 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain and Range Aware Synthetic Negatives Generation for Knowledge Graph Embedding Models
Nov 22, 2024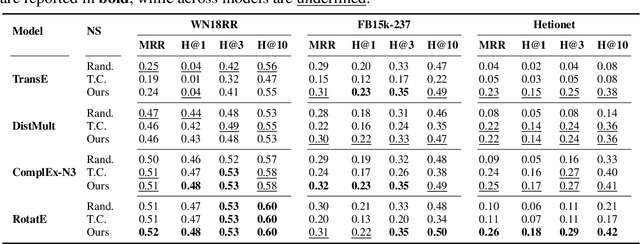
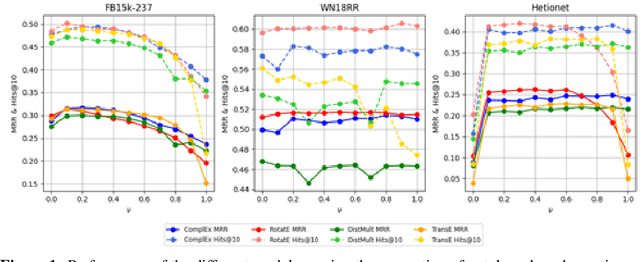

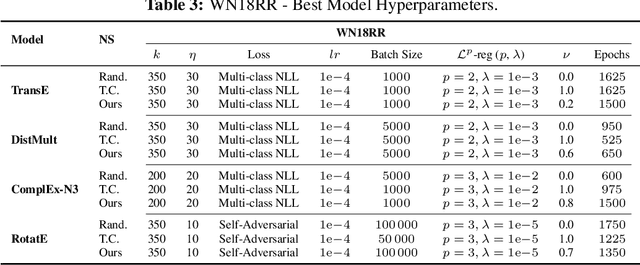
Knowledge Graph Embedding models, representing entities and edges in a low-dimensional space, have been extremely successful at solving tasks related to completing and exploring Knowledge Graphs (KGs). One of the key aspects of training most of these models is teaching to discriminate between true statements positives and false ones (negatives). However, the way in which negatives can be defined is not trivial, as facts missing from the KG are not necessarily false and a set of ground truth negatives is hardly ever given. This makes synthetic negative generation a necessity. Different generation strategies can heavily affect the quality of the embeddings, making it a primary aspect to consider. We revamp a strategy that generates corruptions during training respecting the domain and range of relations, we extend its capabilities and we show our methods bring substantial improvement (+10% MRR) for standard benchmark datasets and over +150% MRR for a larger ontology-backed dataset.
Veni, Vidi, Vici: Solving the Myriad of Challenges before Knowledge Graph Learning
Feb 08, 2024
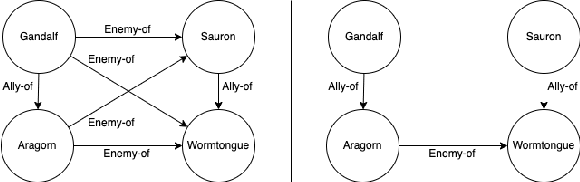
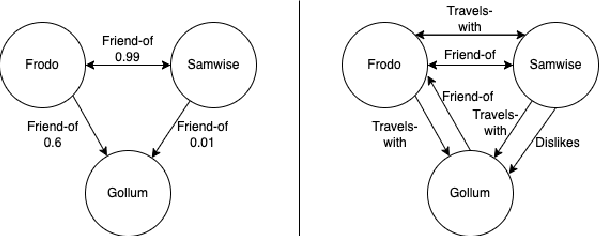
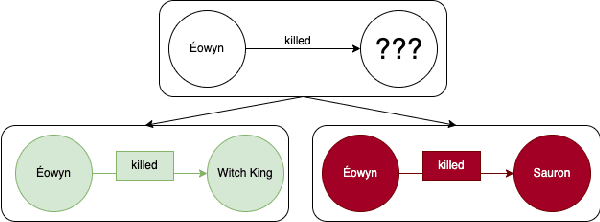
Knowledge Graphs (KGs) have become increasingly common for representing large-scale linked data. However, their immense size has required graph learning systems to assist humans in analysis, interpretation, and pattern detection. While there have been promising results for researcher- and clinician- empowerment through a variety of KG learning systems, we identify four key deficiencies in state-of-the-art graph learning that simultaneously limit KG learning performance and diminish the ability of humans to interface optimally with these learning systems. These deficiencies are: 1) lack of expert knowledge integration, 2) instability to node degree extremity in the KG, 3) lack of consideration for uncertainty and relevance while learning, and 4) lack of explainability. Furthermore, we characterise state-of-the-art attempts to solve each of these problems and note that each attempt has largely been isolated from attempts to solve the other problems. Through a formalisation of these problems and a review of the literature that addresses them, we adopt the position that not only are deficiencies in these four key areas holding back human-KG empowerment, but that the divide-and-conquer approach to solving these problems as individual units rather than a whole is a significant barrier to the interface between humans and KG learning systems. We propose that it is only through integrated, holistic solutions to the limitations of KG learning systems that human and KG learning co-empowerment will be efficiently affected. We finally present our "Veni, Vidi, Vici" framework that sets a roadmap for effectively and efficiently shifting to a holistic co-empowerment model in both the KG learning and the broader machine learning domain.
