 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Architectures for Supervised Political Scaling
Jul 01, 2026Text scaling, the task of positioning political actors on an ideological scale, is a fundamental task in political analysis. To ease the need for manual analysis, various NLP methods have been proposed for this task, including classification- and regression-based approaches, showing successes as well as limitations. The goal of our paper is to consolidate the state of the art in this area. We ask two questions: (a) Can the performance of scaling methods be improved by predicting scales not individually but jointly? (b) Is there a middle ground between classification and regression?
AmchiBias: Measuring Stereotypical Bias in Goan Identity Groups with a Minimal Pair Dataset in English and Konkani
Jun 13, 2026Socio-cultural stereotypical bias is an important consideration in the development and deployment of NLP systems. It is however often considered only at the national level, despite rich subnational socio-cultural structures. We present AmchiBias, the first benchmark for measuring socio-cultural stereotypical bias for the Indian state of Goa with its unique historically multicultural setting. It covers various Goan identity groups and comprises 313 minimal pairs across eight sociodemographic dimensions in both English and Devanagari Konkani. We then evaluate stereotypical bias in five multilingual encoder models on this benchmark. We find near-chance scores in Konkani, reflecting language incompetence for general multilingual models and a lack of Goan cultural competence for Indian language models. Queried in English, models with a stronger Indian language coverage show higher bias for pan-Indian groups than hyperlocal Goan groups. This suggests the English signal reflects pan-Indian pretraining associations rather than genuine Goan cultural knowledge. Our findings highlight a critical gap in low-resource multilingual NLP evaluation for hyperlocal community identities.
Do Language Models Encode Knowledge of Linguistic Constraint Violations?
May 14, 2026Large Language Models (LLMs) achieve strong linguistic performance, yet their internal mechanisms for producing these predictions remain unclear. We investigate the hypothesis that LLMs encode representations of linguistic constraint violations within their parameters, which are selectively activated when processing ungrammatical sentences. To test this, we use sparse autoencoders to decompose polysemantic activations into sparse, monosemantic features and recover candidates for violation-related features. We introduce a sensitivity score for identifying features that are preferentially activated on constraint-violated versus well-formed inputs, enabling unsupervised detection of potential violation-specific features. We further propose a conjunctive falsification framework with three criteria evaluated jointly. Overall, the results are negative in two respects: (1) the falsification criteria are not jointly satisfied across linguistic phenomena, and (2) no features are consistently shared across all categories. While some phenomena show partial evidence of selective causal structure, the overall pattern provides limited support for a unified set of grammatical violation detectors in current LMs.
Diverging Transformer Predictions for Human Sentence Processing: A Comprehensive Analysis of Agreement Attraction Effects
Mar 17, 2026Transformers underlie almost all state-of-the-art language models in computational linguistics, yet their cognitive adequacy as models of human sentence processing remains disputed. In this work, we use a surprisal-based linking mechanism to systematically evaluate eleven autoregressive transformers of varying sizes and architectures on a more comprehensive set of English agreement attraction configurations than prior work. Our experiments yield mixed results: While transformer predictions generally align with human reading time data for prepositional phrase configurations, performance degrades significantly on object-extracted relative clause configurations. In the latter case, predictions also diverge markedly across models, and no model successfully replicates the asymmetric interference patterns observed in humans. We conclude that current transformer models do not explain human morphosyntactic processing, and that evaluations of transformers as cognitive models must adopt rigorous, comprehensive experimental designs to avoid spurious generalizations from isolated syntactic configurations or individual models.
Finding Sense in Nonsense with Generated Contexts: Perspectives from Humans and Language Models
Feb 13, 2026Nonsensical and anomalous sentences have been instrumental in the development of computational models of semantic interpretation. A core challenge is to distinguish between what is merely anomalous (but can be interpreted given a supporting context) and what is truly nonsensical. However, it is unclear (a) how nonsensical, rather than merely anomalous, existing datasets are; and (b) how well LLMs can make this distinction. In this paper, we answer both questions by collecting sensicality judgments from human raters and LLMs on sentences from five semantically deviant datasets: both context-free and when providing a context. We find that raters consider most sentences at most anomalous, and only a few as properly nonsensical. We also show that LLMs are substantially skilled in generating plausible contexts for anomalous cases.
