 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertificates of Differential Privacy and Unlearning for Gradient-Based Training
Jun 19, 2024Proper data stewardship requires that model owners protect the privacy of individuals' data used during training. Whether through anonymization with differential privacy or the use of unlearning in non-anonymized settings, the gold-standard techniques for providing privacy guarantees can come with significant performance penalties or be too weak to provide practical assurances. In part, this is due to the fact that the guarantee provided by differential privacy represents the worst-case privacy leakage for any individual, while the true privacy leakage of releasing the prediction for a given individual might be substantially smaller or even, as we show, non-existent. This work provides a novel framework based on convex relaxations and bounds propagation that can compute formal guarantees (certificates) that releasing specific predictions satisfies $\epsilon=0$ privacy guarantees or do not depend on data that is subject to an unlearning request. Our framework offers a new verification-centric approach to privacy and unlearning guarantees, that can be used to further engender user trust with tighter privacy guarantees, provide formal proofs of robustness to certain membership inference attacks, identify potentially vulnerable records, and enhance current unlearning approaches. We validate the effectiveness of our approach on tasks from financial services, medical imaging, and natural language processing.
Explaining Link Predictions in Knowledge Graph Embedding Models with Influential Examples
Dec 05, 2022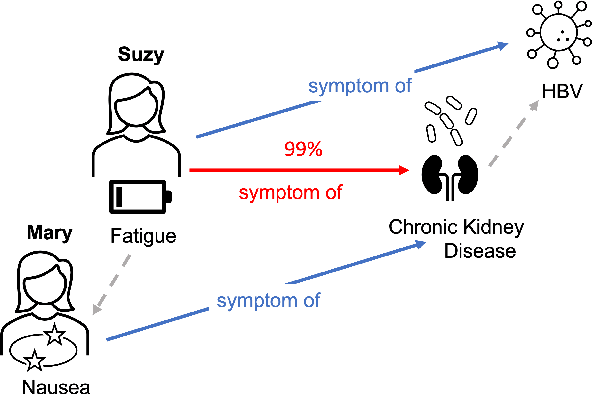
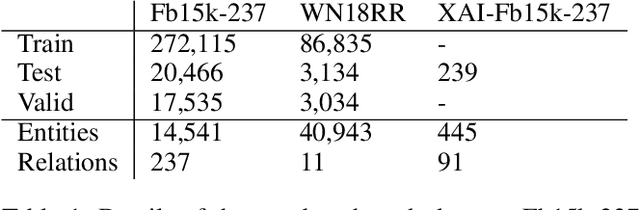
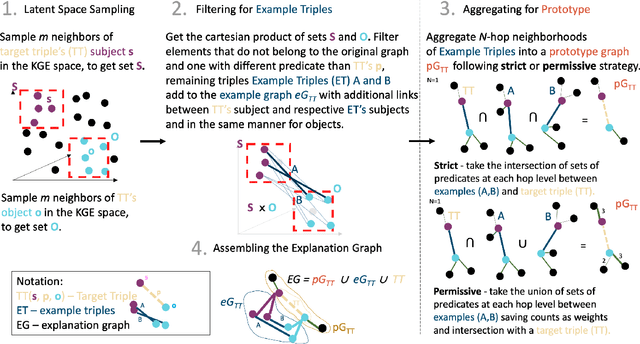
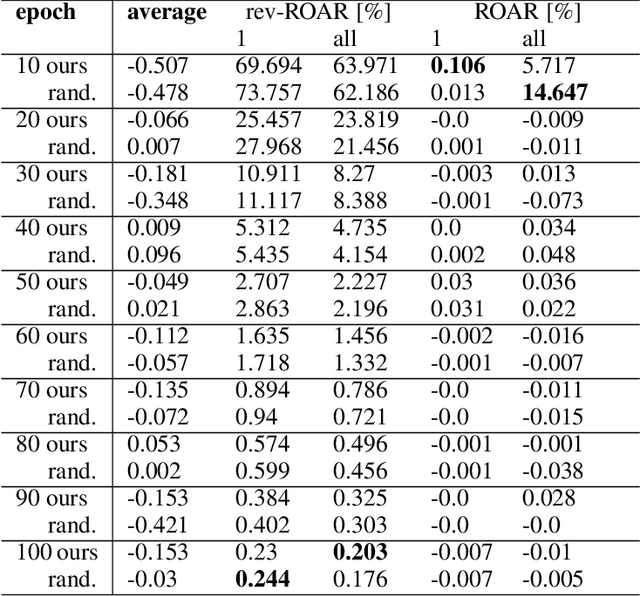
We study the problem of explaining link predictions in the Knowledge Graph Embedding (KGE) models. We propose an example-based approach that exploits the latent space representation of nodes and edges in a knowledge graph to explain predictions. We evaluated the importance of identified triples by observing progressing degradation of model performance upon influential triples removal. Our experiments demonstrate that this approach to generate explanations outperforms baselines on KGE models for two publicly available datasets.
