 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Robustness Verification for Spatio-Temporal Neural Networks
Jun 08, 2026With AI increasingly deployed in safety-critical systems, providing formal robustness guarantees for the underlying models is essential. Existing verification methods either rely on overly conservative approximations or incur prohibitive computational costs. For example, the use of lp-norm perturbations in video settings encodes the belief that the adversary can inject noise in every video frame. In practice, adversarial perturbations exhibit structured spatial and temporal correlations, constrained to lower-dimensional, semantically meaningful subspaces. In this work, we study robustness verification of 3D CNNs processing video and volumetric inputs, targeting applications in action recognition (UCF-101), autonomous driving (Udacity), and medical imaging (MedMNIST) exploiting realistic assumptions on adversarial strength by modelling them as spatio-temporal constraints - where the attacker can modify either a subset of frames or patches within a set of consecutive frames. We demonstrate that modelling realistic constraints enables tighter approximations. We introduce Spatio-Temporal Bound Propagation (STBP), a verification framework that computes an exact closed-form characterization of the first convolutional layer and propagates certified bounds through subsequent layers using scalable approximations. Computing the exact closed form provides the tightest bounds for the first convolutional layer. Thus, we utilise approximation methods in the remainder of the network. To spur further progress in this field, we propose ST-Bench, a verification benchmark for autonomous driving and activity recognition, to systematically evaluate verifiable robustness. Compared to existing verification-based approaches, STBP provides stronger robustness guarantees with significantly improved scalability, achieving 1.7x higher certified robust accuracy under identical perturbation budgets.
SafeAdapt: Provably Safe Policy Updates in Deep Reinforcement Learning
Apr 10, 2026Safety guarantees are a prerequisite to the deployment of reinforcement learning (RL) agents in safety-critical tasks. Often, deployment environments exhibit non-stationary dynamics or are subject to changing performance goals, requiring updates to the learned policy. This leads to a fundamental challenge: how to update an RL policy while preserving its safety properties on previously encountered tasks? The majority of current approaches either do not provide formal guarantees or verify policy safety only a posteriori. We propose a novel a priori approach to safe policy updates in continual RL by introducing the Rashomon set: a region in policy parameter space certified to meet safety constraints within the demonstration data distribution. We then show that one can provide formal, provable guarantees for arbitrary RL algorithms used to update a policy by projecting their updates onto the Rashomon set. Empirically, we validate this approach across grid-world navigation environments (Frozen Lake and Poisoned Apple) where we guarantee an a priori provably deterministic safety on the source task during downstream adaptation. In contrast, we observe that regularisation-based baselines experience catastrophic forgetting of safety constraints while our approach enables strong adaptation with provable guarantees that safety is preserved.
Variational Routing: A Scalable Bayesian Framework for Calibrated Mixture-of-Experts Transformers
Mar 10, 2026Foundation models are increasingly being deployed in contexts where understanding the uncertainty of their outputs is critical to ensuring responsible deployment. While Bayesian methods offer a principled approach to uncertainty quantification, their computational overhead renders their use impractical for training or inference at foundation model scale. State-of-the-art models achieve parameter counts in the trillions through carefully engineered sparsity including Mixture-of-Experts (MoE) layers. In this work, we demonstrate calibrated uncertainty at scale by introducing Variational Mixture-of-Experts Routing (VMoER), a structured Bayesian approach for modelling uncertainty in MoE layers. VMoER confines Bayesian inference to the expert-selection stage which is typically done by a deterministic routing network. We instantiate VMoER using two inference strategies: amortised variational inference over routing logits and inferring a temperature parameter for stochastic expert selection. Across tested foundation models, VMoER improves routing stability under noise by 38\%, reduces calibration error by 94\%, and increases out-of-distribution AUROC by 12\%, while incurring less than 1\% additional FLOPs. These results suggest VMoER offers a scalable path toward robust and uncertainty-aware foundation models.
Towards Poisoning Robustness Certification for Natural Language Generation
Feb 10, 2026Understanding the reliability of natural language generation is critical for deploying foundation models in security-sensitive domains. While certified poisoning defenses provide provable robustness bounds for classification tasks, they are fundamentally ill-equipped for autoregressive generation: they cannot handle sequential predictions or the exponentially large output space of language models. To establish a framework for certified natural language generation, we formalize two security properties: stability (robustness to any change in generation) and validity (robustness to targeted, harmful changes in generation). We introduce Targeted Partition Aggregation (TPA), the first algorithm to certify validity/targeted attacks by computing the minimum poisoning budget needed to induce a specific harmful class, token, or phrase. Further, we extend TPA to provide tighter guarantees for multi-turn generations using mixed integer linear programming (MILP). Empirically, we demonstrate TPA's effectiveness across diverse settings including: certifying validity of agent tool-calling when adversaries modify up to 0.5% of the dataset and certifying 8-token stability horizons in preference-based alignment. Though inference-time latency remains an open challenge, our contributions enable certified deployment of language models in security-critical applications.
