 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting text decomposition methods for NLI-based factuality scoring of summaries
Nov 30, 2022



Scoring the factuality of a generated summary involves measuring the degree to which a target text contains factual information using the input document as support. Given the similarities in the problem formulation, previous work has shown that Natural Language Inference models can be effectively repurposed to perform this task. As these models are trained to score entailment at a sentence level, several recent studies have shown that decomposing either the input document or the summary into sentences helps with factuality scoring. But is fine-grained decomposition always a winning strategy? In this paper we systematically compare different granularities of decomposition -- from document to sub-sentence level, and we show that the answer is no. Our results show that incorporating additional context can yield improvement, but that this does not necessarily apply to all datasets. We also show that small changes to previously proposed entailment-based scoring methods can result in better performance, highlighting the need for caution in model and methodology selection for downstream tasks.
DynE: Dynamic Ensemble Decoding for Multi-Document Summarization
Jun 15, 2020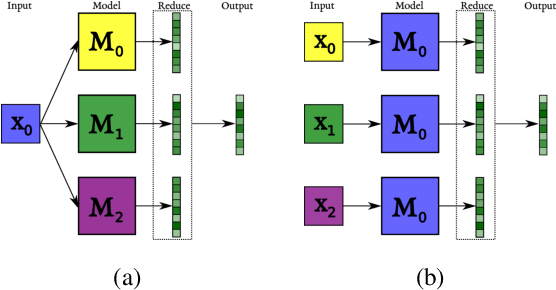
Sequence-to-sequence (s2s) models are the basis for extensive work in natural language processing. However, some applications, such as multi-document summarization, multi-modal machine translation, and the automatic post-editing of machine translation, require mapping a set of multiple distinct inputs into a single output sequence. Recent work has introduced bespoke architectures for these multi-input settings, and developed models which can handle increasingly longer inputs; however, the performance of