 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning-Assisted Recurrence Prediction for Early-Stage Non-Small-Cell Lung Cancer Patients
Nov 17, 2022



Background: Stratifying cancer patients according to risk of relapse can personalize their care. In this work, we provide an answer to the following research question: How to utilize machine learning to estimate probability of relapse in early-stage non-small-cell lung cancer patients? Methods: For predicting relapse in 1,387 early-stage (I-II), non-small-cell lung cancer (NSCLC) patients from the Spanish Lung Cancer Group data (65.7 average age, 24.8% females, 75.2% males) we train tabular and graph machine learning models. We generate automatic explanations for the predictions of such models. For models trained on tabular data, we adopt SHAP local explanations to gauge how each patient feature contributes to the predicted outcome. We explain graph machine learning predictions with an example-based method that highlights influential past patients. Results: Machine learning models trained on tabular data exhibit a 76% accuracy for the Random Forest model at predicting relapse evaluated with a 10-fold cross-validation (model was trained 10 times with different independent sets of patients in test, train and validation sets, the reported metrics are averaged over these 10 test sets). Graph machine learning reaches 68% accuracy over a 200-patient, held-out test set, calibrated on a held-out set of 100 patients. Conclusions: Our results show that machine learning models trained on tabular and graph data can enable objective, personalised and reproducible prediction of relapse and therefore, disease outcome in patients with early-stage NSCLC. With further prospective and multisite validation, and additional radiological and molecular data, this prognostic model could potentially serve as a predictive decision support tool for deciding the use of adjuvant treatments in early-stage lung cancer. Keywords: Non-Small-Cell Lung Cancer, Tumor Recurrence Prediction, Machine Learning
Method and System for Image Analysis to Detect Cancer
Aug 26, 2019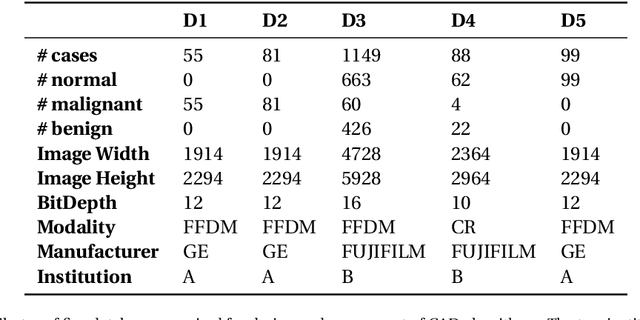
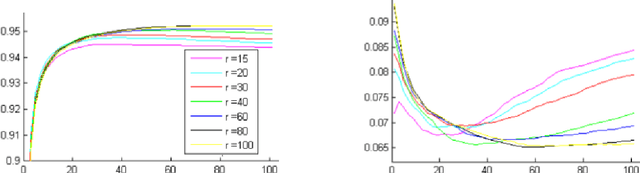

