 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Subjective Factors of Argument Strength: Storytelling, Emotions, and Hedging
Jul 23, 2025In assessing argument strength, the notions of what makes a good argument are manifold. With the broader trend towards treating subjectivity as an asset and not a problem in NLP, new dimensions of argument quality are studied. Although studies on individual subjective features like personal stories exist, there is a lack of large-scale analyses of the relation between these features and argument strength. To address this gap, we conduct regression analysis to quantify the impact of subjective factors $-$ emotions, storytelling, and hedging $-$ on two standard datasets annotated for objective argument quality and subjective persuasion. As such, our contribution is twofold: at the level of contributed resources, as there are no datasets annotated with all studied dimensions, this work compares and evaluates automated annotation methods for each subjective feature. At the level of novel insights, our regression analysis uncovers different patterns of impact of subjective features on the two facets of argument strength encoded in the datasets. Our results show that storytelling and hedging have contrasting effects on objective and subjective argument quality, while the influence of emotions depends on their rhetoric utilization rather than the domain.
Overview of PerpectiveArg2024: The First Shared Task on Perspective Argument Retrieval
Jul 29, 2024


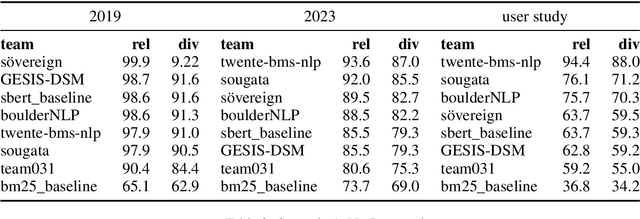
Argument retrieval is the task of finding relevant arguments for a given query. While existing approaches rely solely on the semantic alignment of queries and arguments, this first shared task on perspective argument retrieval incorporates perspectives during retrieval, accounting for latent influences in argumentation. We present a novel multilingual dataset covering demographic and socio-cultural (socio) variables, such as age, gender, and political attitude, representing minority and majority groups in society. We distinguish between three scenarios to explore how retrieval systems consider explicitly (in both query and corpus) and implicitly (only in query) formulated perspectives. This paper provides an overview of this shared task and summarizes the results of the six submitted systems. We find substantial challenges in incorporating perspectivism, especially when aiming for personalization based solely on the text of arguments without explicitly providing socio profiles. Moreover, retrieval systems tend to be biased towards the majority group but partially mitigate bias for the female gender. While we bootstrap perspective argument retrieval, further research is essential to optimize retrieval systems to facilitate personalization and reduce polarization.
Annotator-Centric Active Learning for Subjective NLP Tasks
Apr 24, 2024



To accurately capture the variability in human judgments for subjective NLP tasks, incorporating a wide range of perspectives in the annotation process is crucial. Active Learning (AL) addresses the high costs of collecting human annotations by strategically annotating the most informative samples. We introduce Annotator-Centric Active Learning (ACAL), which incorporates an annotator selection strategy following data sampling. Our objective is two-fold: (1) to efficiently approximate the full diversity of human judgments, and to assess model performance using annotator-centric metrics, which emphasize minority perspectives over a majority. We experiment with multiple annotator selection strategies across seven subjective NLP tasks, employing both traditional and novel, human-centered evaluation metrics. Our findings indicate that ACAL improves data efficiency and excels in annotator-centric performance evaluations. However, its success depends on the availability of a sufficiently large and diverse pool of annotators to sample from.
Beyond prompt brittleness: Evaluating the reliability and consistency of political worldviews in LLMs
Feb 27, 2024Due to the widespread use of large language models (LLMs) in ubiquitous systems, we need to understand whether they embed a specific worldview and what these views reflect. Recent studies report that, prompted with political questionnaires, LLMs show left-liberal leanings. However, it is as yet unclear whether these leanings are reliable (robust to prompt variations) and whether the leaning is consistent across policies and political leaning. We propose a series of tests which assess the reliability and consistency of LLMs' stances on political statements based on a dataset of voting-advice questionnaires collected from seven EU countries and annotated for policy domains. We study LLMs ranging in size from 7B to 70B parameters and find that their reliability increases with parameter count. Larger models show overall stronger alignment with left-leaning parties but differ among policy programs: They evince a (left-wing) positive stance towards environment protection, social welfare but also (right-wing) law and order, with no consistent preferences in foreign policy, migration, and economy.
NAP at SemEval-2023 Task 3: Is Less Really More? Translation as Data Augmentation Strategies for Detecting Persuasion Techniques
Apr 27, 2023



Persuasion techniques detection in news in a multi-lingual setup is non-trivial and comes with challenges, including little training data. Our system successfully leverages (back-)translation as data augmentation strategies with multi-lingual transformer models for the task of detecting persuasion techniques. The automatic and human evaluation of our augmented data allows us to explore whether (back-)translation aid or hinder performance. Our in-depth analyses indicate that both data augmentation strategies boost performance; however, balancing human-produced and machine-generated data seems to be crucial.