 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrative Studio: Visual narrative exploration using LLMs and Monte Carlo Tree Search
Apr 03, 2025



Interactive storytelling benefits from planning and exploring multiple 'what if' scenarios. Modern LLMs are useful tools for ideation and exploration, but current chat-based user interfaces restrict users to a single linear flow. To address this limitation, we propose Narrative Studio -- a novel in-browser narrative exploration environment featuring a tree-like interface that allows branching exploration from user-defined points in a story. Each branch is extended via iterative LLM inference guided by system and user-defined prompts. Additionally, we employ Monte Carlo Tree Search (MCTS) to automatically expand promising narrative paths based on user-specified criteria, enabling more diverse and robust story development. We also allow users to enhance narrative coherence by grounding the generated text in an entity graph that represents the actors and environment of the story.
KGValidator: A Framework for Automatic Validation of Knowledge Graph Construction
Apr 24, 2024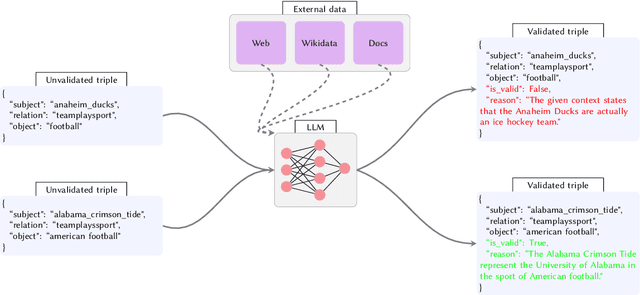
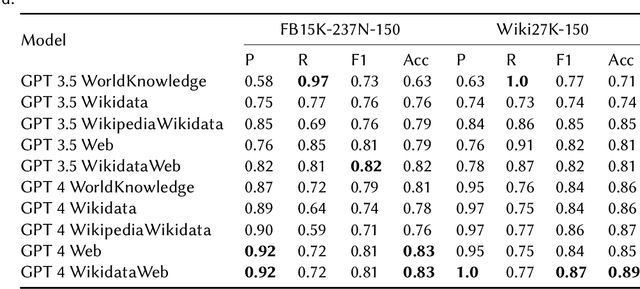
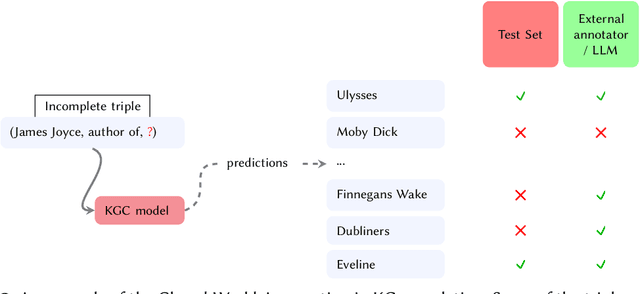
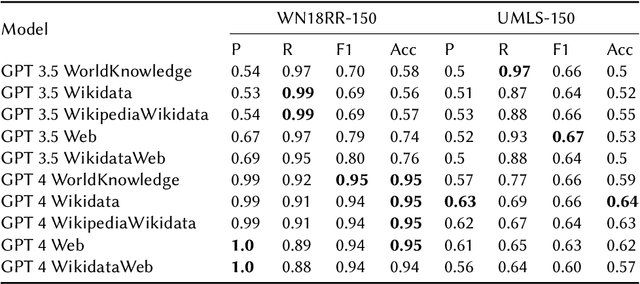
This study explores the use of Large Language Models (LLMs) for automatic evaluation of knowledge graph (KG) completion models. Historically, validating information in KGs has been a challenging task, requiring large-scale human annotation at prohibitive cost. With the emergence of general-purpose generative AI and LLMs, it is now plausible that human-in-the-loop validation could be replaced by a generative agent. We introduce a framework for consistency and validation when using generative models to validate knowledge graphs. Our framework is based upon recent open-source developments for structural and semantic validation of LLM outputs, and upon flexible approaches to fact checking and verification, supported by the capacity to reference external knowledge sources of any kind. The design is easy to adapt and extend, and can be used to verify any kind of graph-structured data through a combination of model-intrinsic knowledge, user-supplied context, and agents capable of external knowledge retrieval.
