 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Adaptation: Teaching to Adapt
Paper and Code
Feb 07, 2017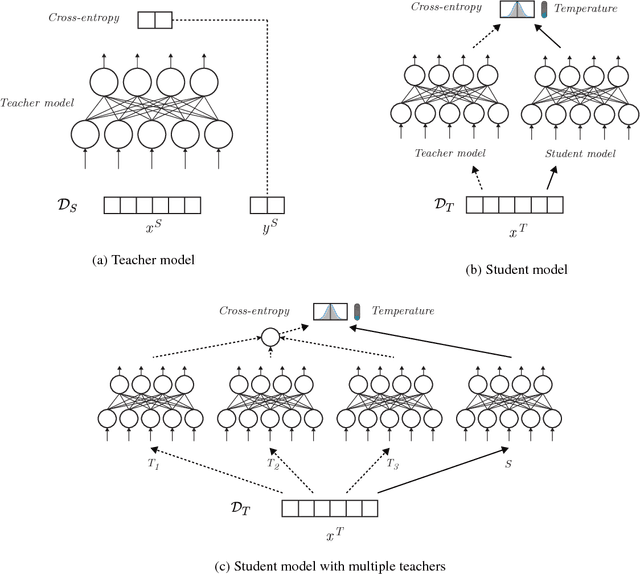

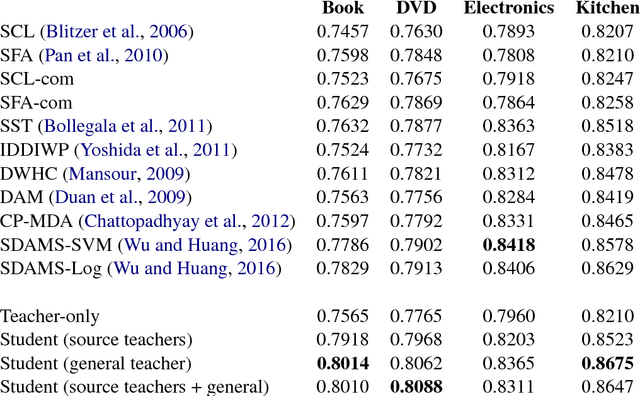
Domain adaptation is crucial in many real-world applications where the distribution of the training data differs from the distribution of the test data. Previous Deep Learning-based approaches to domain adaptation need to be trained jointly on source and target domain data and are therefore unappealing in scenarios where models need to be adapted to a large number of domains or where a domain is evolving, e.g. spam detection where attackers continuously change their tactics. To fill this gap, we propose Knowledge Adaptation, an extension of Knowledge Distillation (Bucilua et al., 2006; Hinton et al., 2015) to the domain adaptation scenario. We show how a student model achieves state-of-the-art results on unsupervised domain adaptation from multiple sources on a standard sentiment analysis benchmark by taking into account the domain-specific expertise of multiple teachers and the similarities between their domains. When learning from a single teacher, using domain similarity to gauge trustworthiness is inadequate. To this end, we propose a simple metric that correlates well with the teacher's accuracy in the target domain. We demonstrate that incorporating high-confidence examples selected by this metric enables the student model to achieve state-of-the-art performance in the single-source scenario.