special model architectures is limited by the available in-domain training data. In this work we propose a simple decoding methodology which ensembles the output of multiple instances of the same model on different inputs. Our proposed approach allows models trained for vanilla s2s tasks to be directly used in multi-input settings. This works particularly well when each of the inputs has significant overlap with the others, as when compressing a cluster of news articles about the same event into a single coherent summary, and we obtain state-of-the-art results on several multi-document summarization datasets.
A Large-Scale Multi-Document Summarization Dataset from the Wikipedia Current Events Portal
May 20, 2020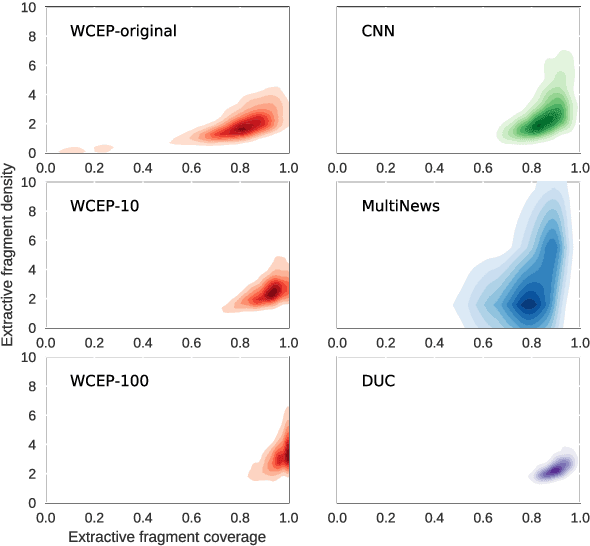

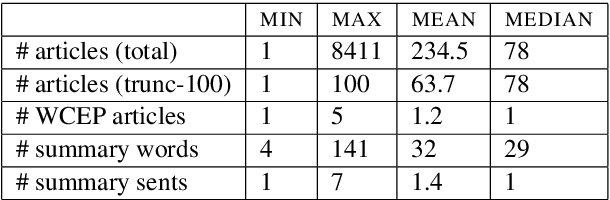
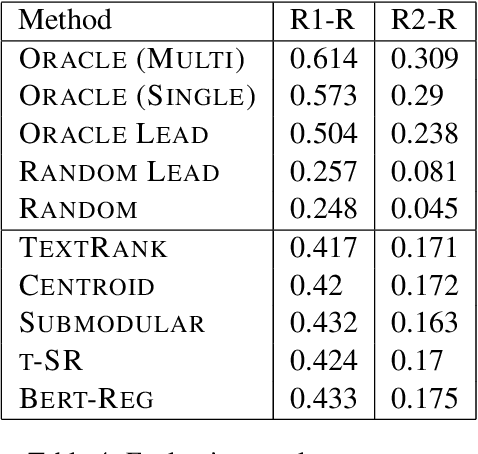
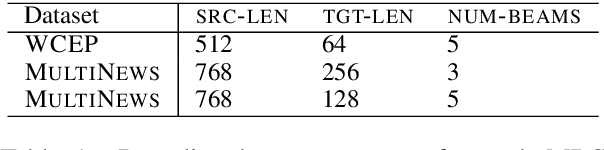
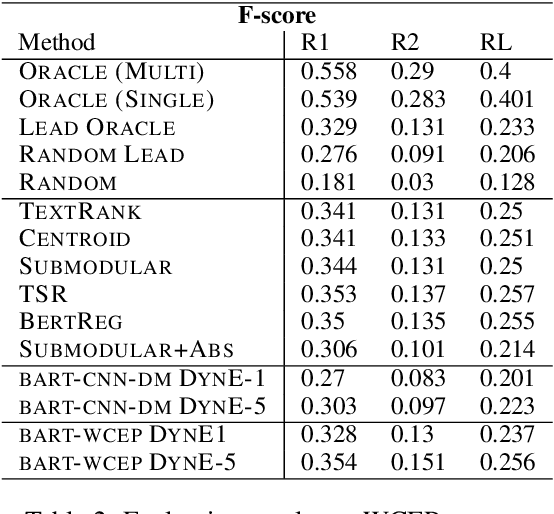
Multi-document summarization (MDS) aims to compress the content in large document collections into short summaries and has important applications in story clustering for newsfeeds, presentation of search results, and timeline generation. However, there is a lack of datasets that realistically address such use cases at a scale large enough for training supervised models for this task. This work presents a new dataset for MDS that is large both in the total number of document clusters and in the size of individual clusters. We build this dataset by leveraging the Wikipedia Current Events Portal (WCEP), which provides concise and neutral human-written summaries of news events, with links to external source articles. We also automatically extend these source articles by looking for related articles in the Common Crawl archive. We provide a quantitative analysis of the dataset and empirical results for several state-of-the-art MDS techniques.