News Signals: An NLP Library for Text and Time Series
Dec 18, 2023


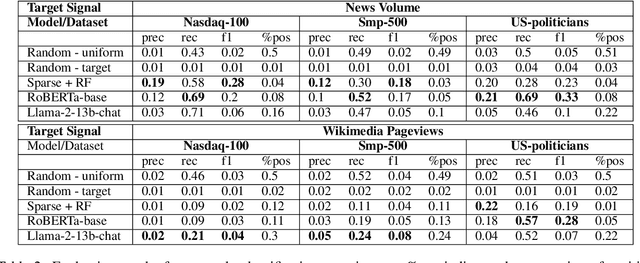
We present an open-source Python library for building and using datasets where inputs are clusters of textual data, and outputs are sequences of real values representing one or more time series signals. The news-signals library supports diverse data science and NLP problem settings related to the prediction of time series behaviour using textual data feeds. For example, in the news domain, inputs are document clusters corresponding to daily news articles about a particular entity, and targets are explicitly associated real-valued time series: the volume of news about a particular person or company, or the number of pageviews of specific Wikimedia pages. Despite many industry and research use cases for this class of problem settings, to the best of our knowledge, News Signals is the only open-source library designed specifically to facilitate data science and research settings with natural language inputs and time series targets. In addition to the core codebase for building and interacting with datasets, we also conduct a suite of experiments using several popular Machine Learning libraries, which are used to establish baselines for time series anomaly prediction using textual inputs.
360° Stance Detection
Apr 03, 2018
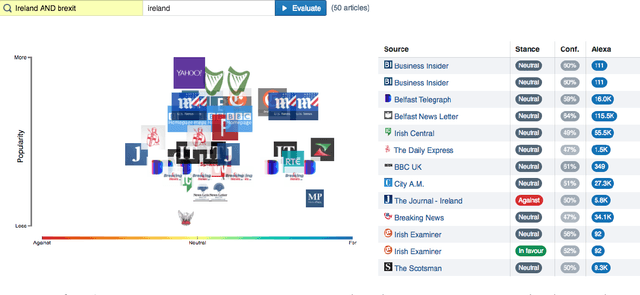

The proliferation of fake news and filter bubbles makes it increasingly difficult to form an unbiased, balanced opinion towards a topic. To ameliorate this, we propose 360{\deg} Stance Detection, a tool that aggregates news with multiple perspectives on a topic. It presents them on a spectrum ranging from support to opposition, enabling the user to base their opinion on multiple pieces of diverse evidence.
