 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Statistical Learning of Branch and Bound for Vehicle Routing Optimization
Oct 17, 2023



Recently, machine learning of the branch and bound algorithm has shown promise in approximating competent solutions to NP-hard problems. In this paper, we utilize and comprehensively compare the outcomes of three neural networks--graph convolutional neural network (GCNN), GraphSAGE, and graph attention network (GAT)--to solve the capacitated vehicle routing problem. We train these neural networks to emulate the decision-making process of the computationally expensive Strong Branching strategy. The neural networks are trained on six instances with distinct topologies from the CVRPLIB and evaluated on eight additional instances. Moreover, we reduced the minimum number of vehicles required to solve a CVRP instance to a bin-packing problem, which was addressed in a similar manner. Through rigorous experimentation, we found that this approach can match or improve upon the performance of the branch and bound algorithm with the Strong Branching strategy while requiring significantly less computational time. The source code that corresponds to our research findings and methodology is readily accessible and available for reference at the following web address: https://isotlaboratory.github.io/ml4vrp
UN-AVOIDS: Unsupervised and Nonparametric Approach for Visualizing Outliers and Invariant Detection Scoring
Nov 19, 2021
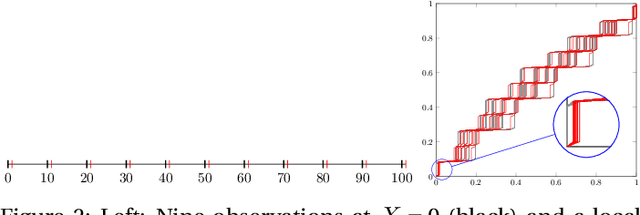
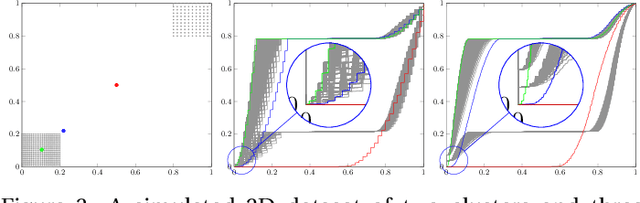

The visualization and detection of anomalies (outliers) are of crucial importance to many fields, particularly cybersecurity. Several approaches have been proposed in these fields, yet to the best of our knowledge, none of them has fulfilled both objectives, simultaneously or cooperatively, in one coherent framework. The visualization methods of these approaches were introduced for explaining the output of a detection algorithm, not for data exploration that facilitates a standalone visual detection. This is our point of departure: UN-AVOIDS, an unsupervised and nonparametric approach for both visualization (a human process) and detection (an algorithmic process) of outliers, that assigns invariant anomalous scores (normalized to $[0,1]$), rather than hard binary-decision. The main aspect of novelty of UN-AVOIDS is that it transforms data into a new space, which is introduced in this paper as neighborhood cumulative density function (NCDF), in which both visualization and detection are carried out. In this space, outliers are remarkably visually distinguishable, and therefore the anomaly scores assigned by the detection algorithm achieved a high area under the ROC curve (AUC). We assessed UN-AVOIDS on both simulated and two recently published cybersecurity datasets, and compared it to three of the most successful anomaly detection methods: LOF, IF, and FABOD. In terms of AUC, UN-AVOIDS was almost an overall winner. The article concludes by providing a preview of new theoretical and practical avenues for UN-AVOIDS. Among them is designing a visualization aided anomaly detection (VAAD), a type of software that aids analysts by providing UN-AVOIDS' detection algorithm (running in a back engine), NCDF visualization space (rendered to plots), along with other conventional methods of visualization in the original feature space, all of which are linked in one interactive environment.