Task Selection Policies for Multitask Learning
Jul 14, 2019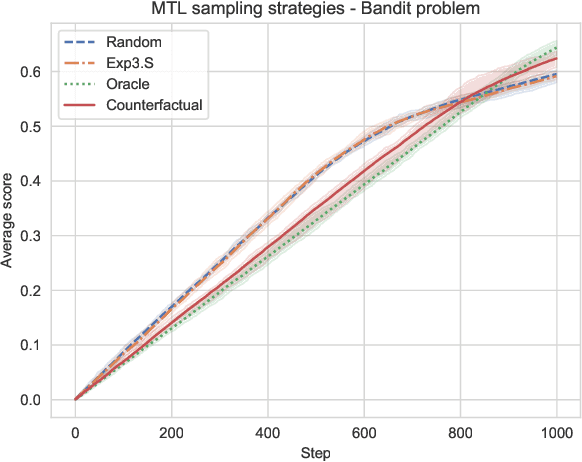

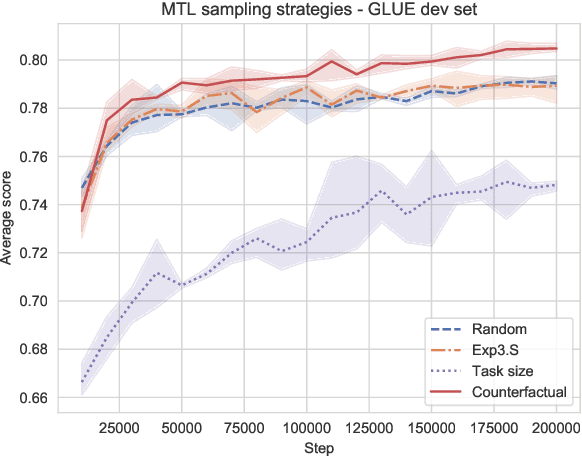

One of the questions that arises when designing models that learn to solve multiple tasks simultaneously is how much of the available training budget should be devoted to each individual task. We refer to any formalized approach to addressing this problem (learned or otherwise) as a task selection policy. In this work we provide an empirical evaluation of the performance of some common task selection policies in a synthetic bandit-style setting, as well as on the GLUE benchmark for natural language understanding. We connect task selection policy learning to existing work on automated curriculum learning and off-policy evaluation, and suggest a method based on counterfactual estimation that leads to improved model performance in our experimental settings.
Evaluating the Supervised and Zero-shot Performance of Multi-lingual Translation Models
Jun 24, 2019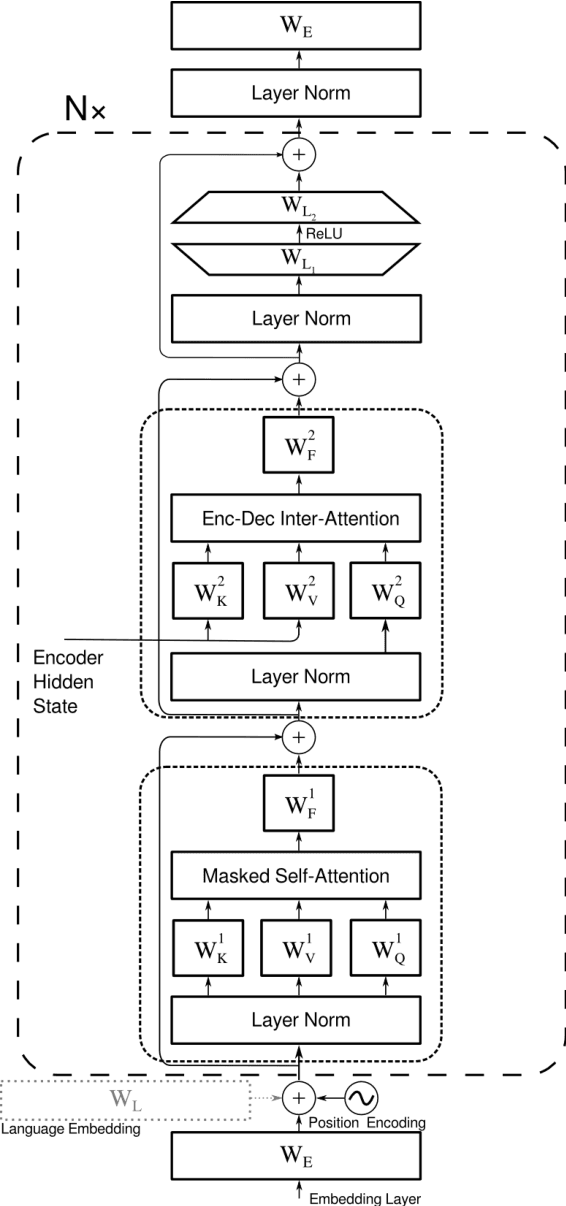
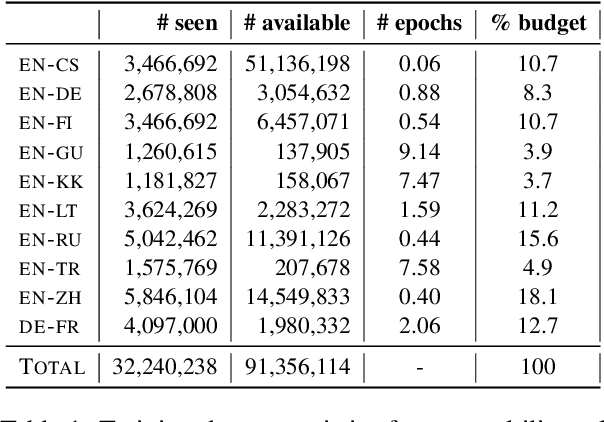
