 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynE: Dynamic Ensemble Decoding for Multi-Document Summarization
Paper and Code
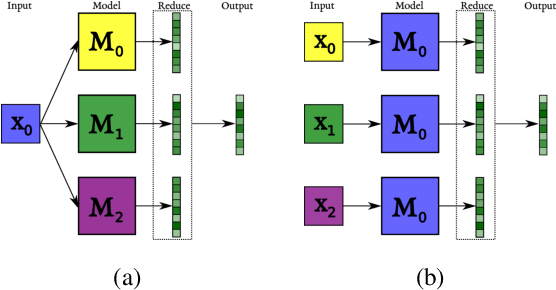
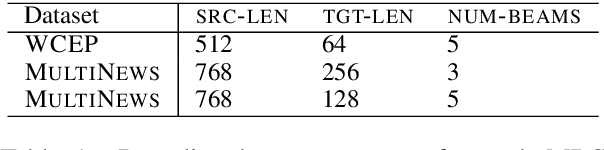
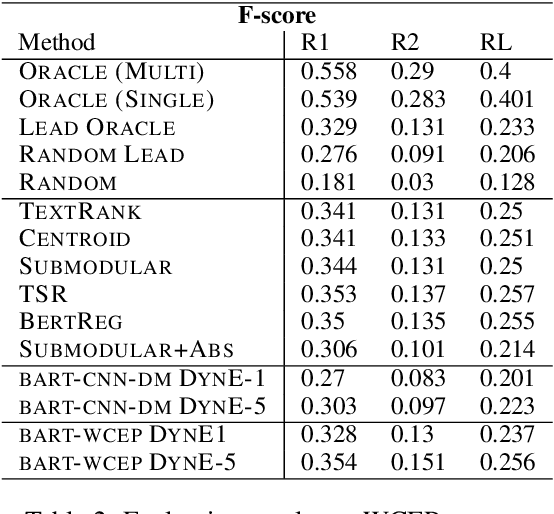
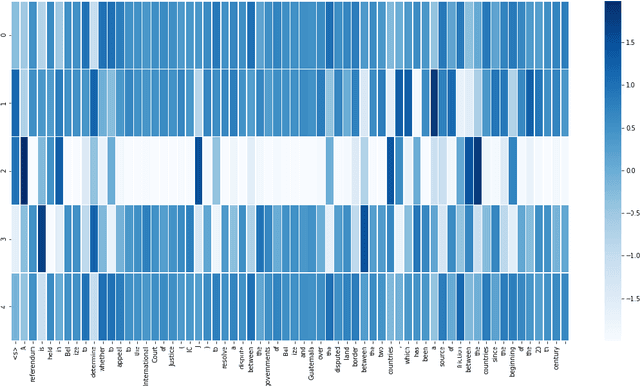
Sequence-to-sequence (s2s) models are the basis for extensive work in natural language processing. However, some applications, such as multi-document summarization, multi-modal machine translation, and the automatic post-editing of machine translation, require mapping a set of multiple distinct inputs into a single output sequence. Recent work has introduced bespoke architectures for these multi-input settings, and developed models which can handle increasingly longer inputs; however, the performance of special model architectures is limited by the available in-domain training data. In this work we propose a simple decoding methodology which ensembles the output of multiple instances of the same model on different inputs. Our proposed approach allows models trained for vanilla s2s tasks to be directly used in multi-input settings. This works particularly well when each of the inputs has significant overlap with the others, as when compressing a cluster of news articles about the same event into a single coherent summary, and we obtain state-of-the-art results on several multi-document summarization datasets.