Classifier Calibration: with implications to threat scores in cybersecurity
Feb 09, 2021
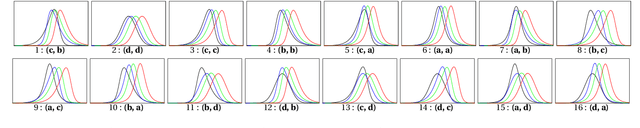
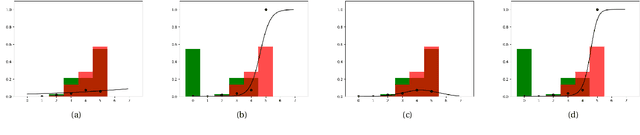
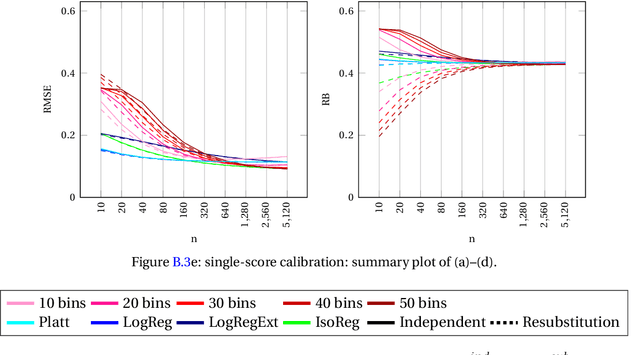
This paper explores the calibration of a classifier output score in binary classification problems. A calibrator is a function that maps the arbitrary classifier score, of a testing observation, onto $[0,1]$ to provide an estimate for the posterior probability of belonging to one of the two classes. Calibration is important for two reasons; first, it provides a meaningful score, that is the posterior probability; second, it puts the scores of different classifiers on the same scale for comparable interpretation. The paper presents three main contributions: (1) Introducing multi-score calibration, when more than one classifier provides a score for a single observation. (2) Introducing the idea that the classifier scores to a calibration process are nothing but features to a classifier, hence proposing extending the classifier scores to higher dimensions to boost the calibrator's performance. (3) Conducting a massive simulation study, in the order of 24,000 experiments, that incorporates different configurations, in addition to experimenting on two real datasets from the cybersecurity domain. The results show that there is no overall winner among the different calibrators and different configurations. However, general advices for practitioners include the following: the Platt's calibrator~\citep{Platt1999ProbabilisticOutputsForSupport}, a version of the logistic regression that decreases bias for a small sample size, has a very stable and acceptable performance among all experiments; our suggested multi-score calibration provides better performance than single score calibration in the majority of experiments, including the two real datasets. In addition, extending the scores can help in some experiments.
Machine Learning in Precision Medicine to Preserve Privacy via Encryption
Feb 05, 2021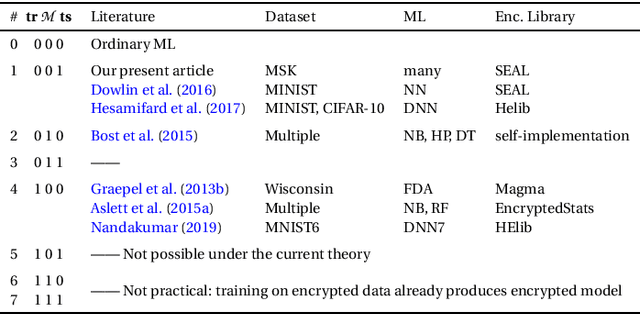
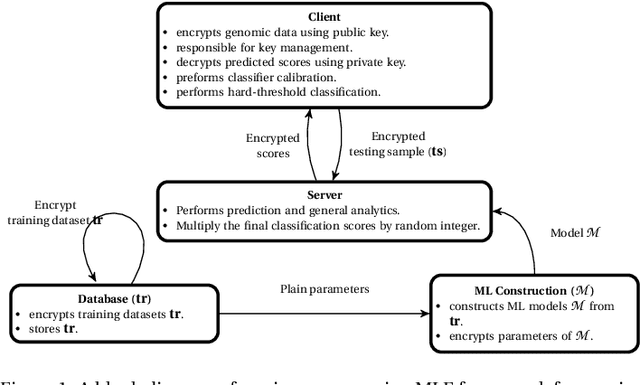


Precision medicine is an emerging approach for disease treatment and prevention that delivers personalized care to individual patients by considering their genetic makeups, medical histories, environments, and lifestyles. Despite the rapid advancement of precision medicine and its considerable promise, several underlying technological challenges remain unsolved. One such challenge of great importance is the security and privacy of precision health-related data, such as genomic data and electronic health records, which stifle collaboration and hamper the full potential of machine-learning (ML) algorithms. To preserve data privacy while providing ML solutions, this article makes three contributions. First, we propose a generic machine learning with encryption (MLE) framework, which we used to build an ML model that predicts cancer from one of the most recent comprehensive genomics datasets in the field. Second, our framework's prediction accuracy is slightly higher than that of the most recent studies conducted on the same dataset, yet it maintains the privacy of the patients' genomic data. Third, to facilitate the validation, reproduction, and extension of this work, we provide an open-source repository that contains the design and implementation of the framework, all the ML experiments and code, and the final predictive model deployed to a free cloud service.
