 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynE: Dynamic Ensemble Decoding for Multi-Document Summarization
Jun 15, 2020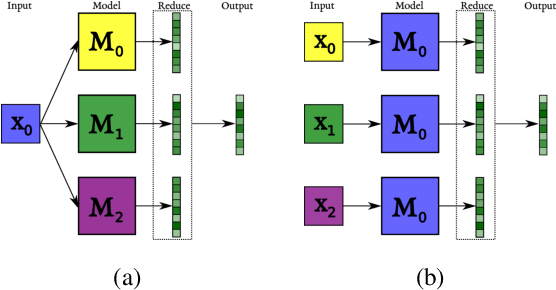
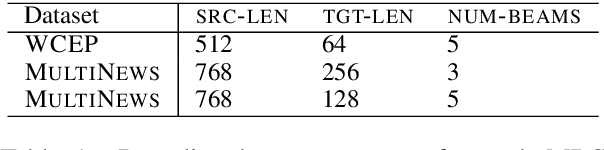
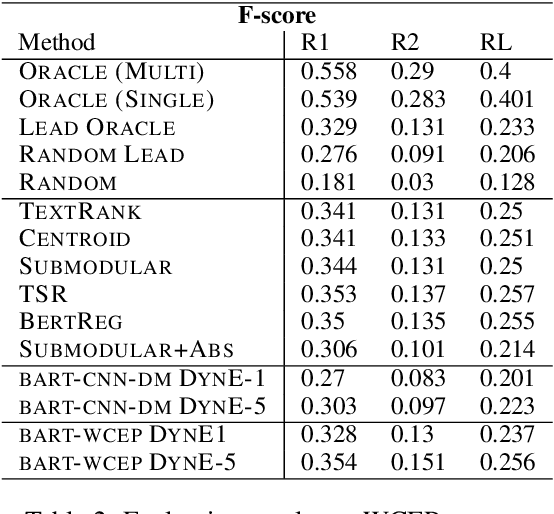
Sequence-to-sequence (s2s) models are the basis for extensive work in natural language processing. However, some applications, such as multi-document summarization, multi-modal machine translation, and the automatic post-editing of machine translation, require mapping a set of multiple distinct inputs into a single output sequence. Recent work has introduced bespoke architectures for these multi-input settings, and developed models which can handle increasingly longer inputs; however, the performance of special model architectures is limited by the available in-domain training data. In this work we propose a simple decoding methodology which ensembles the output of multiple instances of the same model on different inputs. Our proposed approach allows models trained for vanilla s2s tasks to be directly used in multi-input settings. This works particularly well when each of the inputs has significant overlap with the others, as when compressing a cluster of news articles about the same event into a single coherent summary, and we obtain state-of-the-art results on several multi-document summarization datasets.
A Large-Scale Multi-Document Summarization Dataset from the Wikipedia Current Events Portal
May 20, 2020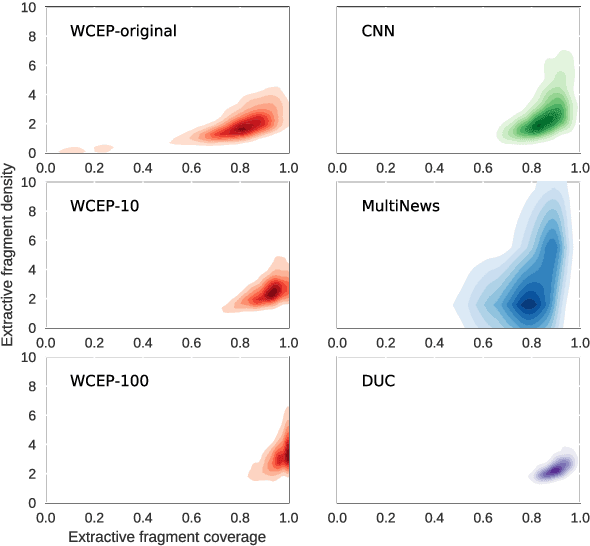

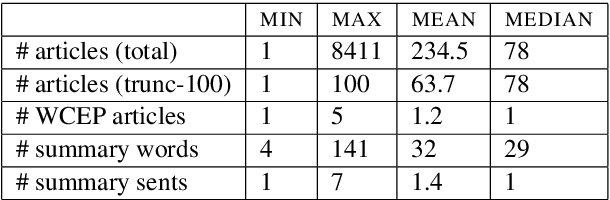
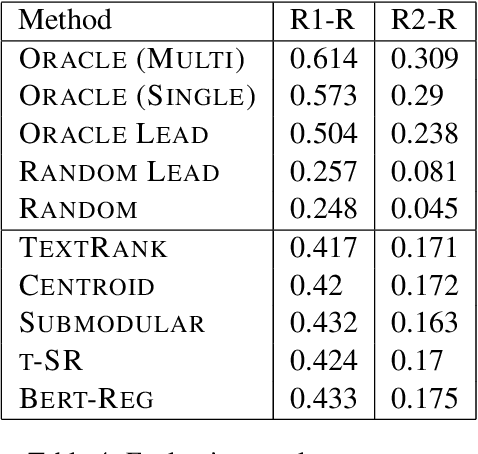
Multi-document summarization (MDS) aims to compress the content in large document collections into short summaries and has important applications in story clustering for newsfeeds, presentation of search results, and timeline generation. However, there is a lack of datasets that realistically address such use cases at a scale large enough for training supervised models for this task. This work presents a new dataset for MDS that is