 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Selection Policies for Multitask Learning
Paper and Code
Jul 14, 2019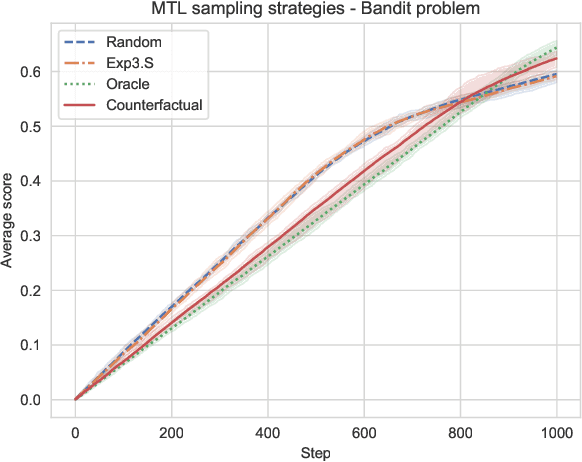

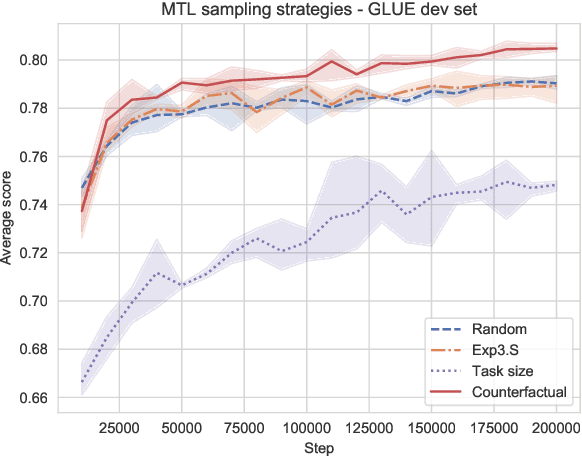

One of the questions that arises when designing models that learn to solve multiple tasks simultaneously is how much of the available training budget should be devoted to each individual task. We refer to any formalized approach to addressing this problem (learned or otherwise) as a task selection policy. In this work we provide an empirical evaluation of the performance of some common task selection policies in a synthetic bandit-style setting, as well as on the GLUE benchmark for natural language understanding. We connect task selection policy learning to existing work on automated curriculum learning and off-policy evaluation, and suggest a method based on counterfactual estimation that leads to improved model performance in our experimental settings.