 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUN-AVOIDS: Unsupervised and Nonparametric Approach for Visualizing Outliers and Invariant Detection Scoring
Nov 19, 2021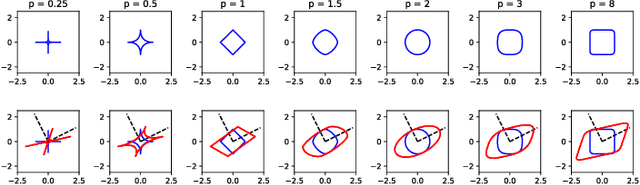
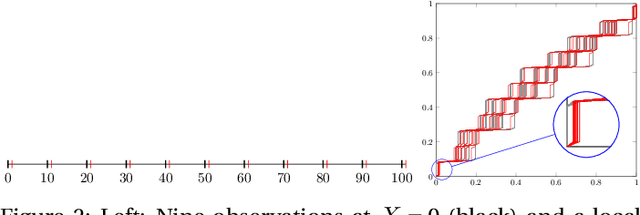
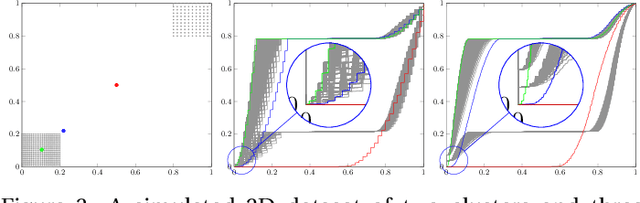

The visualization and detection of anomalies (outliers) are of crucial importance to many fields, particularly cybersecurity. Several approaches have been proposed in these fields, yet to the best of our knowledge, none of them has fulfilled both objectives, simultaneously or cooperatively, in one coherent framework. The visualization methods of these approaches were introduced for explaining the output of a detection algorithm, not for data exploration that facilitates a standalone visual detection. This is our point of departure: UN-AVOIDS, an unsupervised and nonparametric approach for both visualization (a human process) and detection (an algorithmic process) of outliers, that assigns invariant anomalous scores (normalized to $[0,1]$), rather than hard binary-decision. The main aspect of novelty of UN-AVOIDS is that it transforms data into a new space, which is introduced in this paper as neighborhood cumulative density function (NCDF), in which both visualization and detection are carried out. In this space, outliers are remarkably visually distinguishable, and therefore the anomaly scores assigned by the detection algorithm achieved a high area under the ROC curve (AUC). We assessed UN-AVOIDS on both simulated and two recently published cybersecurity datasets, and compared it to three of the most successful anomaly detection methods: LOF, IF, and FABOD. In terms of AUC, UN-AVOIDS was almost an overall winner. The article concludes by providing a preview of new theoretical and practical avenues for UN-AVOIDS. Among them is designing a visualization aided anomaly detection (VAAD), a type of software that aids analysts by providing UN-AVOIDS' detection algorithm (running in a back engine), NCDF visualization space (rendered to plots), along with other conventional methods of visualization in the original feature space, all of which are linked in one interactive environment.