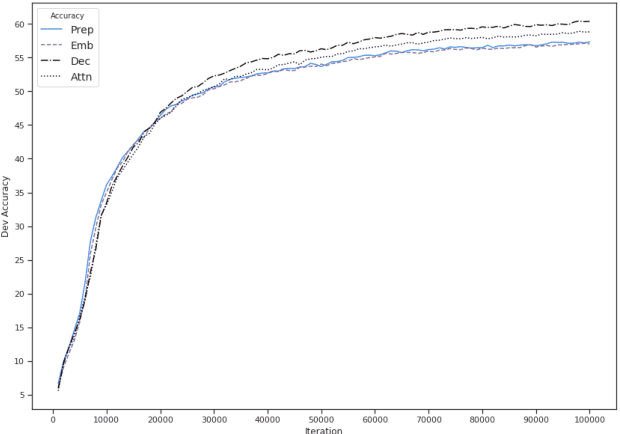
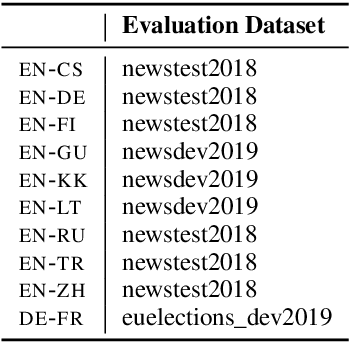
We study several methods for full or partial sharing of the decoder parameters of multilingual NMT models. We evaluate both fully supervised and zero-shot translation performance in 110 unique translation directions using only the WMT 2019 shared task parallel datasets for training. We use additional test sets and re-purpose evaluation methods recently used for unsupervised MT in order to evaluate zero-shot translation performance for language pairs where no gold-standard parallel data is available. To our knowledge, this is the largest evaluation of multi-lingual translation yet conducted in terms of the total size of the training data we use, and in terms of the diversity of zero-shot translation pairs we evaluate. We conduct an in-depth evaluation of the translation performance of different models, highlighting the trade-offs between methods of sharing decoder parameters. We find that models which have task-specific decoder parameters outperform models where decoder parameters are fully shared across all tasks.
