 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Energy-Based Models for Physical AI: Provably Stable Identification of Port-Hamiltonian Dynamics
Apr 02, 2026Energy-based models (EBMs) implement inference as gradient descent on a learned Lyapunov function, yielding interpretable, structure-preserving alternatives to black-box neural ODEs and aligning naturally with physical AI. Yet their use in system identification remains limited, and existing architectures lack formal stability guarantees that globally preclude unstable modes. We address this gap by introducing an EBM framework for system identification with stable, dissipative, absorbing invariant dynamics. Unlike classical global Lyapunov stability, absorbing invariance expands the class of stability-preserving architectures, enabling more flexible and expressive EBMs. We extend EBM theory to nonsmooth activations by establishing negative energy dissipation via Clarke derivatives and deriving new conditions for radial unboundedness, exposing a stability-expressivity tradeoff in standard EBMs. To overcome this, we introduce a hybrid architecture with a dynamical visible layer and static hidden layers, prove absorbing invariance under mild assumptions, and show that these guarantees extend to port-Hamiltonian EBMs. Experiments on metric-deformed multi-well and ring systems validate the approach, showcasing how our hybrid EBM architecture combines expressivity with sound and provable safety guarantees by design.
Evaluating randomized smoothing as a defense against adversarial attacks in trajectory prediction
Mar 11, 2026Accurate and robust trajectory prediction is essential for safe and efficient autonomous driving, yet recent work has shown that even state-of-the-art prediction models are highly vulnerable to inputs being mildly perturbed by adversarial attacks. Although model vulnerabilities to such attacks have been studied, work on effective countermeasures remains limited. In this work, we develop and evaluate a new defense mechanism for trajectory prediction models based on randomized smoothing -- an approach previously applied successfully in other domains. We evaluate its ability to improve model robustness through a series of experiments that test different strategies of randomized smoothing. We show that our approach can consistently improve prediction robustness of multiple base trajectory prediction models in various datasets without compromising accuracy in non-adversarial settings. Our results demonstrate that randomized smoothing offers a simple and computationally inexpensive technique for mitigating adversarial attacks in trajectory prediction.
Efficient Distribution Learning with Error Bounds in Wasserstein Distance
Feb 08, 2026The Wasserstein distance has emerged as a key metric to quantify distances between probability distributions, with applications in various fields, including machine learning, control theory, decision theory, and biological systems. Consequently, learning an unknown distribution with non-asymptotic and easy-to-compute error bounds in Wasserstein distance has become a fundamental problem in many fields. In this paper, we devise a novel algorithmic and theoretical framework to approximate an unknown probability distribution $\mathbb{P}$ from a finite set of samples by an approximate discrete distribution $\widehat{\mathbb{P}}$ while bounding the Wasserstein distance between $\mathbb{P}$ and $\widehat{\mathbb{P}}$. Our framework leverages optimal transport, nonlinear optimization, and concentration inequalities. In particular, we show that, even if $\mathbb{P}$ is unknown, the Wasserstein distance between $\mathbb{P}$ and $\widehat{\mathbb{P}}$ can be efficiently bounded with high confidence by solving a tractable optimization problem (a mixed integer linear program) of a size that only depends on the size of the support of $\widehat{\mathbb{P}}$. This enables us to develop intelligent clustering algorithms to optimally find the support of $\widehat{\mathbb{P}}$ while minimizing the Wasserstein distance error. On a set of benchmarks, we demonstrate that our approach outperforms state-of-the-art comparable methods by generally returning approximating distributions with substantially smaller support and tighter error bounds.
Scalable Formal Verification via Autoencoder Latent Space Abstraction
Dec 16, 2025Finite Abstraction methods provide a powerful formal framework for proving that systems satisfy their specifications. However, these techniques face scalability challenges for high-dimensional systems, as they rely on state-space discretization which grows exponentially with dimension. Learning-based approaches to dimensionality reduction, utilizing neural networks and autoencoders, have shown great potential to alleviate this problem. However, ensuring the correctness of the resulting verification results remains an open question. In this work, we provide a formal approach to reduce the dimensionality of systems via convex autoencoders and learn the dynamics in the latent space through a kernel-based method. We then construct a finite abstraction from the learned model in the latent space and guarantee that the abstraction contains the true behaviors of the original system. We show that the verification results in the latent space can be mapped back to the original system. Finally, we demonstrate the effectiveness of our approach on multiple systems, including a 26D system controlled by a neural network, showing significant scalability improvements without loss of rigor.