KGEx: Explaining Knowledge Graph Embeddings via Subgraph Sampling and Knowledge Distillation
Oct 02, 2023Despite being the go-to choice for link prediction on knowledge graphs, research on interpretability of knowledge graph embeddings (KGE) has been relatively unexplored. We present KGEx, a novel post-hoc method that explains individual link predictions by drawing inspiration from surrogate models research. Given a target triple to predict, KGEx trains surrogate KGE models that we use to identify important training triples. To gauge the impact of a training triple, we sample random portions of the target triple neighborhood and we train multiple surrogate KGE models on each of them. To ensure faithfulness, each surrogate is trained by distilling knowledge from the original KGE model. We then assess how well surrogates predict the target triple being explained, the intuition being that those leading to faithful predictions have been trained on impactful neighborhood samples. Under this assumption, we then harvest triples that appear frequently across impactful neighborhoods. We conduct extensive experiments on two publicly available datasets, to demonstrate that KGEx is capable of providing explanations faithful to the black-box model.
Robust Explanation Constraints for Neural Networks
Dec 16, 2022Post-hoc explanation methods are used with the intent of providing insights about neural networks and are sometimes said to help engender trust in their outputs. However, popular explanations methods have been found to be fragile to minor perturbations of input features or model parameters. Relying on constraint relaxation techniques from non-convex optimization, we develop a method that upper-bounds the largest change an adversary can make to a gradient-based explanation via bounded manipulation of either the input features or model parameters. By propagating a compact input or parameter set as symbolic intervals through the forwards and backwards computations of the neural network we can formally certify the robustness of gradient-based explanations. Our bounds are differentiable, hence we can incorporate provable explanation robustness into neural network training. Empirically, our method surpasses the robustness provided by previous heuristic approaches. We find that our training method is the only method able to learn neural networks with certificates of explanation robustness across all six datasets tested.
Explaining Link Predictions in Knowledge Graph Embedding Models with Influential Examples