Assessment of Multiple-Biomarker Classifiers: fundamental principles and a proposed strategy
Oct 30, 2019
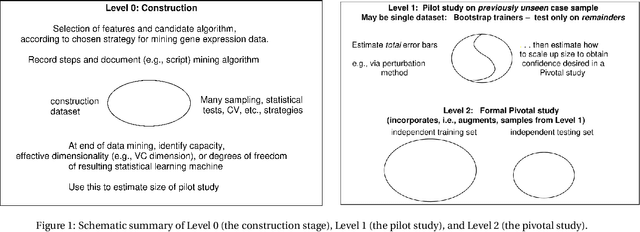
The multiple-biomarker classifier problem and its assessment are reviewed against the background of some fundamental principles from the field of statistical pattern recognition, machine learning, or the recently so-called "data science". A narrow reading of that literature has led many authors to neglect the contribution to the total uncertainty of performance assessment from the finite training sample. Yet the latter is a fundamental indicator of the stability of a classifier; thus its neglect may be contributing to the problematic status of many studies. A three-level strategy is proposed for moving forward in this field. The lowest level is that of construction, where candidate features are selected and the choice of classifier architecture is made. At that point, the effective dimensionality of the classifier is estimated and used to size the next level of analysis, a pilot study on previously unseen cases. The total (training and testing) uncertainty resulting from the pilot study is, in turn, used to size the highest level of analysis, a pivotal study with a target level of uncertainty. Some resources available in the literature for implementing this approach are reviewed. Although the concepts explained in the present article may be fundamental and straightforward for many researchers in the machine learning community they are subtle for many practitioners, for whom we provided a general advice for the best practice in \cite{Shi2010MAQCII} and elaborate here in the present paper.