Scalable Verification of Neural Control Barrier Functions Using Linear Bound Propagation
Nov 09, 2025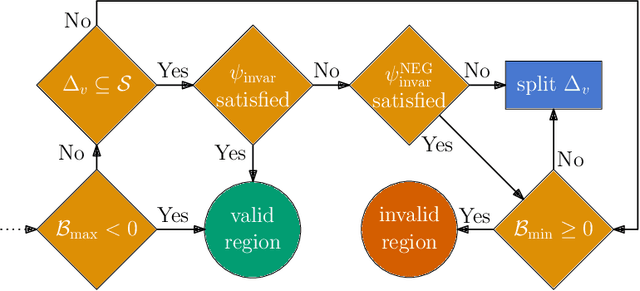
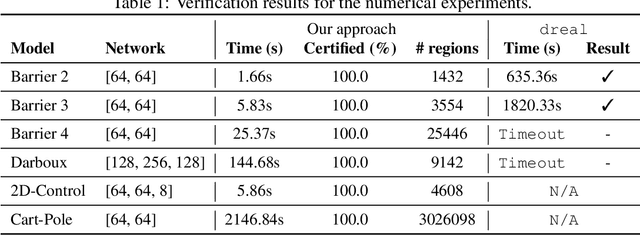
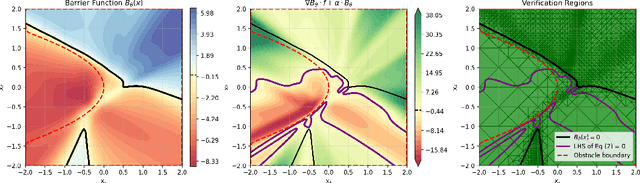
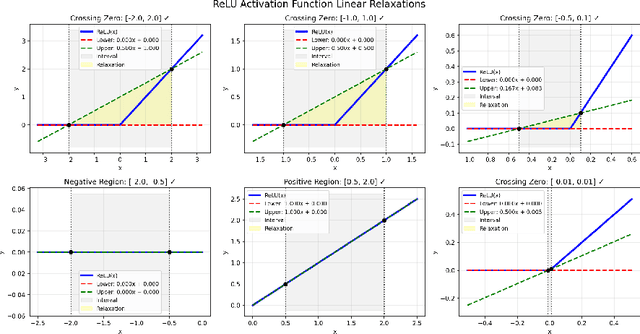
Control barrier functions (CBFs) are a popular tool for safety certification of nonlinear dynamical control systems. Recently, CBFs represented as neural networks have shown great promise due to their expressiveness and applicability to a broad class of dynamics and safety constraints. However, verifying that a trained neural network is indeed a valid CBF is a computational bottleneck that limits the size of the networks that can be used. To overcome this limitation, we present a novel framework for verifying neural CBFs based on piecewise linear upper and lower bounds on the conditions required for a neural network to be a CBF. Our approach is rooted in linear bound propagation (LBP) for neural networks, which we extend to compute bounds on the gradients of the network. Combined with McCormick relaxation, we derive linear upper and lower bounds on the CBF conditions, thereby eliminating the need for computationally expensive verification procedures. Our approach applies to arbitrary control-affine systems and a broad range of nonlinear activation functions. To reduce conservatism, we develop a parallelizable refinement strategy that adaptively refines the regions over which these bounds are computed. Our approach scales to larger neural networks than state-of-the-art verification procedures for CBFs, as demonstrated by our numerical experiments.
Certified Neural Approximations of Nonlinear Dynamics
May 21, 2025Neural networks hold great potential to act as approximate models of nonlinear dynamical systems, with the resulting neural approximations enabling verification and control of such systems. However, in safety-critical contexts, the use of neural approximations requires formal bounds on their closeness to the underlying system. To address this fundamental challenge, we propose a novel, adaptive, and parallelizable verification method based on certified first-order models. Our approach provides formal error bounds on the neural approximations of dynamical systems, allowing them to be safely employed as surrogates by interpreting the error bound as bounded disturbances acting on the approximated dynamics. We demonstrate the effectiveness and scalability of our method on a range of established benchmarks from the literature, showing that it outperforms the state-of-the-art. Furthermore, we highlight the flexibility of our framework by applying it to two novel scenarios not previously explored in this context: neural network compression and an autoencoder-based deep learning architecture for learning Koopman operators, both yielding compelling results.
