 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Evaluation of Factors Affecting SHAP Explanation of Time Series Classification
Sep 03, 2025Explainable AI (XAI) has become an increasingly important topic for understanding and attributing the predictions made by complex Time Series Classification (TSC) models. Among attribution methods, SHapley Additive exPlanations (SHAP) is widely regarded as an excellent attribution method; but its computational complexity, which scales exponentially with the number of features, limits its practicality for long time series. To address this, recent studies have shown that aggregating features via segmentation, to compute a single attribution value for a group of consecutive time points, drastically reduces SHAP running time. However, the choice of the optimal segmentation strategy remains an open question. In this work, we investigated eight different Time Series Segmentation algorithms to understand how segment compositions affect the explanation quality. We evaluate these approaches using two established XAI evaluation methodologies: InterpretTime and AUC Difference. Through experiments on both Multivariate (MTS) and Univariate Time Series (UTS), we find that the number of segments has a greater impact on explanation quality than the specific segmentation method. Notably, equal-length segmentation consistently outperforms most of the custom time series segmentation algorithms. Furthermore, we introduce a novel attribution normalisation technique that weights segments by their length and we show that it consistently improves attribution quality.
Improving the Evaluation and Actionability of Explanation Methods for Multivariate Time Series Classification
Jun 18, 2024Explanation for Multivariate Time Series Classification (MTSC) is an important topic that is under explored. There are very few quantitative evaluation methodologies and even fewer examples of actionable explanation, where the explanation methods are shown to objectively improve specific computational tasks on time series data. In this paper we focus on analyzing InterpretTime, a recent evaluation methodology for attribution methods applied to MTSC. We reproduce the original paper results, showcase some significant weaknesses of the methodology and propose ideas to improve both its accuracy and efficiency. Unlike related work, we go beyond evaluation and also showcase the actionability of the produced explainer ranking, by using the best attribution methods for the task of channel selection in MTSC. We find that perturbation-based methods such as SHAP and Feature Ablation work well across a set of datasets, classifiers and tasks and outperform gradient-based methods. We apply the best ranked explainers to channel selection for MTSC and show significant data size reduction and improved classifier accuracy.
Machine Vision-Enabled Sports Performance Analysis
Dec 18, 2023$\textbf{Goal:}$ This study investigates the feasibility of monocular 2D markerless motion capture (MMC) using a single smartphone to measure jump height, velocity, flight time, contact time, and range of motion (ROM) during motor tasks. $\textbf{Methods:}$ Sixteen healthy adults performed three repetitions of selected tests while their body movements were recorded using force plates, optical motion capture (OMC), and a smartphone camera. MMC was then performed on the smartphone videos using OpenPose v1.7.0. $\textbf{Results:}$ MMC demonstrated excellent agreement with ground truth for jump height and velocity measurements. However, MMC's performance varied from poor to moderate for flight time, contact time, ROM, and angular velocity measurements. $\textbf{Conclusions:}$ These findings suggest that monocular 2D MMC may be a viable alternative to OMC or force plates for assessing sports performance during jumps and velocity-based tests. Additionally, MMC could provide valuable visual feedback for flight time, contact time, ROM, and angular velocity measurements.
Evaluating Explanation Methods for Multivariate Time Series Classification
Sep 07, 2023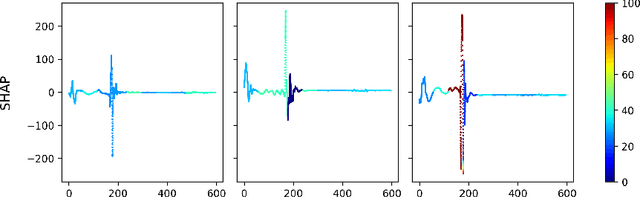


Multivariate time series classification is an important computational task arising in applications where data is recorded over time and over multiple channels. For example, a smartwatch can record the acceleration and orientation of a person's motion, and these signals are recorded as multivariate time series. We can classify this data to understand and predict human movement and various properties such as fitness levels. In many applications classification alone is not enough, we often need to classify but also understand what the model learns (e.g., why was a prediction given, based on what information in the data). The main focus of this paper is on analysing and evaluating explanation methods tailored to Multivariate Time Series Classification (MTSC). We focus on saliency-based explanation methods that can point out the most relevant channels and time series points for the classification decision. We analyse two popular and accurate multivariate time series classifiers, ROCKET and dResNet, as well as two popular explanation methods, SHAP and dCAM. We study these methods on 3 synthetic datasets and 2 real-world datasets and provide a quantitative and qualitative analysis of the explanations provided. We find that flattening the multivariate datasets by concatenating the channels works as well as using multivariate classifiers directly and adaptations of SHAP for MTSC work quite well. Additionally, we also find that the popular synthetic datasets we used are not suitable for time series analysis.
