 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegotiationGym: Self-Optimizing Agents in a Multi-Agent Social Simulation Environment
Oct 05, 2025We design and implement NegotiationGym, an API and user interface for configuring and running multi-agent social simulations focused upon negotiation and cooperation. The NegotiationGym codebase offers a user-friendly, configuration-driven API that enables easy design and customization of simulation scenarios. Agent-level utility functions encode optimization criteria for each agent, and agents can self-optimize by conducting multiple interaction rounds with other agents, observing outcomes, and modifying their strategies for future rounds.
GLiREL -- Generalist Model for Zero-Shot Relation Extraction
Jan 06, 2025



We introduce GLiREL (Generalist Lightweight model for zero-shot Relation Extraction), an efficient architecture and training paradigm for zero-shot relation classification. Inspired by recent advancements in zero-shot named entity recognition, this work presents an approach to efficiently and accurately predict zero-shot relationship labels between multiple entities in a single forward pass. Experiments using the FewRel and WikiZSL benchmarks demonstrate that our approach achieves state-of-the-art results on the zero-shot relation classification task. In addition, we contribute a protocol for synthetically-generating datasets with diverse relation labels.
KGValidator: A Framework for Automatic Validation of Knowledge Graph Construction
Apr 24, 2024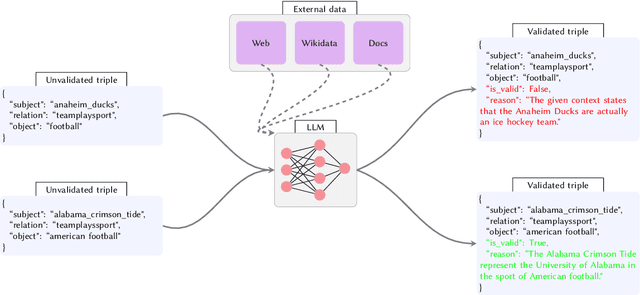
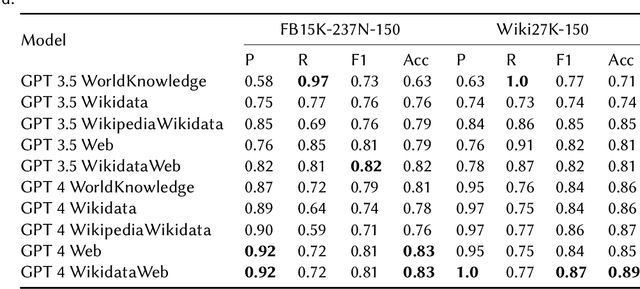
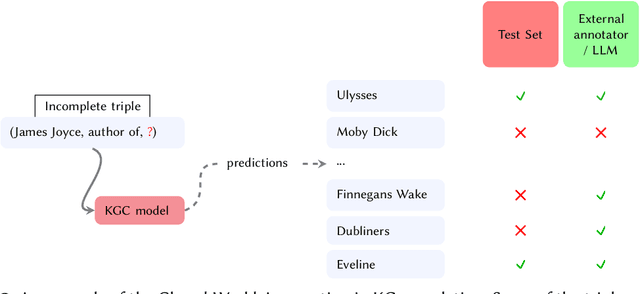
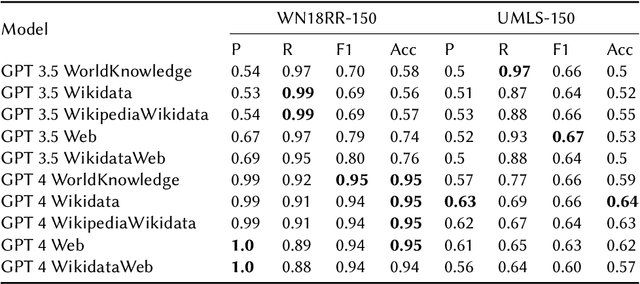
This study explores the use of Large Language Models (LLMs) for automatic evaluation of knowledge graph (KG) completion models. Historically, validating information in KGs has been a challenging task, requiring large-scale human annotation at prohibitive cost. With the emergence of general-purpose generative AI and LLMs, it is now plausible that human-in-the-loop validation could be replaced by a generative agent. We introduce a framework for consistency and validation when using generative models to validate knowledge graphs. Our framework is based upon recent open-source developments for structural and semantic validation of LLM outputs, and upon flexible approaches to fact checking and verification, supported by the capacity to reference external knowledge sources of any kind. The design is easy to adapt and extend, and can be used to verify any kind of graph-structured data through a combination of model-intrinsic knowledge, user-supplied context, and agents capable of external knowledge retrieval.
News Signals: An NLP Library for Text and Time Series
Dec 18, 2023