Dec 05, 2022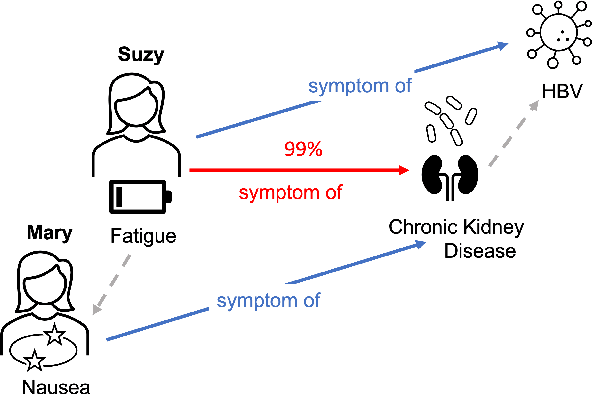
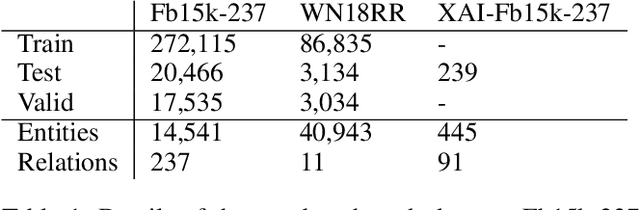
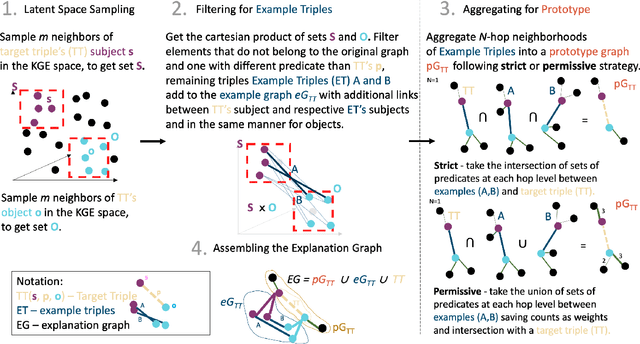
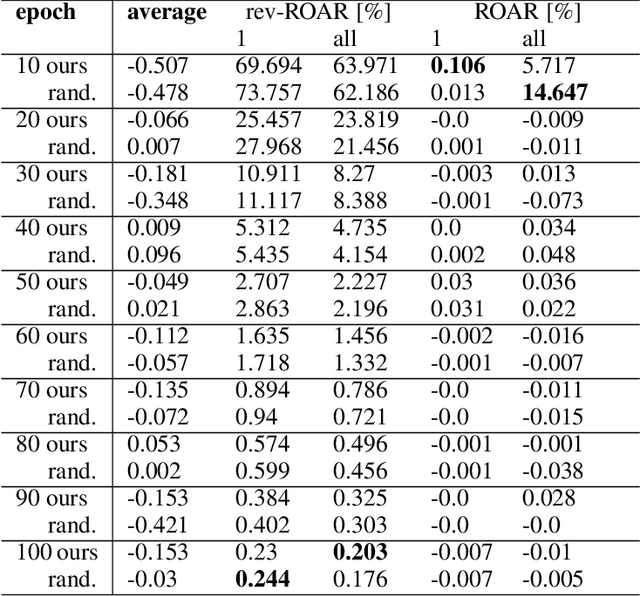
We study the problem of explaining link predictions in the Knowledge Graph Embedding (KGE) models. We propose an example-based approach that exploits the latent space representation of nodes and edges in a knowledge graph to explain predictions. We evaluated the importance of identified triples by observing progressing degradation of model performance upon influential triples removal. Our experiments demonstrate that this approach to generate explanations outperforms baselines on KGE models for two publicly available datasets.
Machine Learning-Assisted Recurrence Prediction for Early-Stage Non-Small-Cell Lung Cancer Patients
Nov 17, 2022



Background: Stratifying cancer patients according to risk of relapse can personalize their care. In this work, we provide an answer to the following research question: How to utilize machine learning to estimate probability of relapse in early-stage non-small-cell lung cancer patients? Methods: For predicting relapse in 1,387 early-stage (I-II), non-small-cell lung cancer (NSCLC) patients from the Spanish Lung Cancer Group data (65.7 average age, 24.8% females, 75.2% males) we train tabular and graph machine learning models. We generate automatic explanations for the predictions of such models. For models trained on tabular data, we adopt SHAP local explanations to gauge how each patient feature contributes to the predicted outcome. We explain graph machine learning predictions with an example-based method that highlights influential past patients. Results: Machine learning models trained on tabular data exhibit a 76% accuracy for the Random Forest model at predicting relapse evaluated with a 10-fold cross-validation (model was trained 10 times with different independent sets of patients in test, train and validation sets, the reported metrics are averaged over these 10 test sets). Graph machine learning reaches 68% accuracy over a 200-patient, held-out test set, calibrated on a held-out set of 100 patients. Conclusions: Our results show that machine learning models trained on tabular and graph data can enable objective, personalised and reproducible prediction of relapse and therefore, disease outcome in patients with early-stage NSCLC. With further prospective and multisite validation, and additional radiological and molecular data, this prognostic model could potentially serve as a predictive decision support tool for deciding the use of adjuvant treatments in early-stage lung cancer. Keywords: Non-Small-Cell Lung Cancer, Tumor Recurrence Prediction, Machine Learning