Off-the-Shelf Unsupervised NMT
Nov 06, 2018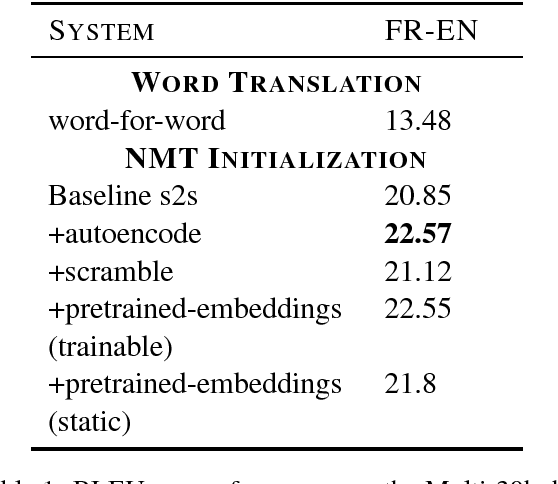
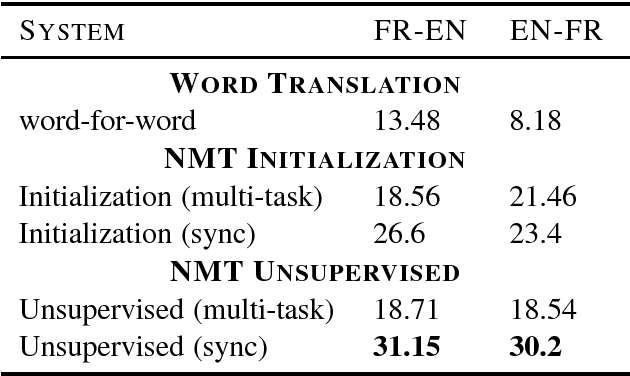
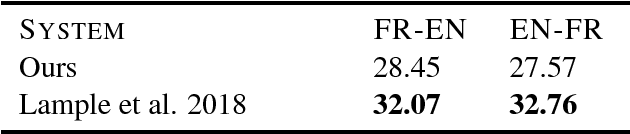

We frame unsupervised machine translation (MT) in the context of multi-task learning (MTL), combining insights from both directions. We leverage off-the-shelf neural MT architectures to train unsupervised MT models with no parallel data and show that such models can achieve reasonably good performance, competitive with models purpose-built for unsupervised MT. Finally, we propose improvements that allow us to apply our models to English-Turkish, a truly low-resource language pair.
360° Stance Detection
Apr 03, 2018
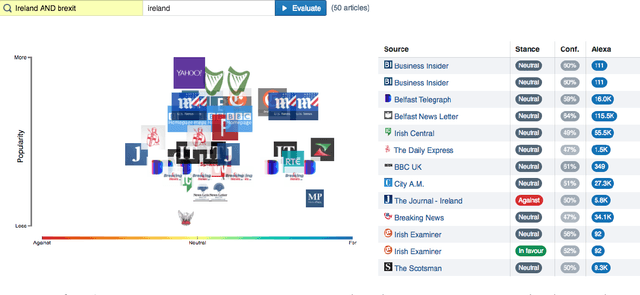

The proliferation of fake news and filter bubbles makes it increasingly difficult to form an unbiased, balanced opinion towards a topic. To ameliorate this, we propose 360{\deg} Stance Detection, a tool that aggregates news with multiple perspectives on a topic. It presents them on a spectrum ranging from support to opposition, enabling the user to base their opinion on multiple pieces of diverse evidence.
Modeling documents with Generative Adversarial Networks
Dec 29, 2016
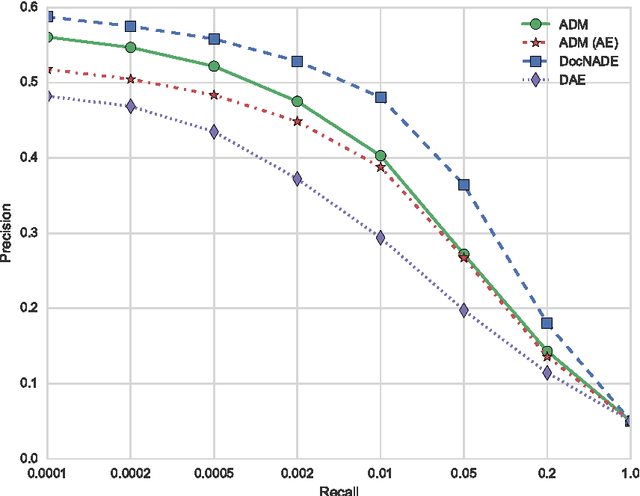
This paper describes a method for using Generative Adversarial Networks to learn distributed representations of natural language documents. We propose a model that is based on the recently proposed Energy-Based GAN, but instead uses a Denoising Autoencoder as the discriminator network. Document representations are extracted from the hidden layer of the discriminator and evaluated both quantitatively and qualitatively.