 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment of Multiple-Biomarker Classifiers: fundamental principles and a proposed strategy
Paper and Code
Oct 30, 2019
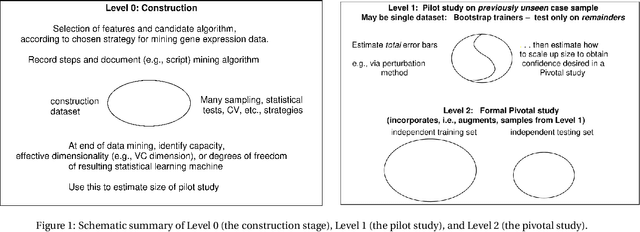
The multiple-biomarker classifier problem and its assessment are reviewed against the background of some fundamental principles from the field of statistical pattern recognition, machine learning, or the recently so-called "data science". A narrow reading of that literature has led many authors to neglect the contribution to the total uncertainty of performance assessment from the finite training sample. Yet the latter is a fundamental indicator of the stability of a classifier; thus its neglect may be contributing to the problematic status of many studies. A three-level strategy is proposed for moving forward in this field. The lowest level is that of construction, where candidate features are selected and the choice of classifier architecture is made. At that point, the effective dimensionality of the classifier is estimated and used to size the next level of analysis, a pilot study on previously unseen cases. The total (training and testing) uncertainty resulting from the pilot study is, in turn, used to size the highest level of analysis, a pivotal study with a target level of uncertainty. Some resources available in the literature for implementing this approach are reviewed. Although the concepts explained in the present article may be fundamental and straightforward for many researchers in the machine learning community they are subtle for many practitioners, for whom we provided a general advice for the best practice in \cite{Shi2010MAQCII} and elaborate here in the present paper.