 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLived Experience in Dialogue: Co-designing Personalization in Large Language Models to Support Youth Mental Well-being
Nov 07, 2025Youth increasingly turn to large language models (LLMs) for mental well-being support, yet current personalization in LLMs can overlook the heterogeneous lived experiences shaping their needs. We conducted a participatory study with youth, parents, and youth care workers (N=38), using co-created youth personas as scaffolds, to elicit community perspectives on how LLMs can facilitate more meaningful personalization to support youth mental well-being. Analysis identified three themes: person-centered contextualization responsive to momentary needs, explicit boundaries around scope and offline referral, and dialogic scaffolding for reflection and autonomy. We mapped these themes to persuasive design features for task suggestions, social facilitation, and system trustworthiness, and created corresponding dialogue extracts to guide LLM fine-tuning. Our findings demonstrate how lived experience can be operationalized to inform design features in LLMs, which can enhance the alignment of LLM-based interventions with the realities of youth and their communities, contributing to more effectively personalized digital well-being tools.
Taking a SEAT: Predicting Value Interpretations from Sentiment, Emotion, Argument, and Topic Annotations
Oct 02, 2025Our interpretation of value concepts is shaped by our sociocultural background and lived experiences, and is thus subjective. Recognizing individual value interpretations is important for developing AI systems that can align with diverse human perspectives and avoid bias toward majority viewpoints. To this end, we investigate whether a language model can predict individual value interpretations by leveraging multi-dimensional subjective annotations as a proxy for their interpretive lens. That is, we evaluate whether providing examples of how an individual annotates Sentiment, Emotion, Argument, and Topics (SEAT dimensions) helps a language model in predicting their value interpretations. Our experiment across different zero- and few-shot settings demonstrates that providing all SEAT dimensions simultaneously yields superior performance compared to individual dimensions and a baseline where no information about the individual is provided. Furthermore, individual variations across annotators highlight the importance of accounting for the incorporation of individual subjective annotators. To the best of our knowledge, this controlled setting, although small in size, is the first attempt to go beyond demographics and investigate the impact of annotation behavior on value prediction, providing a solid foundation for future large-scale validation.
Signs of Struggle: Spotting Cognitive Distortions across Language and Register
Aug 28, 2025



Rising mental health issues among youth have increased interest in automated approaches for detecting early signs of psychological distress in digital text. One key focus is the identification of cognitive distortions, irrational thought patterns that have a role in aggravating mental distress. Early detection of these distortions may enable timely, low-cost interventions. While prior work has focused on English clinical data, we present the first in-depth study of cross-lingual and cross-register generalization of cognitive distortion detection, analyzing forum posts written by Dutch adolescents. Our findings show that while changes in language and writing style can significantly affect model performance, domain adaptation methods show the most promise.
News is More than a Collection of Facts: Moral Frame Preserving News Summarization
Apr 01, 2025News articles are more than collections of facts; they reflect journalists' framing, shaping how events are presented to the audience. One key aspect of framing is the choice to write in (or quote verbatim) morally charged language as opposed to using neutral terms. This moral framing carries implicit judgments that automated news summarizers should recognize and preserve to maintain the original intent of the writer. In this work, we perform the first study on the preservation of moral framing in AI-generated news summaries. We propose an approach that leverages the intuition that journalists intentionally use or report specific moral-laden words, which should be retained in summaries. Through automated, crowd-sourced, and expert evaluations, we demonstrate that our approach enhances the preservation of moral framing while maintaining overall summary quality.
Annotator-Centric Active Learning for Subjective NLP Tasks
Apr 24, 2024



To accurately capture the variability in human judgments for subjective NLP tasks, incorporating a wide range of perspectives in the annotation process is crucial. Active Learning (AL) addresses the high costs of collecting human annotations by strategically annotating the most informative samples. We introduce Annotator-Centric Active Learning (ACAL), which incorporates an annotator selection strategy following data sampling. Our objective is two-fold: (1) to efficiently approximate the full diversity of human judgments, and to assess model performance using annotator-centric metrics, which emphasize minority perspectives over a majority. We experiment with multiple annotator selection strategies across seven subjective NLP tasks, employing both traditional and novel, human-centered evaluation metrics. Our findings indicate that ACAL improves data efficiency and excels in annotator-centric performance evaluations. However, its success depends on the availability of a sufficiently large and diverse pool of annotators to sample from.
A Hybrid Intelligence Method for Argument Mining
Mar 11, 2024