large both in the total number of document clusters and in the size of individual clusters. We build this dataset by leveraging the Wikipedia Current Events Portal (WCEP), which provides concise and neutral human-written summaries of news events, with links to external source articles. We also automatically extend these source articles by looking for related articles in the Common Crawl archive. We provide a quantitative analysis of the dataset and empirical results for several state-of-the-art MDS techniques.
Living a discrete life in a continuous world: Reference with distributed representations
Sep 04, 2017
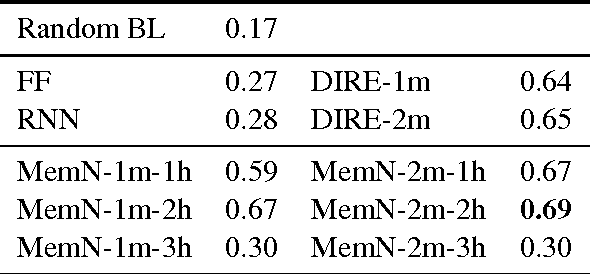
Reference is a crucial property of language that allows us to connect linguistic expressions to the world. Modeling it requires handling both continuous and discrete aspects of meaning. Data-driven models excel at the former, but struggle with the latter, and the reverse is true for symbolic models. This paper (a) introduces a concrete referential task to test both aspects, called cross-modal entity tracking; (b) proposes a neural network architecture that uses external memory to build an entity library inspired in the DRSs of DRT, with a mechanism to dynamically introduce new referents or add information to referents that are already in the library. Our model shows promise: it beats traditional neural network architectures on the task. However, it is still outperformed by Memory Networks, another model with external memory.
Towards Multi-Agent Communication-Based Language Learning
May 23, 2016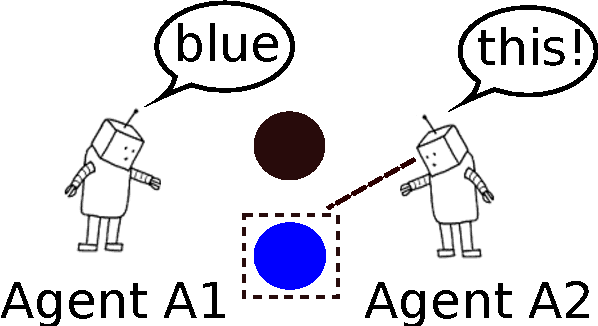

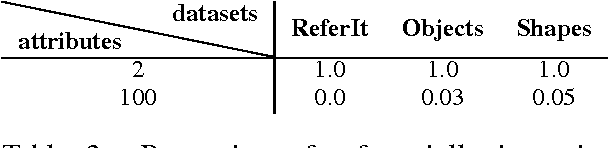
We propose an interactive multimodal framework for language learning. Instead of being passively exposed to large amounts of natural text, our learners (implemented as feed-forward neural networks) engage in cooperative referential games starting from a tabula rasa setup, and thus develop their own language from the need to communicate in order to succeed at the game. Preliminary experiments provide promising results, but also suggest that it is important to ensure that agents trained in this way do not develop an adhoc communication code only effective for the game they are playing