Method and System for Image Analysis to Detect Cancer
Aug 26, 2019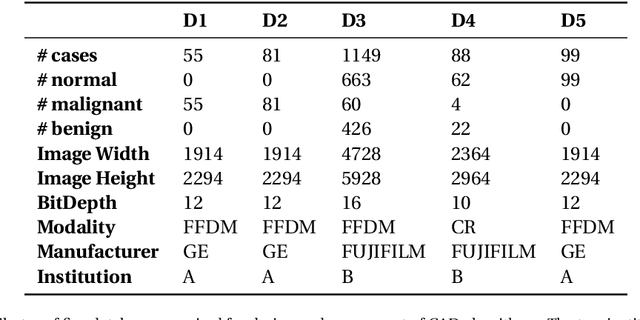
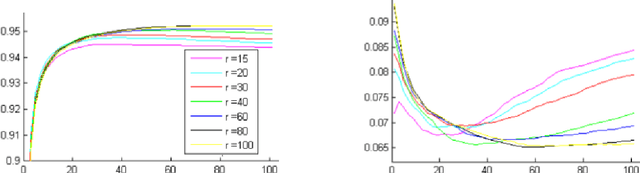

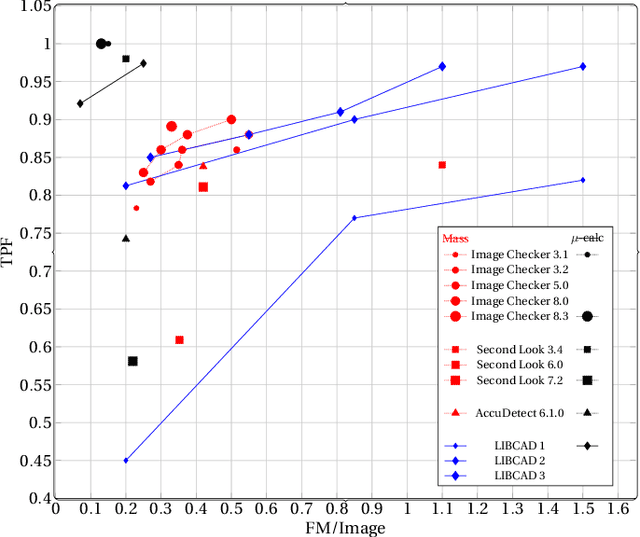
Breast cancer is the most common cancer and is the leading cause of cancer death among women worldwide. Detection of breast cancer, while it is still small and confined to the breast, provides the best chance of effective treatment. Computer Aided Detection (CAD) systems that detect cancer from mammograms will help in reducing the human errors that lead to missing breast carcinoma. Literature is rich of scientific papers for methods of CAD design, yet with no complete system architecture to deploy those methods. On the other hand, commercial CADs are developed and deployed only to vendors' mammography machines with no availability to public access. This paper presents a complete CAD; it is complete since it combines, on a hand, the rigor of algorithm design and assessment (method), and, on the other hand, the implementation and deployment of a system architecture for public accessibility (system). (1) We develop a novel algorithm for image enhancement so that mammograms acquired from any digital mammography machine look qualitatively