Data Selection Strategies for Multi-Domain Sentiment Analysis
Feb 08, 2017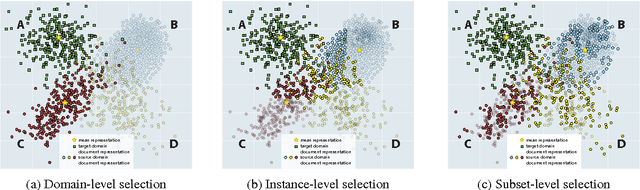
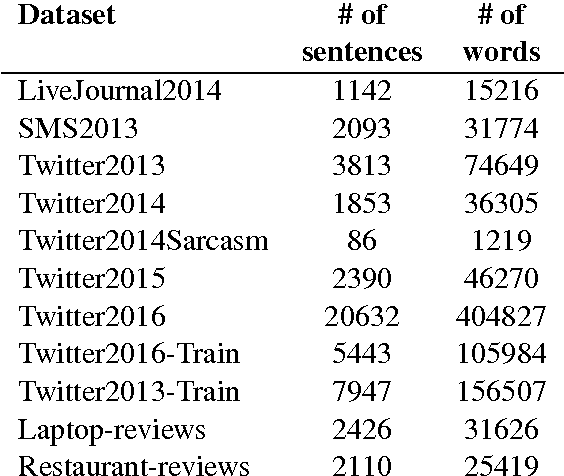
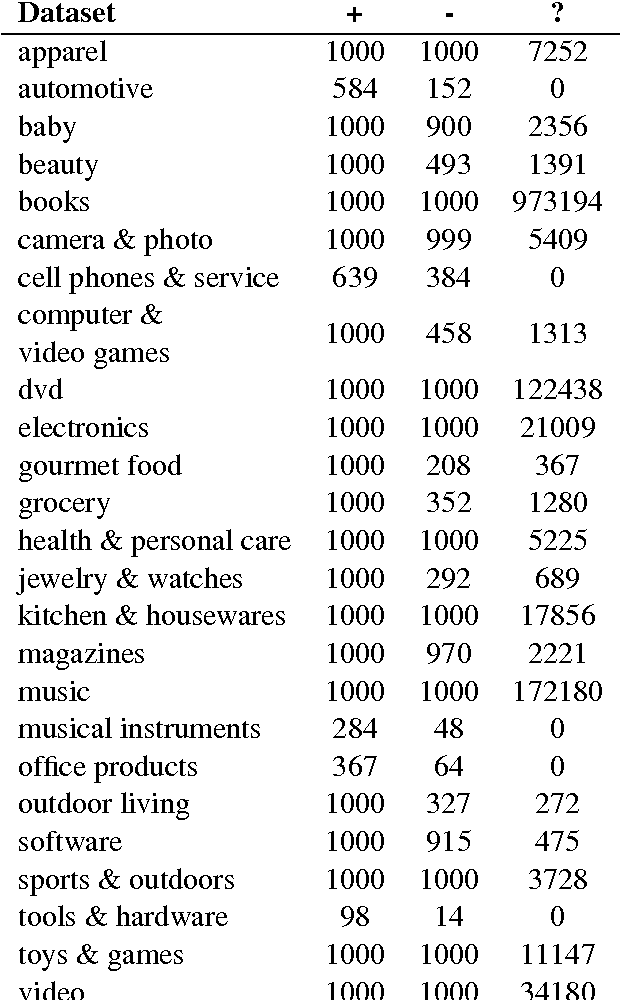
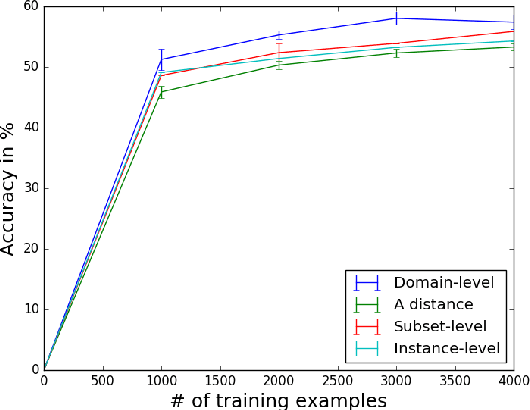
Domain adaptation is important in sentiment analysis as sentiment-indicating words vary between domains. Recently, multi-domain adaptation has become more pervasive, but existing approaches train on all available source domains including dissimilar ones. However, the selection of appropriate training data is as important as the choice of algorithm. We undertake -- to our knowledge for the first time -- an extensive study of domain similarity metrics in the context of sentiment analysis and propose novel representations, metrics, and a new scope for data selection. We evaluate the proposed methods on two large-scale multi-domain adaptation settings on tweets and reviews and demonstrate that they consistently outperform strong random and balanced baselines, while our proposed selection strategy outperforms instance-level selection and yields the best score on a large reviews corpus.
Knowledge Adaptation: Teaching to Adapt
Feb 07, 2017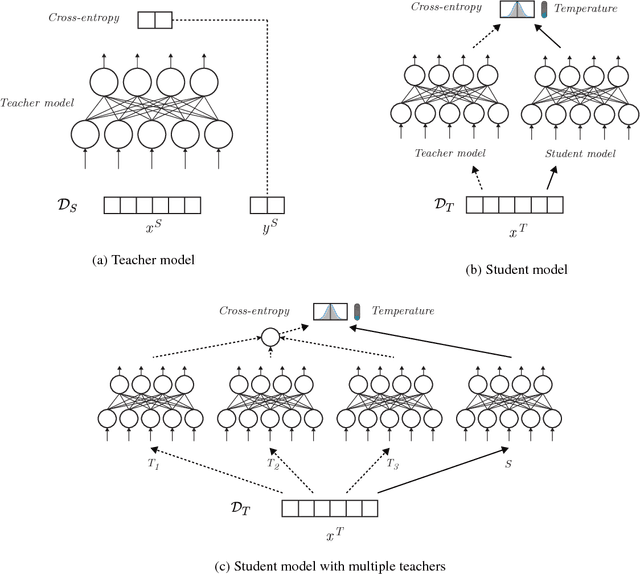

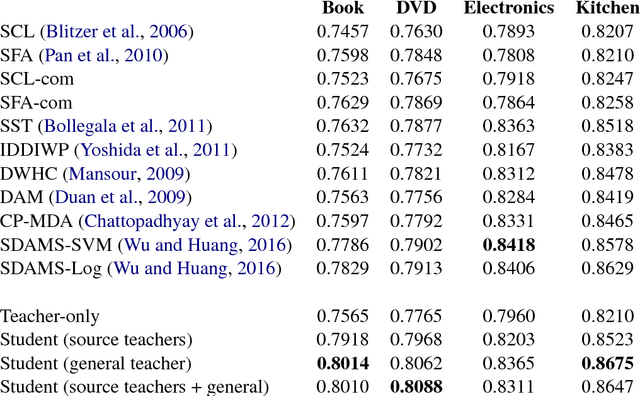
Domain adaptation is crucial in many real-world applications where the distribution of the training data differs from the distribution of the test data. Previous Deep Learning-based approaches to domain adaptation need to be trained jointly on source and target domain data and are therefore unappealing in scenarios where models need to be adapted to a large number of domains or where a domain is evolving, e.g. spam detection where attackers continuously change their tactics. To fill this gap, we