One Persona, Many Cues, Different Results: How Sociodemographic Cues Impact LLM Personalization
Jan 26, 2026Personalization of LLMs by sociodemographic subgroup often improves user experience, but can also introduce or amplify biases and unfair outcomes across groups. Prior work has employed so-called personas, sociodemographic user attributes conveyed to a model, to study bias in LLMs by relying on a single cue to prompt a persona, such as user names or explicit attribute mentions. This disregards LLM sensitivity to prompt variations (robustness) and the rarity of some cues in real interactions (external validity). We compare six commonly used persona cues across seven open and proprietary LLMs on four writing and advice tasks. While cues are overall highly correlated, they produce substantial variance in responses across personas. We therefore caution against claims from a single persona cue and recommend future personalization research to evaluate multiple externally valid cues.
Beyond Marginal Distributions: A Framework to Evaluate the Representativeness of Demographic-Aligned LLMs
Jan 22, 2026Large language models are increasingly used to represent human opinions, values, or beliefs, and their steerability towards these ideals is an active area of research. Existing work focuses predominantly on aligning marginal response distributions, treating each survey item independently. While essential, this may overlook deeper latent structures that characterise real populations and underpin cultural values theories. We propose a framework for evaluating the representativeness of aligned models through multivariate correlation patterns in addition to marginal distributions. We show the value of our evaluation scheme by comparing two model steering techniques (persona prompting and demographic fine-tuning) and evaluating them against human responses from the World Values Survey. While the demographically fine-tuned model better approximates marginal response distributions than persona prompting, both techniques fail to fully capture the gold standard correlation patterns. We conclude that representativeness is a distinct aspect of value alignment and an evaluation focused on marginals can mask structural failures, leading to overly optimistic conclusions about model capabilities.
Do Political Opinions Transfer Between Western Languages? An Analysis of Unaligned and Aligned Multilingual LLMs
Aug 07, 2025



Public opinion surveys show cross-cultural differences in political opinions between socio-cultural contexts. However, there is no clear evidence whether these differences translate to cross-lingual differences in multilingual large language models (MLLMs). We analyze whether opinions transfer between languages or whether there are separate opinions for each language in MLLMs of various sizes across five Western languages. We evaluate MLLMs' opinions by prompting them to report their (dis)agreement with political statements from voting advice applications. To better understand the interaction between languages in the models, we evaluate them both before and after aligning them with more left or right views using direct preference optimization and English alignment data only. Our findings reveal that unaligned models show only very few significant cross-lingual differences in the political opinions they reflect. The political alignment shifts opinions almost uniformly across all five languages. We conclude that in Western language contexts, political opinions transfer between languages, demonstrating the challenges in achieving explicit socio-linguistic, cultural, and political alignment of MLLMs.
Computational Analysis of Gender Depiction in the Comedias of Calderón de la Barca
Nov 06, 2024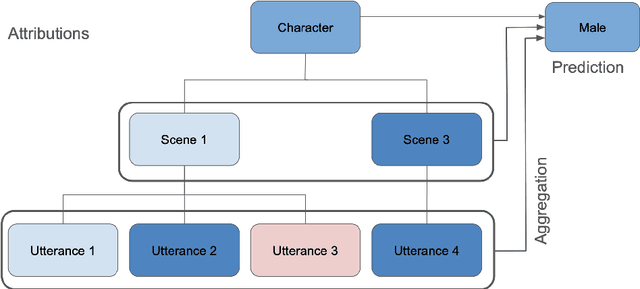
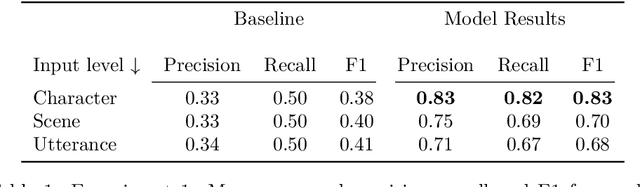

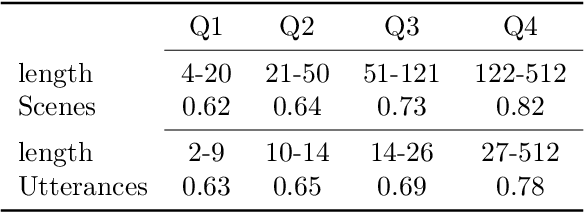
In theatre, playwrights use the portrayal of characters to explore culturally based gender norms. In this paper, we develop quantitative methods to study gender depiction in the non-religious works (comedias) of Pedro Calder\'on de la Barca, a prolific Spanish 17th century author. We gather insights from a corpus of more than 100 plays by using a gender classifier and applying model explainability (attribution) methods to determine which text features are most influential in the model's decision to classify speech as 'male' or 'female', indicating the most gendered elements of dialogue in Calder\'on's comedias in a human accessible manner. We find that female and male characters are portrayed differently and can be identified by the gender prediction model at practically useful accuracies (up to f=0.83). Analysis reveals semantic aspects of gender portrayal, and demonstrates that the model is even useful in providing a relatively accurate scene-by-scene prediction of cross-dressing characters.