Machine Learning-Assisted Recurrence Prediction for Early-Stage Non-Small-Cell Lung Cancer Patients
Nov 17, 2022



Background: Stratifying cancer patients according to risk of relapse can personalize their care. In this work, we provide an answer to the following research question: How to utilize machine learning to estimate probability of relapse in early-stage non-small-cell lung cancer patients? Methods: For predicting relapse in 1,387 early-stage (I-II), non-small-cell lung cancer (NSCLC) patients from the Spanish Lung Cancer Group data (65.7 average age, 24.8% females, 75.2% males) we train tabular and graph machine learning models. We generate automatic explanations for the predictions of such models. For models trained on tabular data, we adopt SHAP local explanations to gauge how each patient feature contributes to the predicted outcome. We explain graph machine learning predictions with an example-based method that highlights influential past patients. Results: Machine learning models trained on tabular data exhibit a 76% accuracy for the Random Forest model at predicting relapse evaluated with a 10-fold cross-validation (model was trained 10 times with different independent sets of patients in test, train and validation sets, the reported metrics are averaged over these 10 test sets). Graph machine learning reaches 68% accuracy over a 200-patient, held-out test set, calibrated on a held-out set of 100 patients. Conclusions: Our results show that machine learning models trained on tabular and graph data can enable objective, personalised and reproducible prediction of relapse and therefore, disease outcome in patients with early-stage NSCLC. With further prospective and multisite validation, and additional radiological and molecular data, this prognostic model could potentially serve as a predictive decision support tool for deciding the use of adjuvant treatments in early-stage lung cancer. Keywords: Non-Small-Cell Lung Cancer, Tumor Recurrence Prediction, Machine Learning
Sampling Strategy for Fine-Tuning Segmentation Models to Crisis Area under Scarcity of Data
Feb 09, 2022The use of remote sensing in humanitarian crisis response missions is well-established and has proven relevant repeatedly. One of the problems is obtaining gold annotations as it is costly and time consuming which makes it almost impossible to fine-tune models to new regions affected by the crisis. Where time is critical, resources are limited and environment is constantly changing, models has to evolve and provide flexible ways to adapt to a new situation. The question that we want to answer is if prioritization of samples provide better results in fine-tuning vs other classical sampling methods under annotated data scarcity? We propose a method to guide data collection during fine-tuning, based on estimated model and sample properties, like predicted IOU score. We propose two formulas for calculating sample priority. Our approach blends techniques from interpretability, representation learning and active learning. We have applied our method to a deep learning model for semantic segmentation, U-Net, in a remote sensing application of building detection - one of the core use cases of remote sensing in humanitarian applications. Preliminary results shows utility in prioritization of samples for tuning semantic segmentation models under scarcity of data condition.