propose Knowledge Adaptation, an extension of Knowledge Distillation (Bucilua et al., 2006; Hinton et al., 2015) to the domain adaptation scenario. We show how a student model achieves state-of-the-art results on unsupervised domain adaptation from multiple sources on a standard sentiment analysis benchmark by taking into account the domain-specific expertise of multiple teachers and the similarities between their domains. When learning from a single teacher, using domain similarity to gauge trustworthiness is inadequate. To this end, we propose a simple metric that correlates well with the teacher's accuracy in the target domain. We demonstrate that incorporating high-confidence examples selected by this metric enables the student model to achieve state-of-the-art performance in the single-source scenario.
Towards a continuous modeling of natural language domains
Oct 28, 2016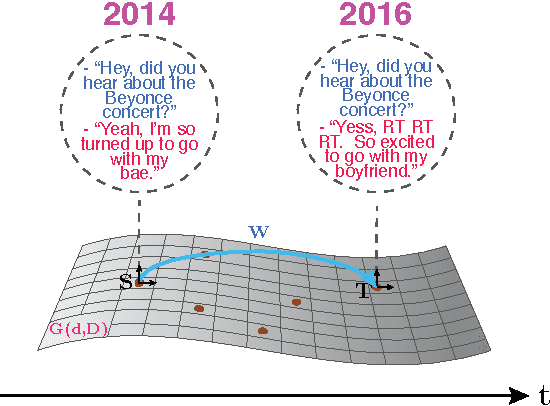
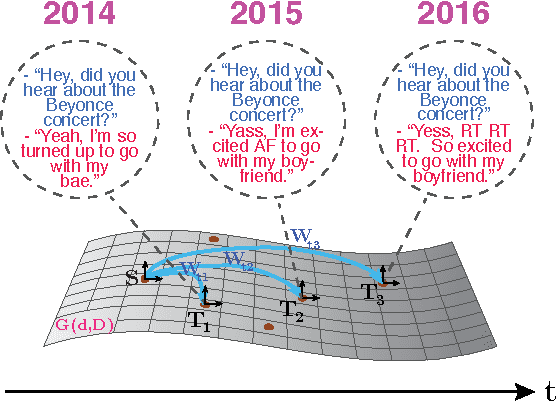
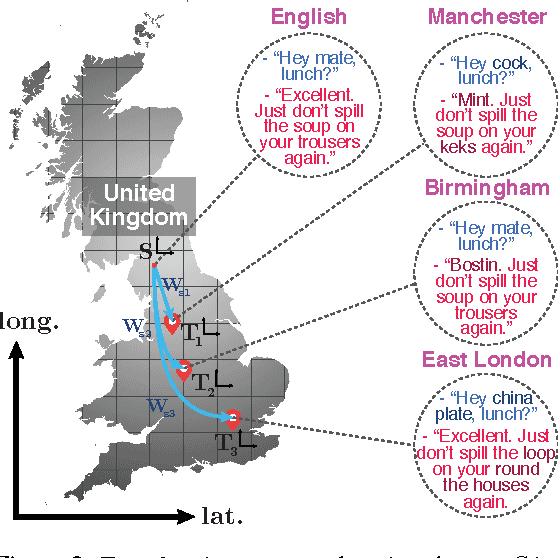
Humans continuously adapt their style and language to a variety of domains. However, a reliable definition of `domain' has eluded researchers thus far. Additionally, the notion of discrete domains stands in contrast to the multiplicity of heterogeneous domains that humans navigate, many of which overlap. In order to better understand the change and variation of human language, we draw on research in domain adaptation and extend the notion of discrete domains to the continuous spectrum. We propose representation learning-based models that can adapt to continuous domains and detail how these can be used to investigate variation in language. To this end, we propose to use dialogue modeling as a test bed due to its proximity to language modeling and its social component.