Poisoning Knowledge Graph Embeddings via Relation Inference Patterns
Nov 11, 2021

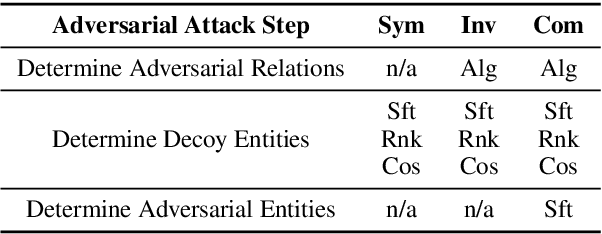
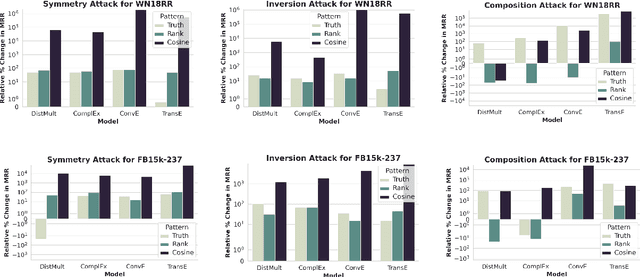
We study the problem of generating data poisoning attacks against Knowledge Graph Embedding (KGE) models for the task of link prediction in knowledge graphs. To poison KGE models, we propose to exploit their inductive abilities which are captured through the relationship patterns like symmetry, inversion and composition in the knowledge graph. Specifically, to degrade the model's prediction confidence on target facts, we propose to improve the model's prediction confidence on a set of decoy facts. Thus, we craft adversarial additions that can improve the model's prediction confidence on decoy facts through different inference patterns. Our experiments demonstrate that the proposed poisoning attacks outperform state-of-art baselines on four KGE models for two publicly available datasets. We also find that the symmetry pattern based attacks generalize across all model-dataset combinations which indicates the sensitivity of KGE models to this pattern.
Adversarial Attacks on Knowledge Graph Embeddings via Instance Attribution Methods
Nov 04, 2021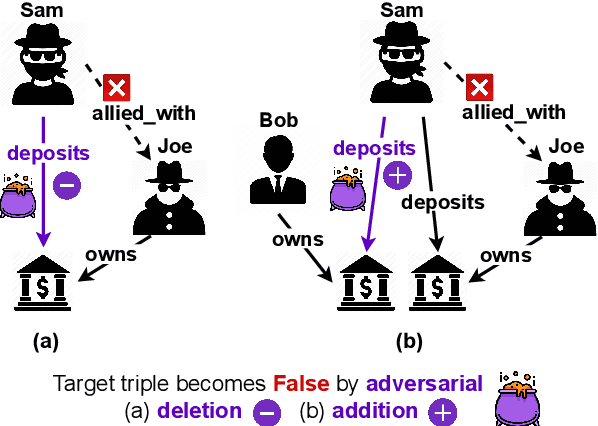

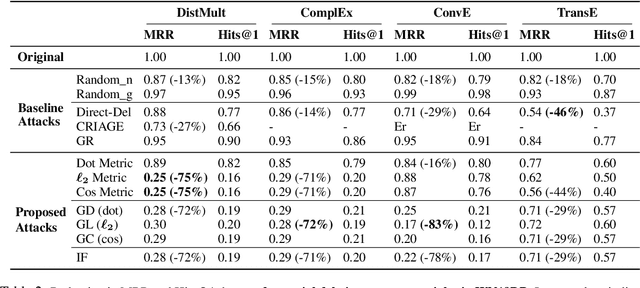
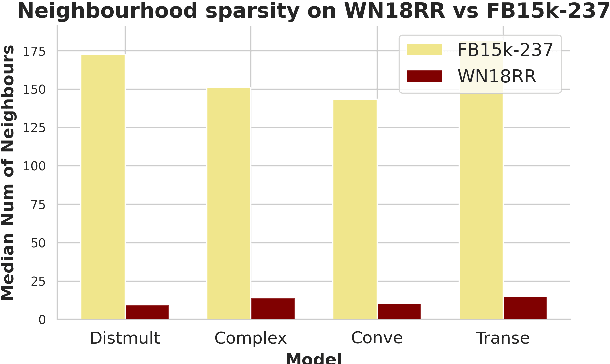
Despite the widespread use of Knowledge Graph Embeddings (KGE), little is known about the security vulnerabilities that might disrupt their intended behaviour. We study data poisoning attacks against KGE models for link prediction. These attacks craft adversarial additions or deletions at training time to cause model failure at test time. To select adversarial deletions, we propose to use the model-agnostic instance attribution methods from Interpretable Machine Learning, which identify the training instances that are most influential to a neural model's predictions on test instances. We use these influential triples as adversarial deletions. We further propose a heuristic method to replace one of the two entities in each influential triple to generate adversarial additions. Our experiments show that the proposed strategies outperform the state-of-art data poisoning attacks on KGE models and improve the MRR degradation due to the attacks by up to 62% over the baselines.