Abstract Gradient Training: A Unified Certification Framework for Data Poisoning, Unlearning, and Differential Privacy
Nov 12, 2025The impact of inference-time data perturbation (e.g., adversarial attacks) has been extensively studied in machine learning, leading to well-established certification techniques for adversarial robustness. In contrast, certifying models against training data perturbations remains a relatively under-explored area. These perturbations can arise in three critical contexts: adversarial data poisoning, where an adversary manipulates training samples to corrupt model performance; machine unlearning, which requires certifying model behavior under the removal of specific training data; and differential privacy, where guarantees must be given with respect to substituting individual data points. This work introduces Abstract Gradient Training (AGT), a unified framework for certifying robustness of a given model and training procedure to training data perturbations, including bounded perturbations, the removal of data points, and the addition of new samples. By bounding the reachable set of parameters, i.e., establishing provable parameter-space bounds, AGT provides a formal approach to analyzing the behavior of models trained via first-order optimization methods.
Model Guidance via Robust Feature Attribution
Jun 24, 2025Controlling the patterns a model learns is essential to preventing reliance on irrelevant or misleading features. Such reliance on irrelevant features, often called shortcut features, has been observed across domains, including medical imaging and natural language processing, where it may lead to real-world harms. A common mitigation strategy leverages annotations (provided by humans or machines) indicating which features are relevant or irrelevant. These annotations are compared to model explanations, typically in the form of feature salience, and used to guide the loss function during training. Unfortunately, recent works have demonstrated that feature salience methods are unreliable and therefore offer a poor signal to optimize. In this work, we propose a simplified objective that simultaneously optimizes for explanation robustness and mitigation of shortcut learning. Unlike prior objectives with similar aims, we demonstrate theoretically why our approach ought to be more effective. Across a comprehensive series of experiments, we show that our approach consistently reduces test-time misclassifications by 20% compared to state-of-the-art methods. We also extend prior experimental settings to include natural language processing tasks. Additionally, we conduct novel ablations that yield practical insights, including the relative importance of annotation quality over quantity. Code for our method and experiments is available at: https://github.com/Mihneaghitu/ModelGuidanceViaRobustFeatureAttribution.
Certificates of Differential Privacy and Unlearning for Gradient-Based Training
Jun 19, 2024Proper data stewardship requires that model owners protect the privacy of individuals' data used during training. Whether through anonymization with differential privacy or the use of unlearning in non-anonymized settings, the gold-standard techniques for providing privacy guarantees can come with significant performance penalties or be too weak to provide practical assurances. In part, this is due to the fact that the guarantee provided by differential privacy represents the worst-case privacy leakage for any individual, while the true privacy leakage of releasing the prediction for a given individual might be substantially smaller or even, as we show, non-existent. This work provides a novel framework based on convex relaxations and bounds propagation that can compute formal guarantees (certificates) that releasing specific predictions satisfies $\epsilon=0$ privacy guarantees or do not depend on data that is subject to an unlearning request. Our framework offers a new verification-centric approach to privacy and unlearning guarantees, that can be used to further engender user trust with tighter privacy guarantees, provide formal proofs of robustness to certain membership inference attacks, identify potentially vulnerable records, and enhance current unlearning approaches. We validate the effectiveness of our approach on tasks from financial services, medical imaging, and natural language processing.
Certified Robustness to Data Poisoning in Gradient-Based Training
Jun 09, 2024Modern machine learning pipelines leverage large amounts of public data, making it infeasible to guarantee data quality and leaving models open to poisoning and backdoor attacks. However, provably bounding model behavior under such attacks remains an open problem. In this work, we address this challenge and develop the first framework providing provable guarantees on the behavior of models trained with potentially manipulated data. In particular, our framework certifies robustness against untargeted and targeted poisoning as well as backdoor attacks for both input and label manipulations. Our method leverages convex relaxations to over-approximate the set of all possible parameter updates for a given poisoning threat model, allowing us to bound the set of all reachable parameters for any gradient-based learning algorithm. Given this set of parameters, we provide bounds on worst-case behavior, including model performance and backdoor success rate. We demonstrate our approach on multiple real-world datasets from applications including energy consumption, medical imaging, and autonomous driving.