INSIGHT-1 at SemEval-2016 Task 5: Deep Learning for Multilingual Aspect-based Sentiment Analysis
Sep 22, 2016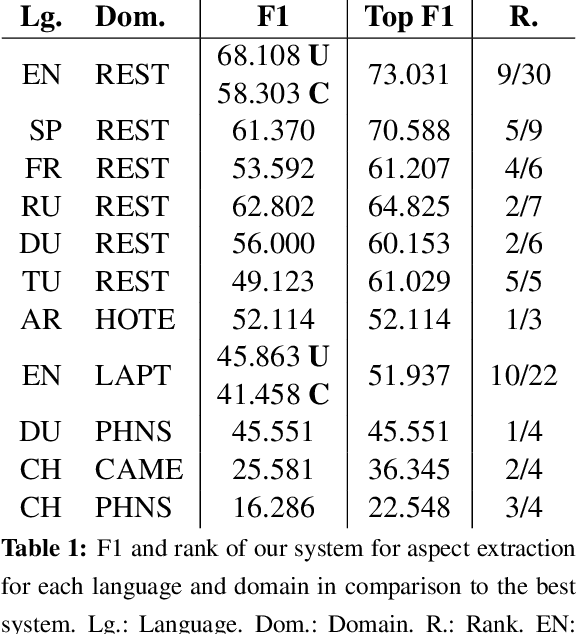
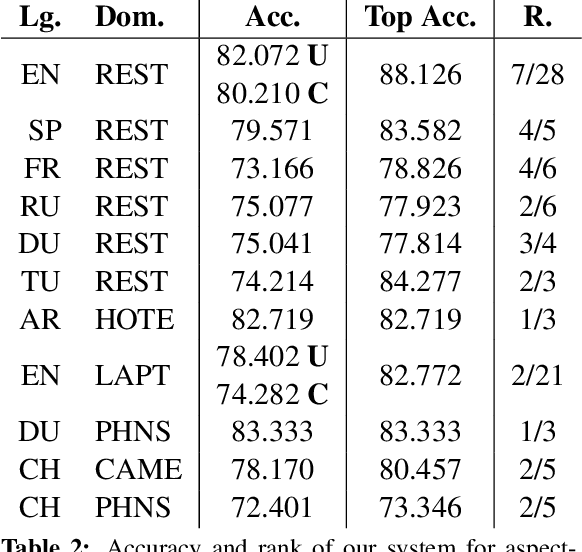
This paper describes our deep learning-based approach to multilingual aspect-based sentiment analysis as part of SemEval 2016 Task 5. We use a convolutional neural network (CNN) for both aspect extraction and aspect-based sentiment analysis. We cast aspect extraction as a multi-label classification problem, outputting probabilities over aspects parameterized by a threshold. To determine the sentiment towards an aspect, we concatenate an aspect vector with every word embedding and apply a convolution over it. Our constrained system (unconstrained for English) achieves competitive results across all languages and domains, placing first or second in 5 and 7 out of 11 language-domain pairs for aspect category detection (slot 1) and sentiment polarity (slot 3) respectively, thereby demonstrating the viability of a deep learning-based approach for multilingual aspect-based sentiment analysis.