of the same clarity to radiologists' inspection; and is quantitatively standardized for the detection algorithms. (2) We develop novel algorithms for masses and microcalcifications detection with accuracy superior to both literature results and the majority of approved commercial systems. (3) We design, implement, and deploy a system architecture that is computationally effective to allow for deploying these algorithms to cloud for public access.
Prudence When Assuming Normality: an advice for machine learning practitioners
Aug 14, 2019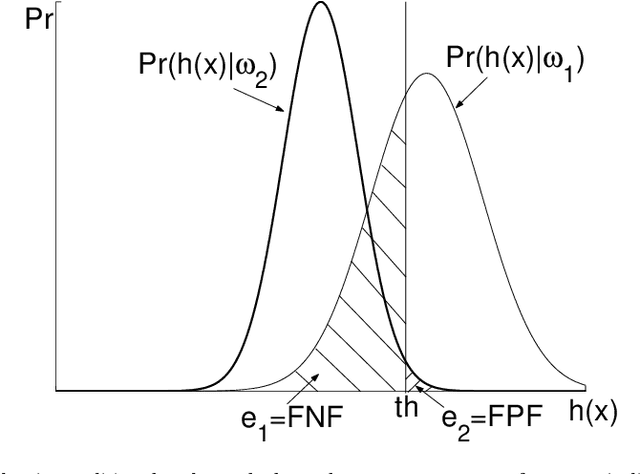
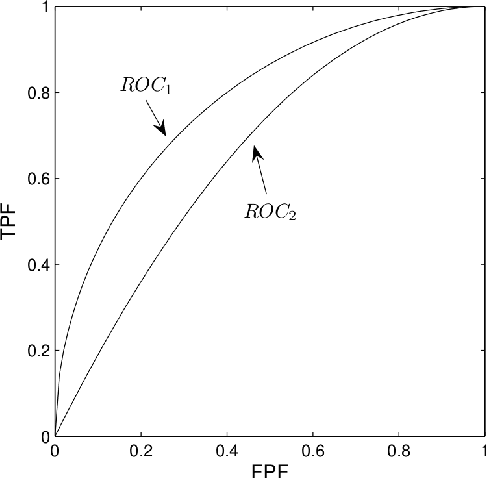
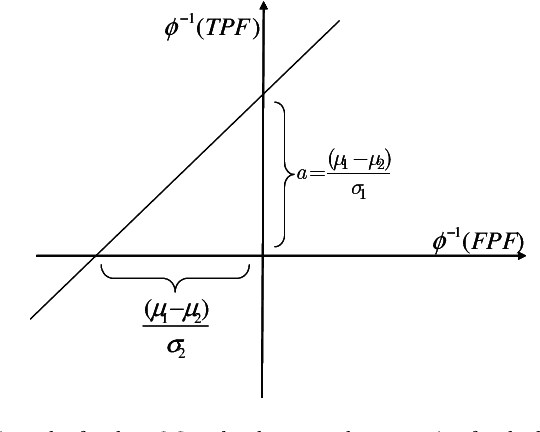
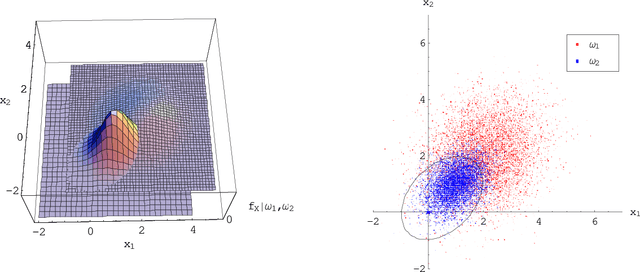
In a binary classification problem the feature vector (predictor) is the input to a scoring function that produces a decision value (score), which is compared to a particular chosen threshold to provide a final class prediction (output). Although the normal assumption of the scoring function is important in many applications, sometimes it is severely violated even under the simple multinormal assumption of the feature vector. This article proves this result mathematically with a counter example to provide an advice for practitioners to avoid blind assumptions of normality. On the other hand, the article provides a set of experiments that illustrate some of the expected and well-behaved results of the Area Under the ROC curve (AUC) under the multinormal assumption of the feature vector. Therefore, the message of the article is not to avoid the normal assumption of either the input feature vector or the output scoring function; however, a prudence is needed when adopting either of both.
Nested Cavity Classifier: performance and remedy
Aug 08, 2019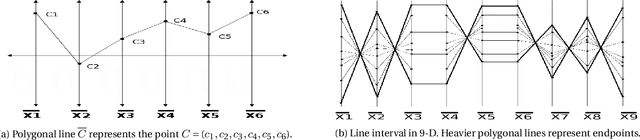
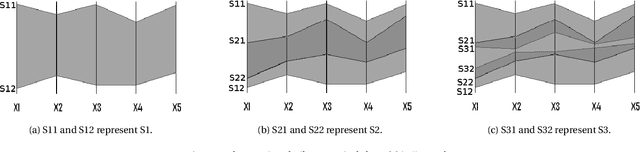
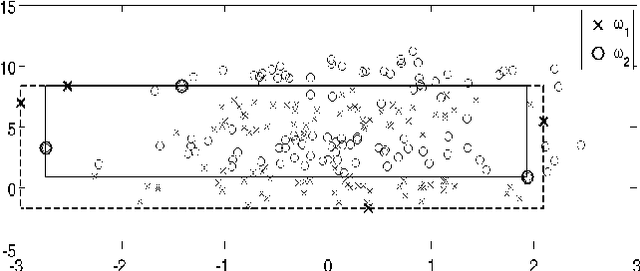
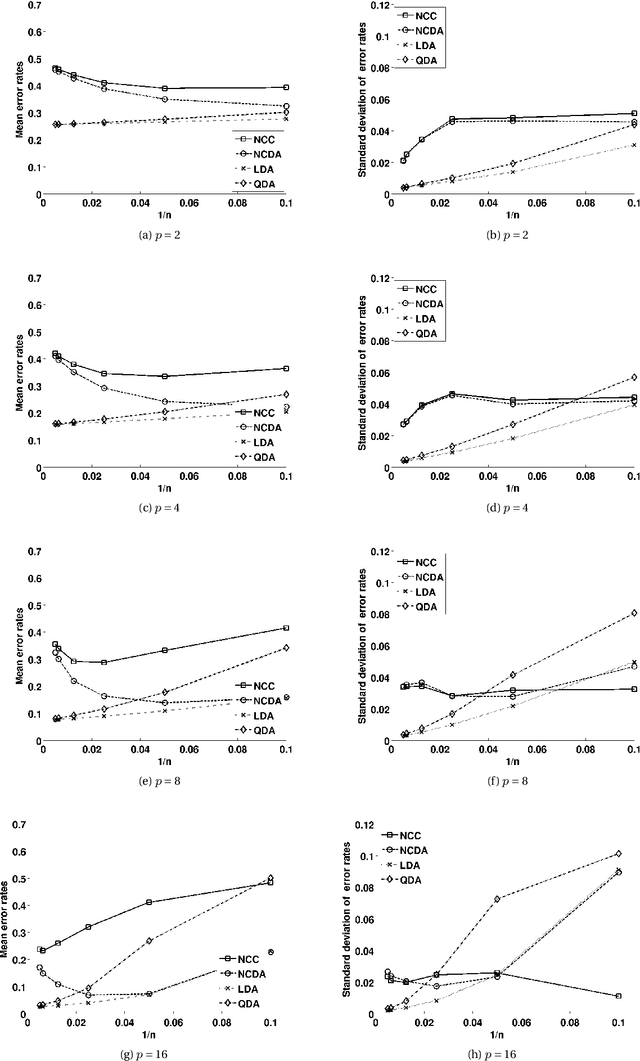
Nested Cavity Classifier (NCC) is a classification rule that pursues partitioning the feature space, in parallel coordinates, into convex hulls to build decision regions. It is claimed in some literatures that this geometric-based classifier is superior to many others, particularly in higher dimensions. First, we give an example on how NCC can be inefficient, then motivate a remedy by combining the NCC with the Linear Discriminant Analysis (LDA) classifier. We coin the term Nested Cavity Discriminant Analysis (NCDA) for the resulting classifier. Second, a simulation study is conducted to compare both, NCC and NCDA to another two basic classifiers, Linear and Quadratic Discriminant Analysis. NCC alone proves to be inferior to others, while NCDA always outperforms NCC and competes with LDA and QDA.
Estimating the Standard Error of Cross-Validation-Based Estimators of Classification Rules Performance
Aug 01, 2019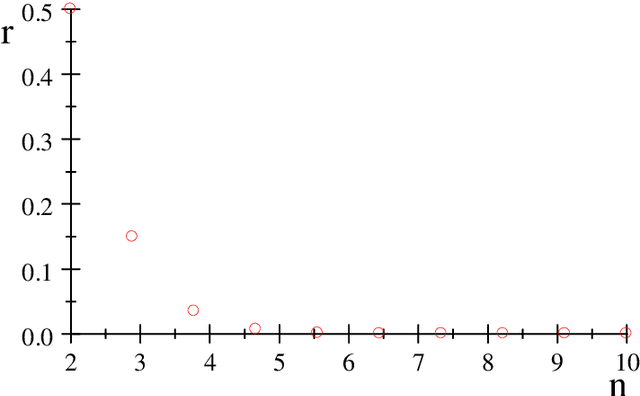