Error Bounds for Deep Learning-based Uncertainty Propagation in SDEs
Oct 28, 2024



Stochastic differential equations are commonly used to describe the evolution of stochastic processes. The uncertainty of such processes is best represented by the probability density function (PDF), whose evolution is governed by the Fokker-Planck partial differential equation (FP-PDE). However, it is generally infeasible to solve the FP-PDE in closed form. In this work, we show that physics-informed neural networks (PINNs) can be trained to approximate the solution PDF using existing methods. The main contribution is the analysis of the approximation error: we develop a theory to construct an arbitrary tight error bound with PINNs. In addition, we derive a practical error bound that can be efficiently constructed with existing training methods. Finally, we explain that this error-bound theory generalizes to approximate solutions of other linear PDEs. Several numerical experiments are conducted to demonstrate and validate the proposed methods.
Error Bounds For Gaussian Process Regression Under Bounded Support Noise With Applications To Safety Certification
Aug 16, 2024



Gaussian Process Regression (GPR) is a powerful and elegant method for learning complex functions from noisy data with a wide range of applications, including in safety-critical domains. Such applications have two key features: (i) they require rigorous error quantification, and (ii) the noise is often bounded and non-Gaussian due to, e.g., physical constraints. While error bounds for applying GPR in the presence of non-Gaussian noise exist, they tend to be overly restrictive and conservative in practice. In this paper, we provide novel error bounds for GPR under bounded support noise. Specifically, by relying on concentration inequalities and assuming that the latent function has low complexity in the reproducing kernel Hilbert space (RKHS) corresponding to the GP kernel, we derive both probabilistic and deterministic bounds on the error of the GPR. We show that these errors are substantially tighter than existing state-of-the-art bounds and are particularly well-suited for GPR with neural network kernels, i.e., Deep Kernel Learning (DKL). Furthermore, motivated by applications in safety-critical domains, we illustrate how these bounds can be combined with stochastic barrier functions to successfully quantify the safety probability of an unknown dynamical system from finite data. We validate the efficacy of our approach through several benchmarks and comparisons against existing bounds. The results show that our bounds are consistently smaller, and that DKLs can produce error bounds tighter than sample noise, significantly improving the safety probability of control systems.
Finite Neural Networks as Mixtures of Gaussian Processes: From Provable Error Bounds to Prior Selection
Jul 26, 2024Infinitely wide or deep neural networks (NNs) with independent and identically distributed (i.i.d.) parameters have been shown to be equivalent to Gaussian processes. Because of the favorable properties of Gaussian processes, this equivalence is commonly employed to analyze neural networks and has led to various breakthroughs over the years. However, neural networks and Gaussian processes are equivalent only in the limit; in the finite case there are currently no methods available to approximate a trained neural network with a Gaussian model with bounds on the approximation error. In this work, we present an algorithmic framework to approximate a neural network of finite width and depth, and with not necessarily i.i.d. parameters, with a mixture of Gaussian processes with error bounds on the approximation error. In particular, we consider the Wasserstein distance to quantify the closeness between probabilistic models and, by relying on tools from optimal transport and Gaussian processes, we iteratively approximate the output distribution of each layer of the neural network as a mixture of Gaussian processes. Crucially, for any NN and $\epsilon >0$ our approach is able to return a mixture of Gaussian processes that is $\epsilon$-close to the NN at a finite set of input points. Furthermore, we rely on the differentiability of the resulting error bound to show how our approach can be employed to tune the parameters of a NN to mimic the functional behavior of a given Gaussian process, e.g., for prior selection in the context of Bayesian inference. We empirically investigate the effectiveness of our results on both regression and classification problems with various neural network architectures. Our experiments highlight how our results can represent an important step towards understanding neural network predictions and formally quantifying their uncertainty.
Data-Driven Permissible Safe Control with Barrier Certificates
Apr 30, 2024This paper introduces a method of identifying a maximal set of safe strategies from data for stochastic systems with unknown dynamics using barrier certificates. The first step is learning the dynamics of the system via Gaussian process (GP) regression and obtaining probabilistic errors for this estimate. Then, we develop an algorithm for constructing piecewise stochastic barrier functions to find a maximal permissible strategy set using the learned GP model, which is based on sequentially pruning the worst controls until a maximal set is identified. The permissible strategies are guaranteed to maintain probabilistic safety for the true system. This is especially important for learning-enabled systems, because a rich strategy space enables additional data collection and complex behaviors while remaining safe. Case studies on linear and nonlinear systems demonstrate that increasing the size of the dataset for learning the system grows the permissible strategy set.