The red one!: On learning to refer to things based on their discriminative properties
May 23, 2016


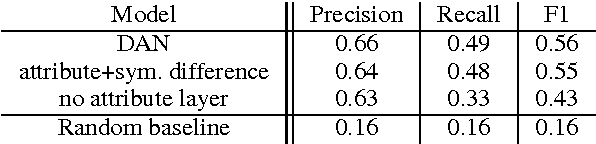
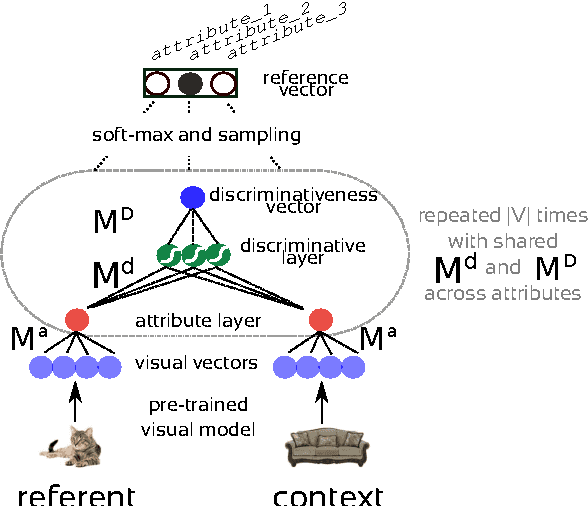
As a first step towards agents learning to communicate about their visual environment, we propose a system that, given visual representations of a referent (cat) and a context (sofa), identifies their discriminative attributes, i.e., properties that distinguish them (has_tail). Moreover, despite the lack of direct supervision at the attribute level, the model learns to assign plausible attributes to objects (sofa-has_cushion). Finally, we present a preliminary experiment confirming the referential success of the predicted discriminative attributes.
Combining Language and Vision with a Multimodal Skip-gram Model
Mar 12, 2015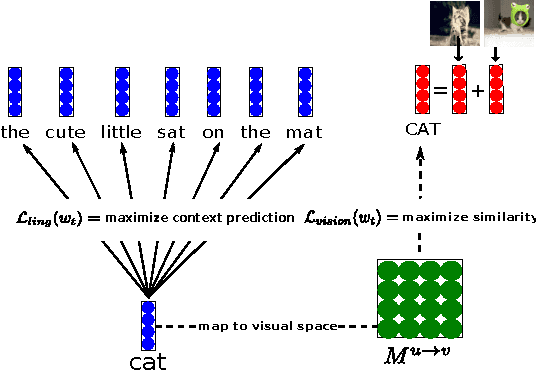

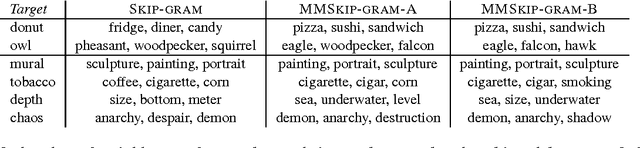
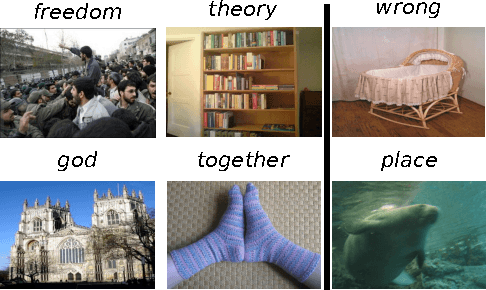
We extend the SKIP-GRAM model of Mikolov et al. (2013a) by taking visual information into account. Like SKIP-GRAM, our multimodal models (MMSKIP-GRAM) build vector-based word representations by learning to predict linguistic contexts in text corpora. However, for a restricted set of words, the models are also exposed to visual representations of the objects they denote (extracted from natural images), and must predict linguistic and visual features jointly. The MMSKIP-GRAM models achieve good performance on a variety of semantic benchmarks. Moreover, since they propagate visual information to all words, we use them to improve image labeling and retrieval in the zero-shot setup, where the test concepts are never seen during model training. Finally, the MMSKIP-GRAM models discover intriguing visual properties of abstract words, paving the way to realistic implementations of embodied theories of meaning.