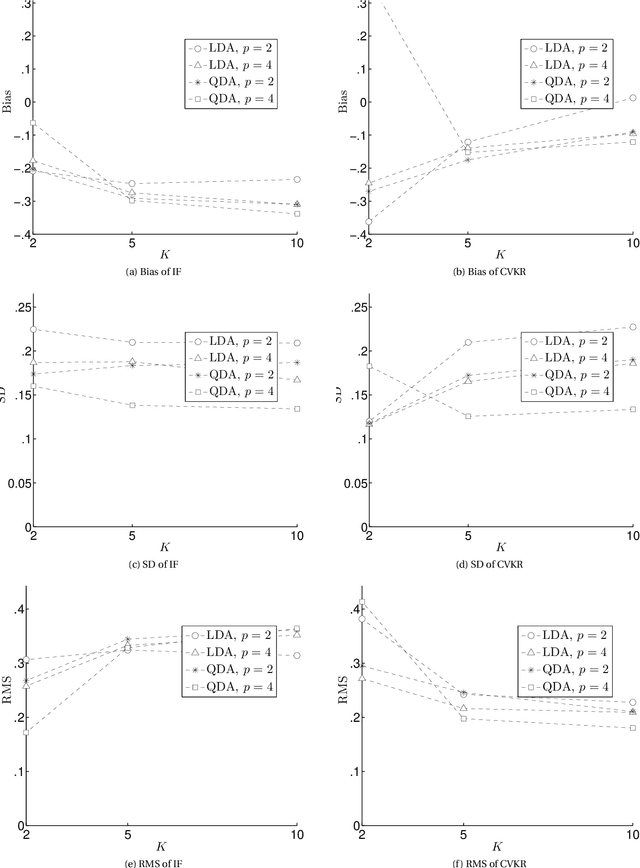
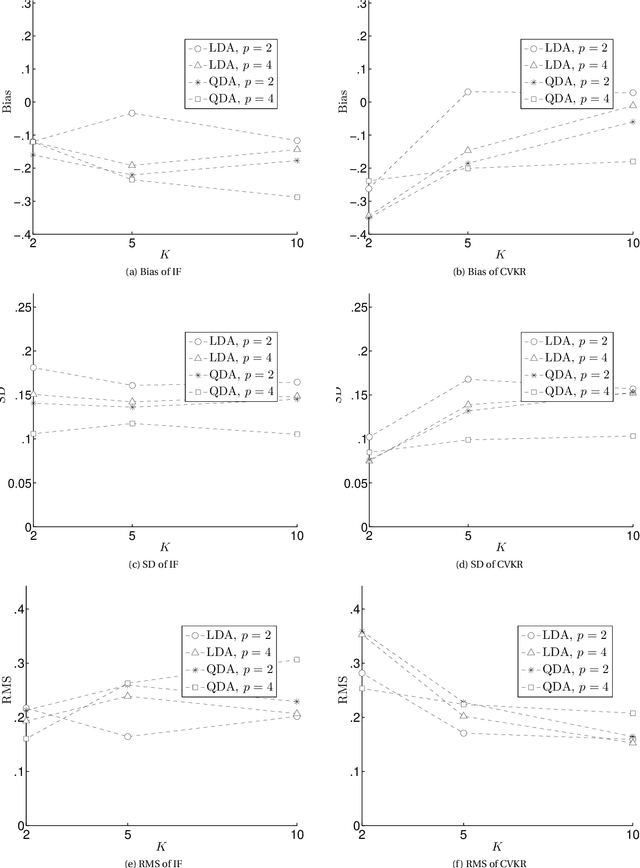
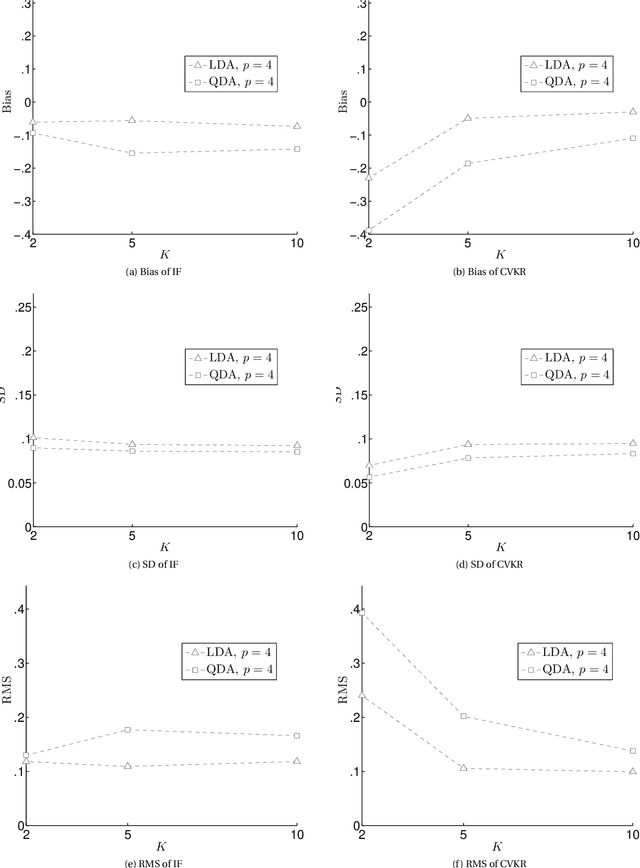
First, we analyze the variance of the Cross Validation (CV)-based estimators used for estimating the performance of classification rules. Second, we propose a novel estimator to estimate this variance using the Influence Function (IF) approach that had been used previously very successfully to estimate the variance of the bootstrap-based estimators. The motivation for this research is that, as the best of our knowledge, the literature lacks a rigorous method for estimating the variance of the CV-based estimators. What is available is a set of ad-hoc procedures that have no mathematical foundation since they ignore the covariance structure among dependent random variables. The conducted experiments show that the IF proposed method has small RMS error with some bias. However, surprisingly, the ad-hoc methods still work better than the IF-based method. Unfortunately, this is due to the lack of enough smoothness if compared to the bootstrap estimator. This opens the research for three points: (1) more comprehensive simulation study to clarify when the IF method win or loose; (2) more mathematical analysis to figure out why the ad-hoc methods work well; and (3) more mathematical treatment to figure out the connection between the appropriate amount of "smoothness" and decreasing the bias of the IF method.