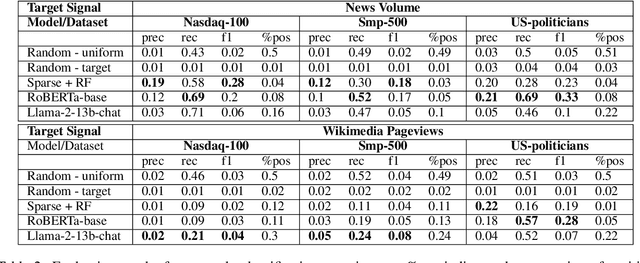
We present an open-source Python library for building and using datasets where inputs are clusters of textual data, and outputs are sequences of real values representing one or more time series signals. The news-signals library supports diverse data science and NLP problem settings related to the prediction of time series behaviour using textual data feeds. For example, in the news domain, inputs are document clusters corresponding to daily news articles about a particular entity, and targets are explicitly associated real-valued time series: the volume of news about a particular person or company, or the number of pageviews of specific Wikimedia pages. Despite many industry and research use cases for this class of problem settings, to the best of our knowledge, News Signals is the only open-source library designed specifically to facilitate data science and research settings with natural language inputs and time series targets. In addition to the core codebase for building and interacting with datasets, we also conduct a suite of experiments using several popular Machine Learning libraries, which are used to establish baselines for time series anomaly prediction using textual inputs.
Efficient Unsupervised Sentence Compression by Fine-tuning Transformers with Reinforcement Learning
May 17, 2022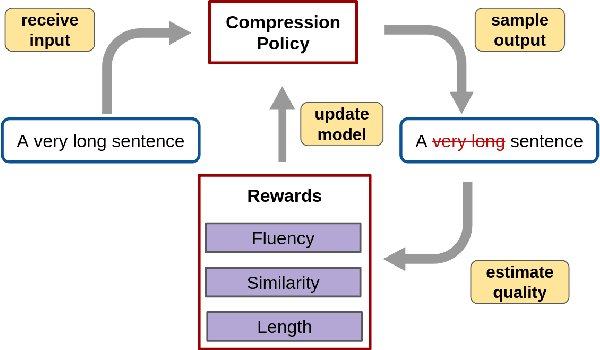