Back to Basics: A Sanity Check on Modern Time Series Classification Algorithms
Aug 15, 2023The state-of-the-art in time series classification has come a long way, from the 1NN-DTW algorithm to the ROCKET family of classifiers. However, in the current fast-paced development of new classifiers, taking a step back and performing simple baseline checks is essential. These checks are often overlooked, as researchers are focused on establishing new state-of-the-art results, developing scalable algorithms, and making models explainable. Nevertheless, there are many datasets that look like time series at first glance, but classic algorithms such as tabular methods with no time ordering may perform better on such problems. For example, for spectroscopy datasets, tabular methods tend to significantly outperform recent time series methods. In this study, we compare the performance of tabular models using classic machine learning approaches (e.g., Ridge, LDA, RandomForest) with the ROCKET family of classifiers (e.g., Rocket, MiniRocket, MultiRocket). Tabular models are simple and very efficient, while the ROCKET family of classifiers are more complex and have state-of-the-art accuracy and efficiency among recent time series classifiers. We find that tabular models outperform the ROCKET family of classifiers on approximately 19% of univariate and 28% of multivariate datasets in the UCR/UEA benchmark and achieve accuracy within 10 percentage points on about 50% of datasets. Our results suggest that it is important to consider simple tabular models as baselines when developing time series classifiers. These models are very fast, can be as effective as more complex methods and may be easier to understand and deploy.
An Examination of Wearable Sensors and Video Data Capture for Human Exercise Classification
Jul 10, 2023



Wearable sensors such as Inertial Measurement Units (IMUs) are often used to assess the performance of human exercise. Common approaches use handcrafted features based on domain expertise or automatically extracted features using time series analysis. Multiple sensors are required to achieve high classification accuracy, which is not very practical. These sensors require calibration and synchronization and may lead to discomfort over longer time periods. Recent work utilizing computer vision techniques has shown similar performance using video, without the need for manual feature engineering, and avoiding some pitfalls such as sensor calibration and placement on the body. In this paper, we compare the performance of IMUs to a video-based approach for human exercise classification on two real-world datasets consisting of Military Press and Rowing exercises. We compare the performance using a single camera that captures video in the frontal view versus using 5 IMUs placed on different parts of the body. We observe that an approach based on a single camera can outperform a single IMU by 10 percentage points on average. Additionally, a minimum of 3 IMUs are required to outperform a single camera. We observe that working with the raw data using multivariate time series classifiers outperforms traditional approaches based on handcrafted or automatically extracted features. Finally, we show that an ensemble model combining the data from a single camera with a single IMU outperforms either data modality. Our work opens up new and more realistic avenues for this application, where a video captured using a readily available smartphone camera, combined with a single sensor, can be used for effective human exercise classification.
AMEE: A Robust Framework for Explanation Evaluation in Time Series Classification
Jun 08, 2023This paper aims to provide a framework to quantitatively evaluate and rank explanation methods for the time series classification task, which deals with a prevalent data type in critical domains such as healthcare and finance. The recent surge of research interest in explanation methods for time series classification has provided a great variety of explanation techniques. Nevertheless, when these explanation techniques disagree on a specific problem, it remains unclear which of them to use. Comparing the explanations to find the right answer is non-trivial. Two key challenges remain: how to quantitatively and robustly evaluate the informativeness (i.e., relevance for the classification task) of a given explanation method, and how to compare explanation methods side-by-side. We propose AMEE, a Model-Agnostic Explanation Evaluation framework for quantifying and comparing multiple saliency-based explanations for time series classification. Perturbation is added to the input time series guided by the saliency maps (i.e., importance weights for each point in the time series). The impact of perturbation on classification accuracy is measured and used for explanation evaluation. The results show that perturbing discriminative parts of the time series leads to significant changes in classification accuracy. To be robust to different types of perturbations and different types of classifiers, we aggregate the accuracy loss across perturbations and classifiers. This allows us to objectively quantify and rank different explanation methods. We provide a quantitative and qualitative analysis for synthetic datasets, a variety of UCR benchmark datasets, as well as a real-world dataset with known expert ground truth.