* Published in Proceedings of SemEval-2016, 7 pages
Character-level and Multi-channel Convolutional Neural Networks for Large-scale Authorship Attribution
Sep 21, 2016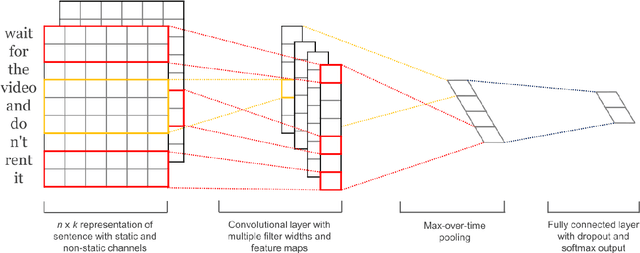
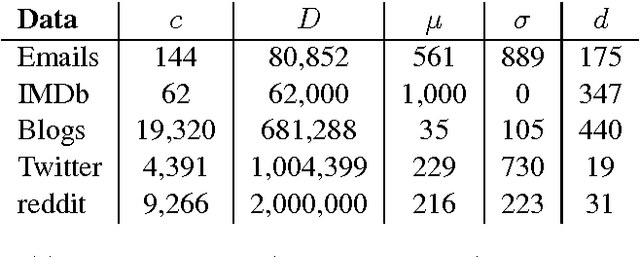

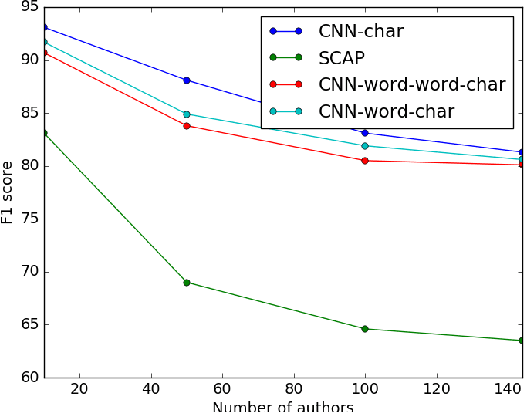
Convolutional neural networks (CNNs) have demonstrated superior capability for extracting information from raw signals in computer vision. Recently, character-level and multi-channel CNNs have exhibited excellent performance for sentence classification tasks. We apply CNNs to large-scale authorship attribution, which aims to determine an unknown text's author among many candidate authors, motivated by their ability to process character-level signals and to differentiate between a large number of classes, while making fast predictions in comparison to state-of-the-art approaches. We extensively evaluate CNN-based approaches that leverage word and character channels and compare them against state-of-the-art methods for a large range of author numbers, shedding new light on traditional approaches. We show that character-level CNNs outperform the state-of-the-art on four out of five datasets in different domains. Additionally, we present the first application of authorship attribution to reddit.
INSIGHT-1 at SemEval-2016 Task 4: Convolutional Neural Networks for Sentiment Classification and Quantification
Sep 09, 2016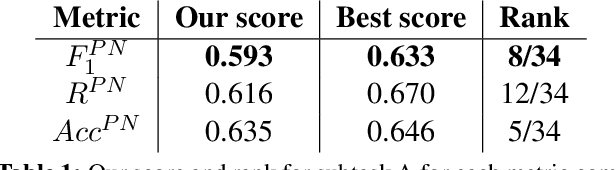
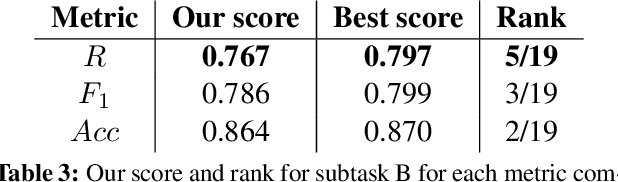
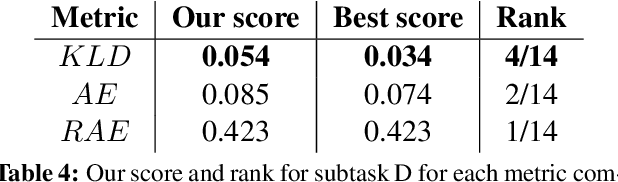
This paper describes our deep learning-based approach to sentiment analysis in Twitter as part of SemEval-2016 Task 4. We use a convolutional neural network to determine sentiment and participate in all subtasks, i.e. two-point, three-point, and five-point scale sentiment classification and two-point and five-point scale sentiment quantification. We achieve competitive results for two-point scale sentiment classification and quantification, ranking fifth and a close fourth (third and second by alternative metrics) respectively despite using only pre-trained embeddings that contain no sentiment information. We achieve good performance on three-point scale sentiment classification, ranking eighth out of 35, while performing poorly on five-point scale sentiment classification and quantification. An error analysis reveals that this is due to low expressiveness of the model to capture negative sentiment as well as an inability to take into account ordinal information. We propose improvements in order to address these and other issues.
* Published in Proceedings of SemEval-2016, 5 pages