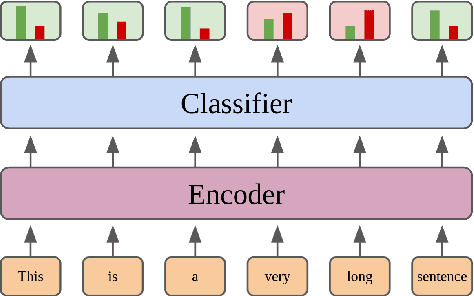

Sentence compression reduces the length of text by removing non-essential content while preserving important facts and grammaticality. Unsupervised objective driven methods for sentence compression can be used to create customized models without the need for ground-truth training data, while allowing flexibility in the objective function(s) that are used for learning and inference. Recent unsupervised sentence compression approaches use custom objectives to guide discrete search; however, guided search is expensive at inference time. In this work, we explore the use of reinforcement learning to train effective sentence compression models that are also fast when generating predictions. In particular, we cast the task as binary sequence labelling and fine-tune a pre-trained transformer using a simple policy gradient approach. Our approach outperforms other unsupervised models while also being more efficient at inference time.
DynE: Dynamic Ensemble Decoding for Multi-Document Summarization
Jun 15, 2020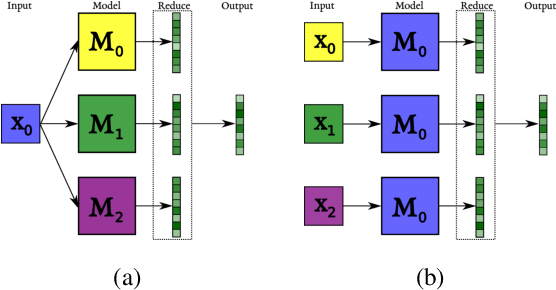
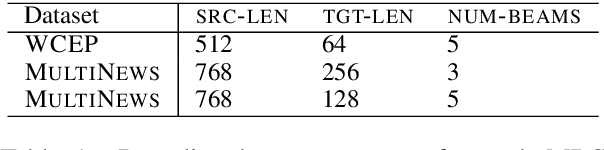
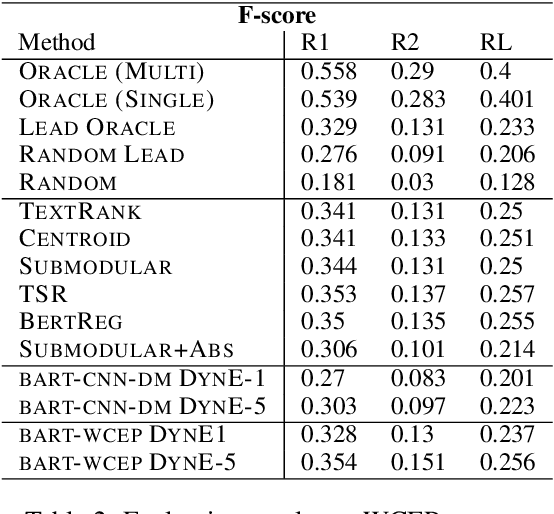
Sequence-to-sequence (s2s) models are the basis for extensive work in natural language processing. However, some applications, such as multi-document summarization, multi-modal machine translation, and the automatic post-editing of machine translation, require mapping a set of multiple distinct inputs into a single output sequence. Recent work has introduced bespoke architectures for these multi-input settings, and developed models which can handle increasingly longer inputs; however, the performance of special model architectures is limited by the available in-domain training data. In this work we propose a simple decoding methodology which ensembles the output of multiple instances of the same model on different inputs. Our proposed approach allows models trained for vanilla s2s tasks to be directly used in multi-input settings. This works particularly well when each of the inputs has significant overlap with the others, as when compressing a cluster of news articles about the same event into a single coherent summary, and we obtain state-of-the-art results on several multi-document summarization datasets.
Examining the State-of-the-Art in News Timeline Summarization
May 20, 2020
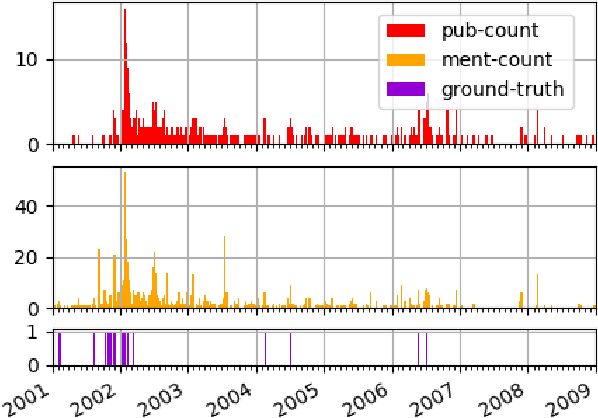