Large-scale survey tools enable the collection of citizen feedback in opinion corpora. Extracting the key arguments from a large and noisy set of opinions helps in understanding the opinions quickly and accurately. Fully automated methods can extract arguments but (1) require large labeled datasets that induce large annotation costs and (2) work well for known viewpoints, but not for novel points of view. We propose HyEnA, a hybrid (human + AI) method for extracting arguments from opinionated texts, combining the speed of automated processing with the understanding and reasoning capabilities of humans. We evaluate HyEnA on three citizen feedback corpora. We find that, on the one hand, HyEnA achieves higher coverage and precision than a state-of-the-art automated method when compared to a common set of diverse opinions, justifying the need for human insight. On the other hand, HyEnA requires less human effort and does not compromise quality compared to (fully manual) expert analysis, demonstrating the benefit of combining human and artificial intelligence.
Value Preferences Estimation and Disambiguation in Hybrid Participatory Systems
Feb 26, 2024Understanding citizens' values in participatory systems is crucial for citizen-centric policy-making. We envision a hybrid participatory system where participants make choices and provide motivations for those choices, and AI agents estimate their value preferences by interacting with them. We focus on situations where a conflict is detected between participants' choices and motivations, and propose methods for estimating value preferences while addressing detected inconsistencies by interacting with the participants. We operationalize the philosophical stance that "valuing is deliberatively consequential." That is, if a participant's choice is based on a deliberation of value preferences, the value preferences can be observed in the motivation the participant provides for the choice. Thus, we propose and compare value estimation methods that prioritize the values estimated from motivations over the values estimated from choices alone. Then, we introduce a disambiguation strategy that addresses the detected inconsistencies between choices and motivations by directly interacting with the participants. We evaluate the proposed methods on a dataset of a large-scale survey on energy transition. The results show that explicitly addressing inconsistencies between choices and motivations improves the estimation of an individual's value preferences. The disambiguation strategy does not show substantial improvements when compared to similar baselines--however, we discuss how the novelty of the approach can open new research avenues and propose improvements to address the current limitations.
Morality is Non-Binary: Building a Pluralist Moral Sentence Embedding Space using Contrastive Learning
Jan 30, 2024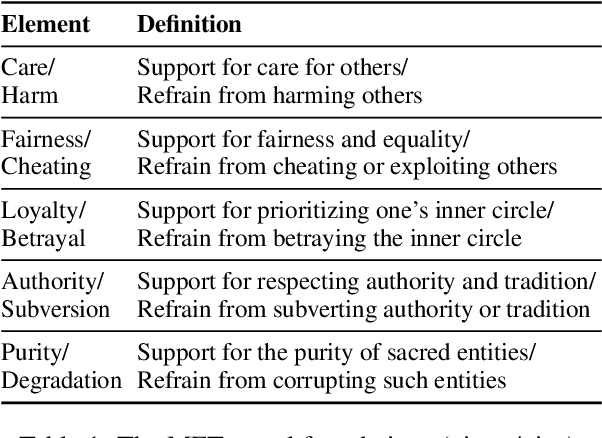
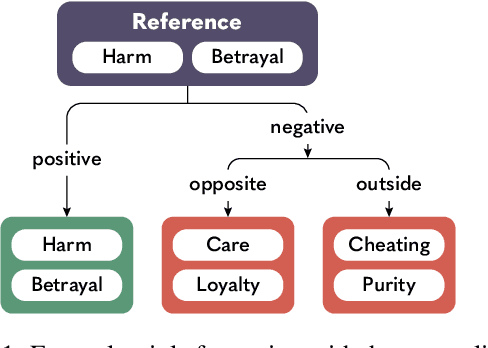

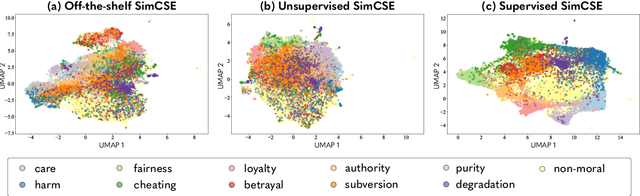
Recent advances in NLP show that language models retain a discernible level of knowledge in deontological ethics and moral norms. However, existing works often treat morality as binary, ranging from right to wrong. This simplistic view does not capture the nuances of moral judgment. Pluralist moral philosophers argue that human morality can be deconstructed into a finite number of elements, respecting individual differences in moral judgment. In line with this view, we build a pluralist moral sentence embedding space via a state-of-the-art contrastive learning approach. We systematically investigate the embedding space by studying the emergence of relationships among moral elements, both quantitatively and qualitatively. Our results show that a pluralist approach to morality can be captured in an embedding space. However, moral pluralism is challenging to deduce via self-supervision alone and requires a supervised approach with human labels.