A Leisurely Look at Versions and Variants of the Cross Validation Estimator
Jul 31, 2019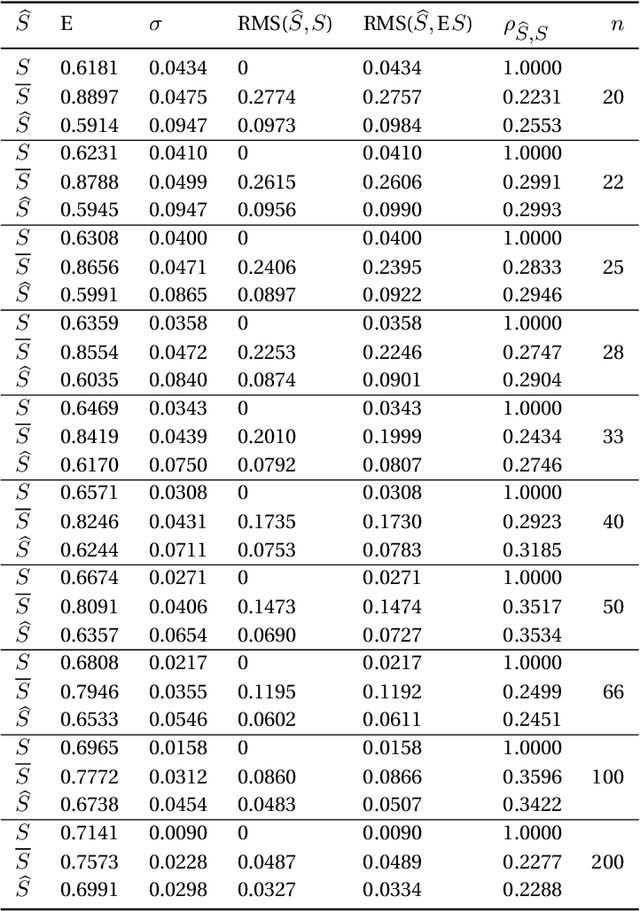

Many versions of cross-validation (CV) exist in the literature; and each version though has different variants. All are used interchangeably by many practitioners; yet, without explanation to the connection or difference among them. This article has three contributions. First, it starts by mathematical formalization of these different versions and variants that estimate the error rate and the Area Under the ROC Curve (AUC) of a classification rule, to show the connection and difference among them. Second, we prove some of their properties and prove that many variants are either redundant or "not smooth". Hence, we suggest to abandon all redundant versions and variants and only keep the leave-one-out, the $K$-fold, and the repeated $K$-fold. We show that the latter is the only among the three versions that is "smooth" and hence looks mathematically like estimating the mean performance of the classification rules. However, empirically, for the known phenomenon of "weak correlation", which we explain mathematically and experimentally, it estimates both conditional and mean performance almost with the same accuracy. Third, we conclude the article with suggesting two research points that may answer the remaining question of whether we can come up with a finalist among the three estimators: (1) a comparative study, that is much more comprehensive than those available in literature and conclude no overall winner, is needed to consider a wide range of distributions, datasets, and classifiers including complex ones obtained via the recent deep learning approach. (2) we sketch the path of deriving a rigorous method for estimating the variance of the only "smooth" version, repeated $K$-fold CV, rather than those ad-hoc methods available in the literature that ignore the covariance structure among the folds of CV.