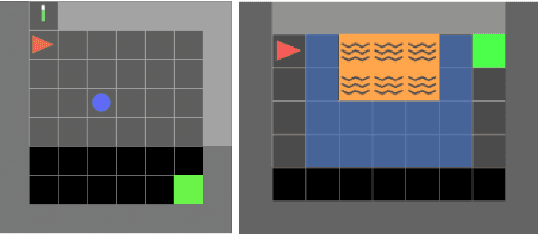
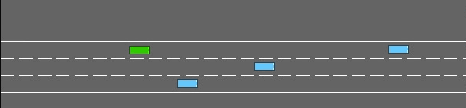
In Reinforcement Learning (RL), agents have no incentive to exhibit predictable behaviors, and are often pushed (through e.g. policy entropy regularization) to randomize their actions in favor of exploration. From a human perspective, this makes RL agents hard to interpret and predict, and from a safety perspective, even harder to formally verify. We propose a novel method to induce predictable behavior in RL agents, referred to as Predictability-Aware RL (PA-RL), which employs the state sequence entropy rate as a predictability measure. We show how the entropy rate can be formulated as an average reward objective, and since its entropy reward function is policy-dependent, we introduce an action-dependent surrogate entropy enabling the use of PG methods. We prove that deterministic policies minimizing the average surrogate reward exist and also minimize the actual entropy rate, and show how, given a learned dynamical model, we are able to approximate the value function associated to the true entropy rate. Finally, we demonstrate the effectiveness of the approach in RL tasks inspired by human-robot use-cases, and show how it produces agents with more predictable behavior while achieving near-optimal rewards.
Interval Markov Decision Processes with Continuous Action-Spaces
Nov 02, 2022

Interval Markov Decision Processes (IMDPs) are uncertain Markov models, where the transition probabilities belong to intervals. Recently, there has been a surge of research on employing IMDPs as abstractions of stochastic systems for control synthesis. However, due to the absence of algorithms for synthesis over IMDPs with continuous action-spaces, the action-space is assumed discrete a-priori, which is a restrictive assumption for many applications. Motivated by this, we introduce continuous-action IMDPs (caIMDPs), where the bounds on transition probabilities are functions of the action variables, and study value iteration for maximizing expected cumulative rewards. Specifically, we show that solving the max-min problem associated to value iteration is equivalent to solving $|\mathcal{Q}|$ max problems, where $|\mathcal{Q}|$ is the number of states of the caIMDP. Then, exploiting the simple form of these max problems, we identify cases where value iteration over caIMDPs can be solved efficiently (e.g., with linear or convex programming). We also gain other interesting insights: e.g., in the case where the action set $\mathcal{A}$ is a polytope and the transition bounds are linear, synthesizing over a discrete-action IMDP, where the actions are the vertices of $\mathcal{A}$, is sufficient for optimality. We demonstrate our results on a numerical example. Finally, we include a short discussion on employing caIMDPs as abstractions for control synthesis.