Previous work on automatic news timeline summarization (TLS) leaves an unclear picture about how this task can generally be approached and how well it is currently solved. This is mostly due to the focus on individual subtasks, such as date selection and date summarization, and to the previous lack of appropriate evaluation metrics for the full TLS task. In this paper, we compare different TLS strategies using appropriate evaluation frameworks, and propose a simple and effective combination of methods that improves over the state-of-the-art on all tested benchmarks. For a more robust evaluation, we also present a new TLS dataset, which is larger and spans longer time periods than previous datasets.
A Large-Scale Multi-Document Summarization Dataset from the Wikipedia Current Events Portal
May 20, 2020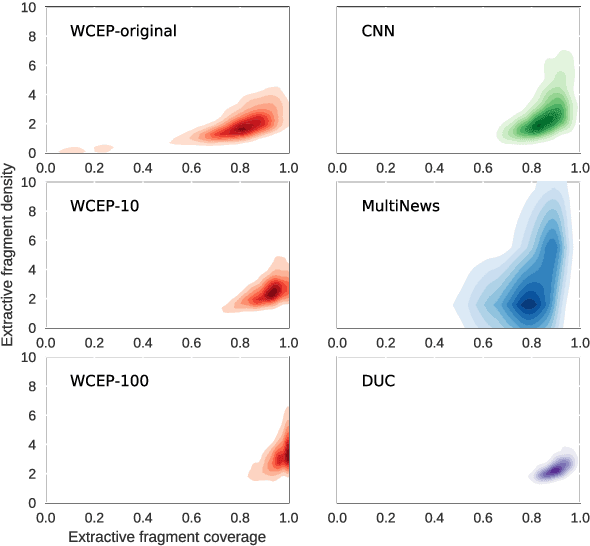

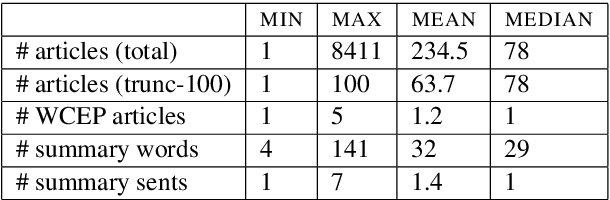
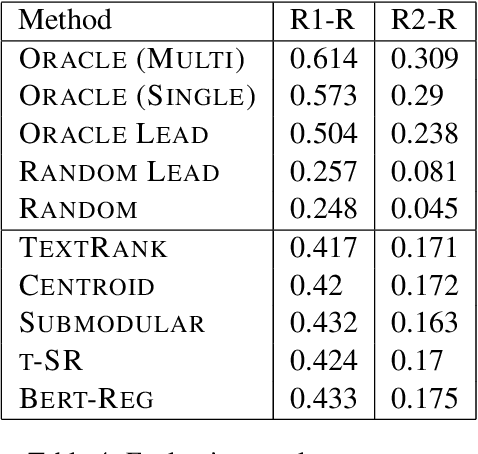
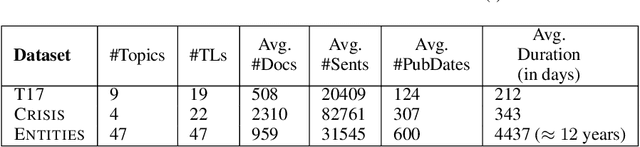
Multi-document summarization (MDS) aims to compress the content in large document collections into short summaries and has important applications in story clustering for newsfeeds, presentation of search results, and timeline generation. However, there is a lack of datasets that realistically address such use cases at a scale large enough for training supervised models for this task. This work presents a new dataset for MDS that is large both in the total number of document clusters and in the size of individual clusters. We build this dataset by leveraging the Wikipedia Current Events Portal (WCEP), which provides concise and neutral human-written summaries of news events, with links to external source articles. We also automatically extend these source articles by looking for related articles in the Common Crawl archive. We provide a quantitative analysis of the dataset and empirical results for several state-of-the-art MDS techniques.
Revisiting the Centroid-based Method: A Strong Baseline for Multi-Document Summarization
Aug 25, 2017

The centroid-based model for extractive document summarization is a simple and fast baseline that ranks sentences based on their similarity to a centroid vector. In this paper, we apply this ranking to possible summaries instead of sentences and use a simple greedy algorithm to find the best summary. Furthermore, we show possi- bilities to scale up to larger input docu- ment collections by selecting a small num- ber of sentences from each document prior to constructing the summary. Experiments were done on the DUC2004 dataset for multi-document summarization. We ob- serve a higher performance over the orig- inal model, on par with more complex state-of-the-art methods.