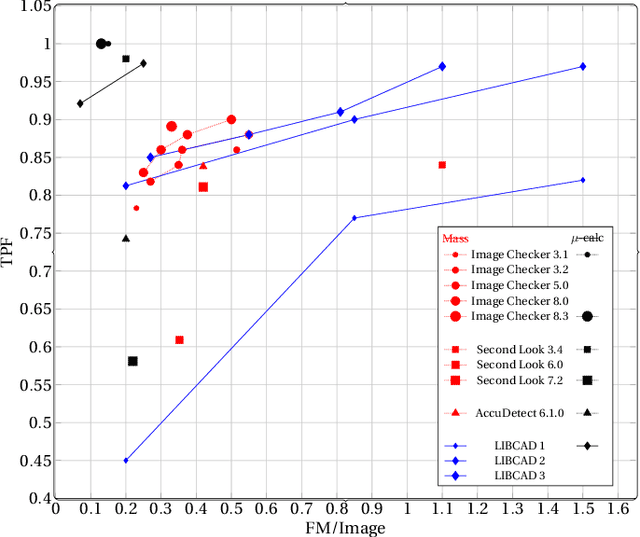
Breast cancer is the most common cancer and is the leading cause of cancer death among women worldwide. Detection of breast cancer, while it is still small and confined to the breast, provides the best chance of effective treatment. Computer Aided Detection (CAD) systems that detect cancer from mammograms will help in reducing the human errors that lead to missing breast carcinoma. Literature is rich of scientific papers for methods of CAD design, yet with no complete system architecture to deploy those methods. On the other hand, commercial CADs are developed and deployed only to vendors' mammography machines with no availability to public access. This paper presents a complete CAD; it is complete since it combines, on a hand, the rigor of algorithm design and assessment (method), and, on the other hand, the implementation and deployment of a system architecture for public accessibility (system). (1) We develop a novel algorithm for image enhancement so that mammograms acquired from any digital mammography machine look qualitatively of the same clarity to radiologists' inspection; and is quantitatively standardized for the detection algorithms. (2) We develop novel algorithms for masses and microcalcifications detection with accuracy superior to both literature results and the majority of approved commercial systems. (3) We design, implement, and deploy a system architecture that is computationally effective to allow for deploying these algorithms to cloud for public access.
Unsupervised Hierarchical Grouping of Knowledge Graph Entities
Aug 20, 2019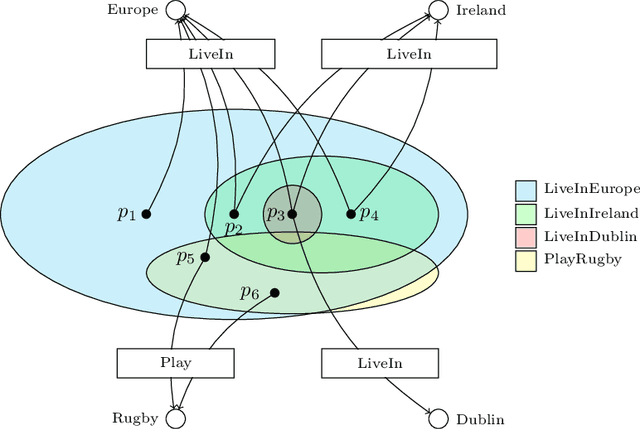
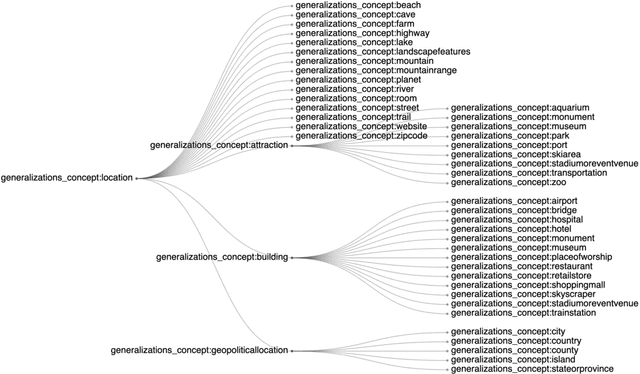

Knowledge graphs have attracted lots of attention in academic and industrial environments. Despite their usefulness, popular knowledge graphs suffer from incompleteness of information, especially in their type assertions. This has encouraged research in the automatic discovery of entity types. In this context, multiple works were developed to utilize logical inference on ontologies and statistical machine learning methods to learn type assertion in knowledge graphs. However, these approaches suffer from limited performance on noisy data, limited scalability and the dependence on labeled training samples. In this work, we propose a new unsupervised approach that learns to categorize entities into a hierarchy of named groups. We show that our approach is able to effectively learn entity groups using a scalable procedure in noisy and sparse datasets. We experiment our approach on a set of popular knowledge graph benchmarking datasets, and we publish a collection of the outcome group hierarchies.