Quantifying Jump Height Using Markerless Motion Capture with a Single Smartphone
Feb 21, 2023



Goal: The countermovement jump (CMJ) is commonly used to measure the explosive power of the lower body. This study evaluates how accurately markerless motion capture (MMC) with a single smartphone can measure bilateral and unilateral CMJ jump height. Methods: First, three repetitions each of bilateral and unilateral CMJ were performed by sixteen healthy adults (mean age: 30.87 $\pm$ 7.24 years; mean BMI: 23.14 $\pm$ 2.55 $kg/m^2$) on force plates and simultaneously captured using optical motion capture (OMC) and one smartphone camera. Next, MMC was performed on the smartphone videos using OpenPose. Then, we evaluated MMC in quantifying jump height using the force plate and OMC as ground truths. Results: MMC quantifies jump heights with MAE between 1.47 and 2.82 cm, and ICC between 0.84 and 0.99 without manual segmentation and camera calibration. Conclusions: Our results suggest that using a single smartphone for markerless motion capture is feasible. Index Terms - Countermovement jump, Markerless motion capture, Optical motion capture, Jump height. Impact Statement - Countermovement jump height can be accurately quantified using markerless motion capture with a single smartphone, with a simple setup that requires neither camera calibration nor manual segmentation.
Fast and Robust Video-Based Exercise Classification via Body Pose Tracking and Scalable Multivariate Time Series Classifiers
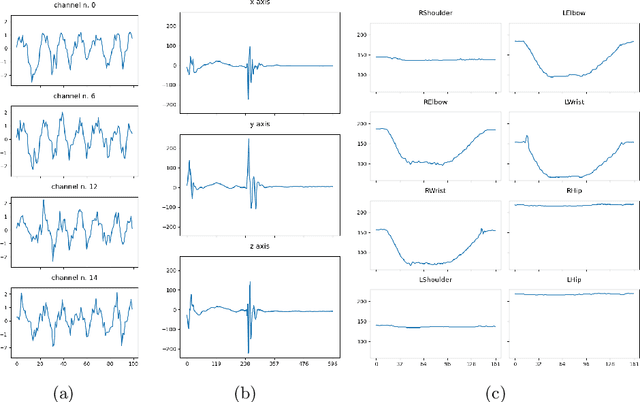
Oct 02, 2022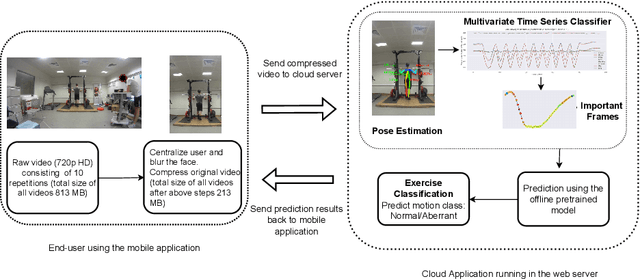


Technological advancements have spurred the usage of machine learning based applications in sports science. Physiotherapists, sports coaches and athletes actively look to incorporate the latest technologies in order to further improve performance and avoid injuries. While wearable sensors are very popular, their use is hindered by constraints on battery power and sensor calibration, especially for use cases which require multiple sensors to be placed on the body. Hence, there is renewed interest in video-based data capture and analysis for sports science. In this paper, we present the application of classifying S\&C exercises using video. We focus on the popular Military Press exercise, where the execution is captured with a video-camera using a mobile device, such as a mobile phone, and the goal is to classify the execution into different types. Since video recordings need a lot of storage and computation, this use case requires data reduction, while preserving the classification accuracy and enabling fast prediction. To this end, we propose an approach named BodyMTS to turn video into time series by employing body pose tracking, followed by training and prediction using multivariate time series classifiers. We analyze the accuracy and robustness of BodyMTS and show that it is robust to different types of noise caused by either video quality or pose estimation factors. We compare BodyMTS to state-of-the-art deep learning methods which classify human activity directly from videos and show that BodyMTS achieves similar accuracy, but with reduced running time and model engineering effort. Finally, we discuss some of the practical aspects of employing BodyMTS in this application in terms of accuracy and robustness under reduced data quality and size. We show that BodyMTS achieves an average accuracy of 87\%, which is significantly higher than the accuracy of human domain experts.