Learning Embeddings from Knowledge Graphs With Numeric Edge Attributes
May 18, 2021
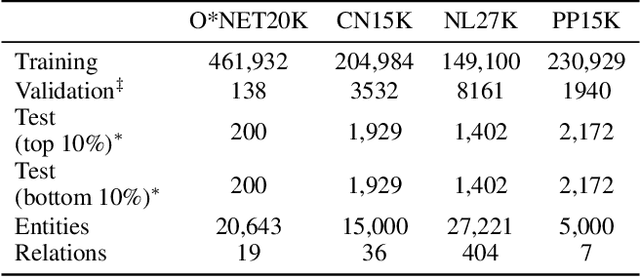

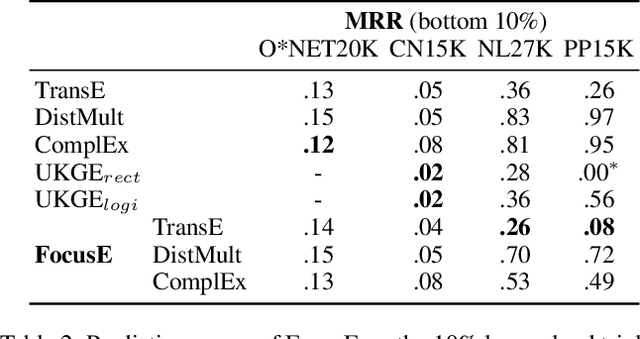
Numeric values associated to edges of a knowledge graph have been used to represent uncertainty, edge importance, and even out-of-band knowledge in a growing number of scenarios, ranging from genetic data to social networks. Nevertheless, traditional knowledge graph embedding models are not designed to capture such information, to the detriment of predictive power. We propose a novel method that injects numeric edge attributes into the scoring layer of a traditional knowledge graph embedding architecture. Experiments with publicly available numeric-enriched knowledge graphs show that our method outperforms traditional numeric-unaware baselines as well as the recent UKGE model.
Generating Interpretable Counterfactual Explanations By Implicit Minimisation of Epistemic and Aleatoric Uncertainties
Mar 16, 2021
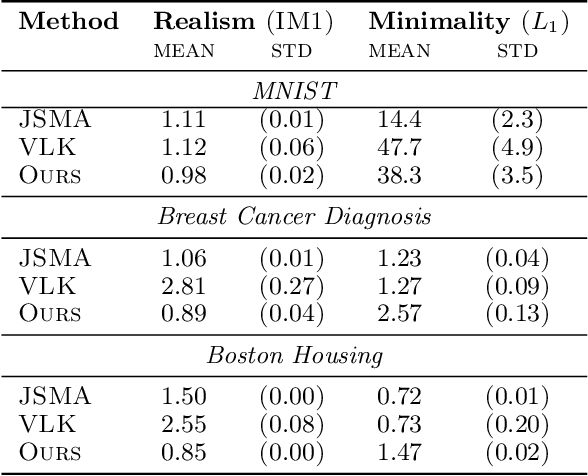


Counterfactual explanations (CEs) are a practical tool for demonstrating why machine learning classifiers make particular decisions. For CEs to be useful, it is important that they are easy for users to interpret. Existing methods for generating interpretable CEs rely on auxiliary generative models, which may not be suitable for complex datasets, and incur engineering overhead. We introduce a simple and fast method for generating interpretable CEs in a white-box setting without an auxiliary model, by using the predictive uncertainty of the classifier. Our experiments show that our proposed algorithm generates more interpretable CEs, according to IM1 scores, than existing methods. Additionally, our approach allows us to estimate the uncertainty of a CE, which may be important in safety-critical applications, such as those in the medical domain.
* 21 pages, 13 Figures