Certification of Distributional Individual Fairness
Nov 20, 2023Providing formal guarantees of algorithmic fairness is of paramount importance to socially responsible deployment of machine learning algorithms. In this work, we study formal guarantees, i.e., certificates, for individual fairness (IF) of neural networks. We start by introducing a novel convex approximation of IF constraints that exponentially decreases the computational cost of providing formal guarantees of local individual fairness. We highlight that prior methods are constrained by their focus on global IF certification and can therefore only scale to models with a few dozen hidden neurons, thus limiting their practical impact. We propose to certify distributional individual fairness which ensures that for a given empirical distribution and all distributions within a $\gamma$-Wasserstein ball, the neural network has guaranteed individually fair predictions. Leveraging developments in quasi-convex optimization, we provide novel and efficient certified bounds on distributional individual fairness and show that our method allows us to certify and regularize neural networks that are several orders of magnitude larger than those considered by prior works. Moreover, we study real-world distribution shifts and find our bounds to be a scalable, practical, and sound source of IF guarantees.
Probabilistic Reach-Avoid for Bayesian Neural Networks
Oct 03, 2023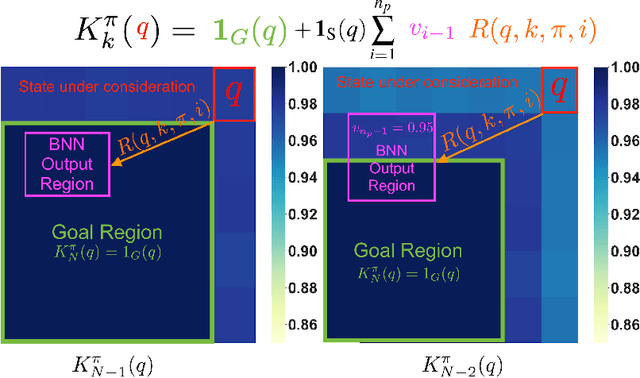
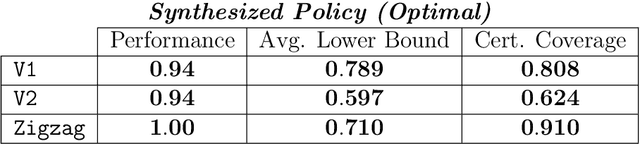
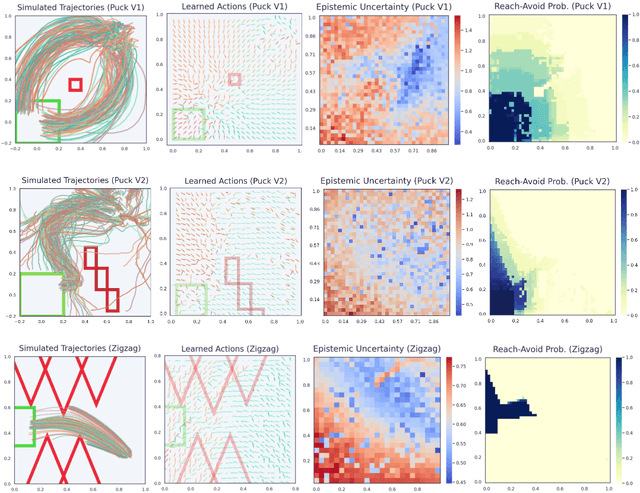
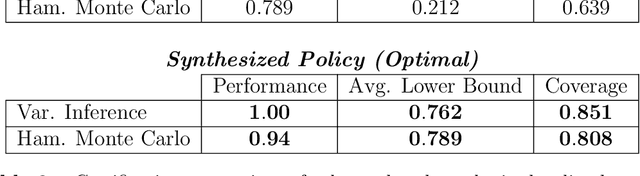
Model-based reinforcement learning seeks to simultaneously learn the dynamics of an unknown stochastic environment and synthesise an optimal policy for acting in it. Ensuring the safety and robustness of sequential decisions made through a policy in such an environment is a key challenge for policies intended for safety-critical scenarios. In this work, we investigate two complementary problems: first, computing reach-avoid probabilities for iterative predictions made with dynamical models, with dynamics described by Bayesian neural network (BNN); second, synthesising control policies that are optimal with respect to a given reach-avoid specification (reaching a "target" state, while avoiding a set of "unsafe" states) and a learned BNN model. Our solution leverages interval propagation and backward recursion techniques to compute lower bounds for the probability that a policy's sequence of actions leads to satisfying the reach-avoid specification. Such computed lower bounds provide safety certification for the given policy and BNN model. We then introduce control synthesis algorithms to derive policies maximizing said lower bounds on the safety probability. We demonstrate the effectiveness of our method on a series of control benchmarks characterized by learned BNN dynamics models. On our most challenging benchmark, compared to purely data-driven policies the optimal synthesis algorithm is able to provide more than a four-fold increase in the number of certifiable states and more than a three-fold increase in the average guaranteed reach-avoid probability.