Scalable Classifier-Agnostic Channel Selection for MTSC
Jun 18, 2022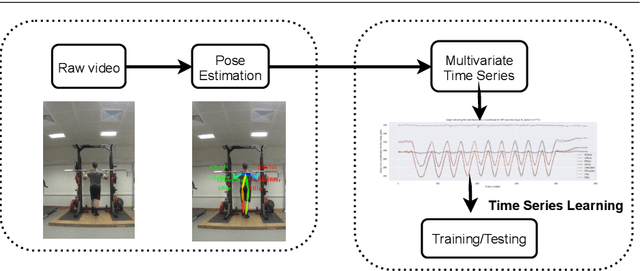
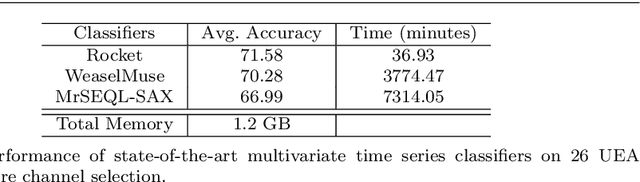
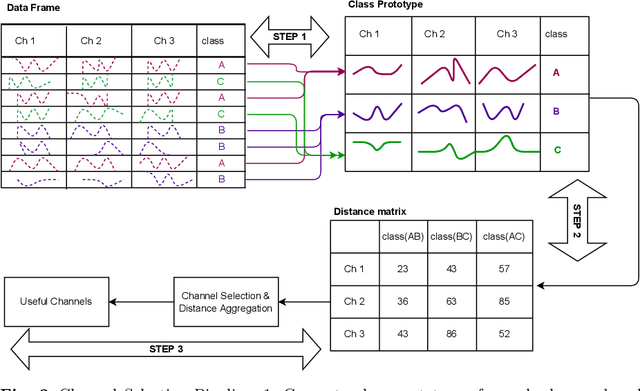
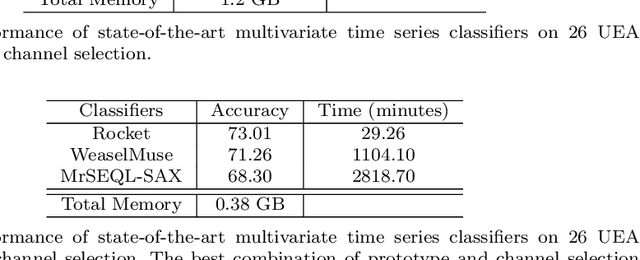
Accuracy is a key focus of current work in time series classification. However, speed and data reduction in many applications is equally important, especially when the data scale and storage requirements increase rapidly. Current MTSC algorithms need hundreds of compute hours to complete training and prediction. This is due to the nature of multivariate time series data, which grows with the number of time series, their length and the number of channels. In many applications, not all the channels are useful for the classification task; hence we require methods that can efficiently select useful channels and thus save computational resources. We propose and evaluate two methods for channel selection. Our techniques work by representing each class by a prototype time series and performing channel selection based on the prototype distance between classes. The main hypothesis is that useful channels enable better separation between classes; hence, channels with the higher distance between class prototypes are more useful. On the UEA Multivariate Time Series Classification (MTSC) benchmark, we show that these techniques achieve significant data reduction and classifier speedup for similar levels of classification accuracy. Channel selection is applied as a pre-processing step before training state-of-the-art MTSC algorithms and saves about 70\% of computation time and data storage, with preserved accuracy. Furthermore, our methods enable even efficient classifiers, such as ROCKET, to achieve better accuracy than using no channel selection or forward channel selection. To further study the impact of our techniques, we present experiments on classifying synthetic multivariate time series datasets with more than 100 channels, as well as a real-world case study on a dataset with 50 channels. Our channel selection methods lead to significant data reduction with preserved or improved accuracy.