Discovering Concepts in Learned Representations using Statistical Inference and Interactive Visualization
Feb 09, 2022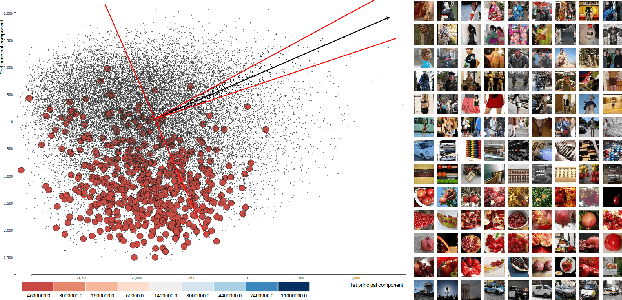
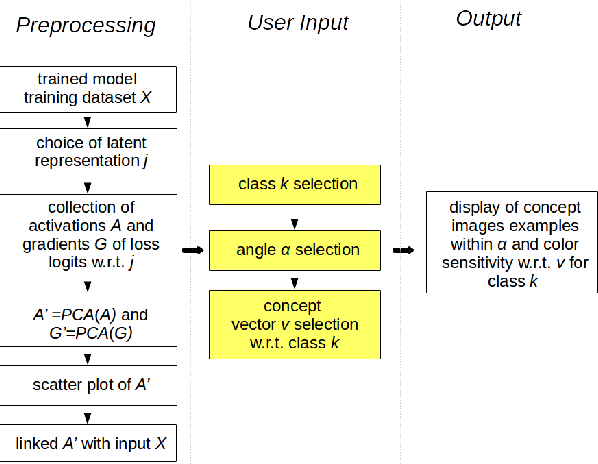
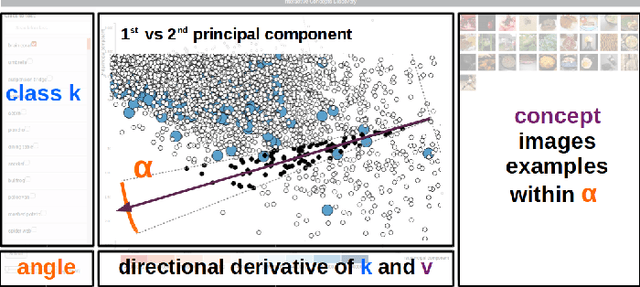
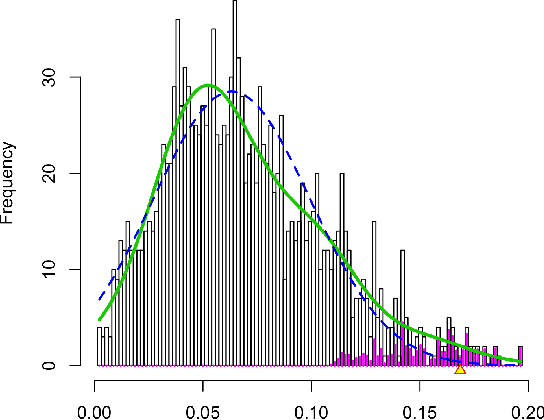
Concept discovery is one of the open problems in the interpretability literature that is important for bridging the gap between non-deep learning experts and model end-users. Among current formulations, concepts defines them by as a direction in a learned representation space. This definition makes it possible to evaluate whether a particular concept significantly influences classification decisions for classes of interest. However, finding relevant concepts is tedious, as representation spaces are high-dimensional and hard to navigate. Current approaches include hand-crafting concept datasets and then converting them to latent space directions; alternatively, the process can be automated by clustering the latent space. In this study, we offer another two approaches to guide user discovery of meaningful concepts, one based on multiple hypothesis testing, and another on interactive visualization. We explore the potential value and limitations of these approaches through simulation experiments and an demo visual interface to real data. Overall, we find that these techniques offer a promising strategy for discovering relevant concepts in settings where users do not have predefined descriptions of them, but without completely automating the process.
Interpretability of a Deep Learning Model in the Application of Cardiac MRI Segmentation with an ACDC Challenge Dataset
Mar 15, 2021
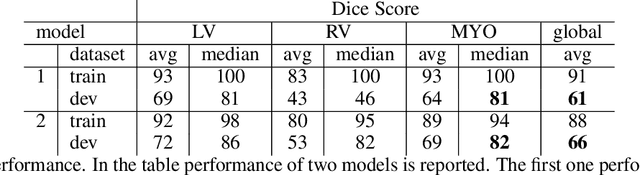

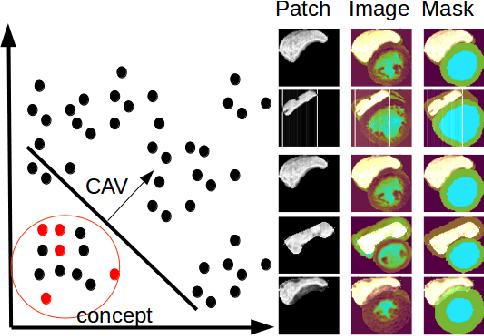
Cardiac Magnetic Resonance (CMR) is the most effective tool for the assessment and diagnosis of a heart condition, which malfunction is the world's leading cause of death. Software tools leveraging Artificial Intelligence already enhance radiologists and cardiologists in heart condition assessment but their lack of transparency is a problem. This project investigates if it is possible to discover concepts representative for different cardiac conditions from the deep network trained to segment crdiac structures: Left Ventricle (LV), Right Ventricle (RV) and Myocardium (MYO), using explainability methods that enhances classification system by providing the score-based values of qualitative concepts, along with the key performance metrics. With introduction of a need of explanations in GDPR explainability of AI systems is necessary. This study applies Discovering and Testing with Concept Activation Vectors (D-TCAV), an interpretaibilty method to extract underlying features important for cardiac disease diagnosis from MRI data. The method provides a quantitative notion of concept importance for disease classified. In previous studies, the base method is applied to the classification of cardiac disease and provides clinically meaningful explanations for the predictions of a black-box deep learning classifier. This study applies a method extending TCAV with a Discovering phase (D-TCAV) to cardiac MRI analysis. The advantage of the D-TCAV method over the base method is that it is user-independent. The contribution of this study is a novel application of the explainability method D-TCAV for cardiac MRI anlysis. D-TCAV provides a shorter pre-processing time for clinicians than the base method.