 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Perspectivist Turn in Argument Quality Assessment
Feb 20, 2025The assessment of argument quality depends on well-established logical, rhetorical, and dialectical properties that are unavoidably subjective: multiple valid assessments may exist, there is no unequivocal ground truth. This aligns with recent paths in machine learning, which embrace the co-existence of different perspectives. However, this potential remains largely unexplored in NLP research on argument quality. One crucial reason seems to be the yet unexplored availability of suitable datasets. We fill this gap by conducting a systematic review of argument quality datasets. We assign them to a multi-layered categorization targeting two aspects: (a) What has been annotated: we collect the quality dimensions covered in datasets and consolidate them in an overarching taxonomy, increasing dataset comparability and interoperability. (b) Who annotated: we survey what information is given about annotators, enabling perspectivist research and grounding our recommendations for future actions. To this end, we discuss datasets suitable for developing perspectivist models (i.e., those containing individual, non-aggregated annotations), and we showcase the importance of a controlled selection of annotators in a pilot study.
Toeing the Party Line: Election Manifestos as a Key to Understand Political Discourse on Twitter
Oct 21, 2024
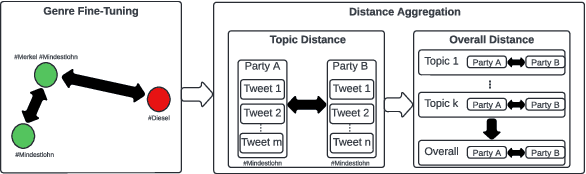
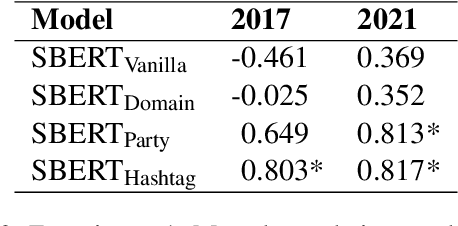
Political discourse on Twitter is a moving target: politicians continuously make statements about their positions. It is therefore crucial to track their discourse on social media to understand their ideological positions and goals. However, Twitter data is also challenging to work with since it is ambiguous and often dependent on social context, and consequently, recent work on political positioning has tended to focus strongly on manifestos (parties' electoral programs) rather than social media. In this paper, we extend recently proposed methods to predict pairwise positional similarities between parties from the manifesto case to the Twitter case, using hashtags as a signal to fine-tune text representations, without the need for manual annotation. We verify the efficacy of fine-tuning and conduct a series of experiments that assess the robustness of our method for low-resource scenarios. We find that our method yields stable positioning reflective of manifesto positioning, both in scenarios with all tweets of candidates across years available and when only smaller subsets from shorter time periods are available. This indicates that it is possible to reliably analyze the relative positioning of actors forgoing manual annotation, even in the noisier context of social media.