Toeing the Party Line: Election Manifestos as a Key to Understand Political Discourse on Twitter
Oct 21, 2024
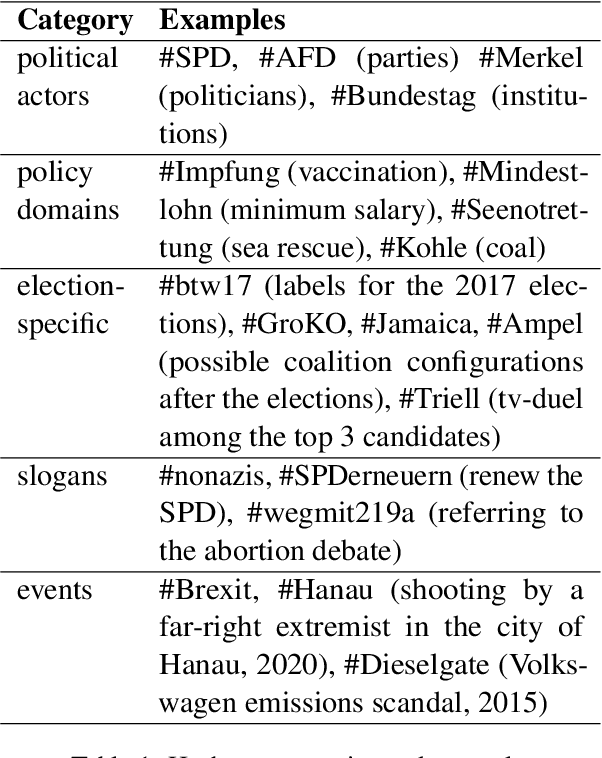
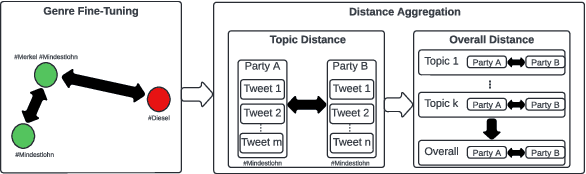
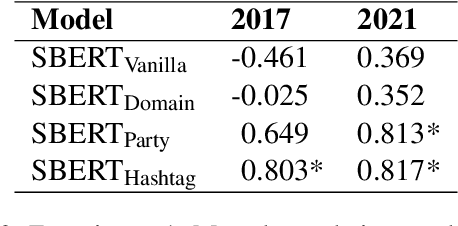
Political discourse on Twitter is a moving target: politicians continuously make statements about their positions. It is therefore crucial to track their discourse on social media to understand their ideological positions and goals. However, Twitter data is also challenging to work with since it is ambiguous and often dependent on social context, and consequently, recent work on political positioning has tended to focus strongly on manifestos (parties' electoral programs) rather than social media. In this paper, we extend recently proposed methods to predict pairwise positional similarities between parties from the manifesto case to the Twitter case, using hashtags as a signal to fine-tune text representations, without the need for manual annotation. We verify the efficacy of fine-tuning and conduct a series of experiments that assess the robustness of our method for low-resource scenarios. We find that our method yields stable positioning reflective of manifesto positioning, both in scenarios with all tweets of candidates across years available and when only smaller subsets from shorter time periods are available. This indicates that it is possible to reliably analyze the relative positioning of actors forgoing manual annotation, even in the noisier context of social media.