Classifier Calibration: with implications to threat scores in cybersecurity
Feb 09, 2021
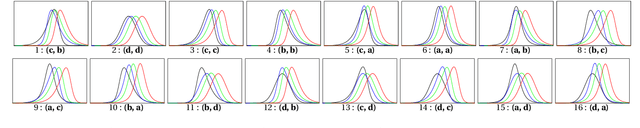
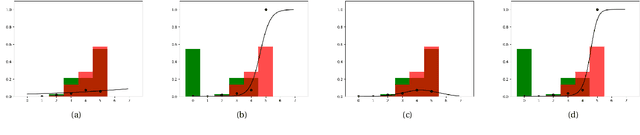
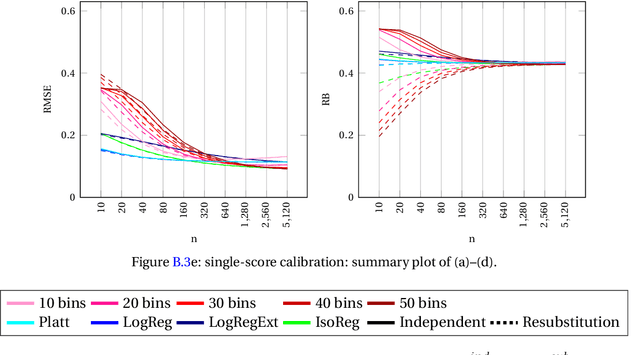
This paper explores the calibration of a classifier output score in binary classification problems. A calibrator is a function that maps the arbitrary classifier score, of a testing observation, onto $[0,1]$ to provide an estimate for the posterior probability of belonging to one of the two classes. Calibration is important for two reasons; first, it provides a meaningful score, that is the posterior probability; second, it puts the scores of different classifiers on the same scale for comparable interpretation. The paper presents three main contributions: (1) Introducing multi-score calibration, when more than one classifier provides a score for a single observation. (2) Introducing the idea that the classifier scores to a calibration process are nothing but features to a classifier, hence proposing extending the classifier scores to higher dimensions to boost the calibrator's performance. (3) Conducting a massive simulation study, in the order of 24,000 experiments, that incorporates different configurations, in addition to experimenting on two real datasets from the cybersecurity domain. The results show that there is no overall winner among the different calibrators and different configurations. However, general advices for practitioners include the following: the Platt's calibrator~\citep{Platt1999ProbabilisticOutputsForSupport}, a version of the logistic regression that decreases bias for a small sample size, has a very stable and acceptable performance among all experiments; our suggested multi-score calibration provides better performance than single score calibration in the majority of experiments, including the two real datasets. In addition, extending the scores can help in some experiments.
Machine Learning in Precision Medicine to Preserve Privacy via Encryption
Feb 05, 2021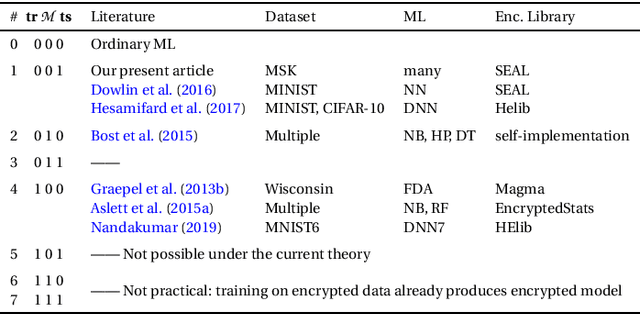
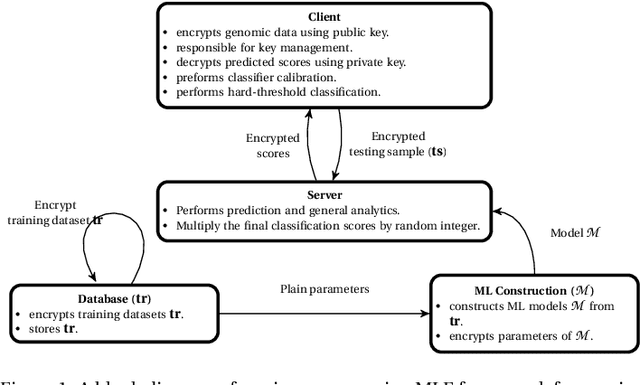


Precision medicine is an emerging approach for disease treatment and prevention that delivers personalized care to individual patients by considering their genetic makeups, medical histories, environments, and lifestyles. Despite the rapid advancement of precision medicine and its considerable promise, several underlying technological challenges remain unsolved. One such challenge of great importance is the security and privacy of precision health-related data, such as genomic data and electronic health records, which stifle collaboration and hamper the full potential of machine-learning (ML) algorithms. To preserve data privacy while providing ML solutions, this article makes three contributions. First, we propose a generic machine learning with encryption (MLE) framework, which we used to build an ML model that predicts cancer from one of the most recent comprehensive genomics datasets in the field. Second, our framework's prediction accuracy is slightly higher than that of the most recent studies conducted on the same dataset, yet it maintains the privacy of the patients' genomic data. Third, to facilitate the validation, reproduction, and extension of this work, we provide an open-source repository that contains the design and implementation of the framework, all the ML experiments and code, and the final predictive model deployed to a free cloud service.