 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Study-Level Inference from Clinical Trial Papers via RL-based Numeric Reasoning
May 28, 2025Systematic reviews in medicine play a critical role in evidence-based decision-making by aggregating findings from multiple studies. A central bottleneck in automating this process is extracting numeric evidence and determining study-level conclusions for specific outcomes and comparisons. Prior work has framed this problem as a textual inference task by retrieving relevant content fragments and inferring conclusions from them. However, such approaches often rely on shallow textual cues and fail to capture the underlying numeric reasoning behind expert assessments. In this work, we conceptualise the problem as one of quantitative reasoning. Rather than inferring conclusions from surface text, we extract structured numerical evidence (e.g., event counts or standard deviations) and apply domain knowledge informed logic to derive outcome-specific conclusions. We develop a numeric reasoning system composed of a numeric data extraction model and an effect estimate component, enabling more accurate and interpretable inference aligned with the domain expert principles. We train the numeric data extraction model using different strategies, including supervised fine-tuning (SFT) and reinforcement learning (RL) with a new value reward model. When evaluated on the CochraneForest benchmark, our best-performing approach -- using RL to train a small-scale number extraction model -- yields up to a 21% absolute improvement in F1 score over retrieval-based systems and outperforms general-purpose LLMs of over 400B parameters by up to 9%. Our results demonstrate the promise of reasoning-driven approaches for automating systematic evidence synthesis.
News is More than a Collection of Facts: Moral Frame Preserving News Summarization
Apr 01, 2025News articles are more than collections of facts; they reflect journalists' framing, shaping how events are presented to the audience. One key aspect of framing is the choice to write in (or quote verbatim) morally charged language as opposed to using neutral terms. This moral framing carries implicit judgments that automated news summarizers should recognize and preserve to maintain the original intent of the writer. In this work, we perform the first study on the preservation of moral framing in AI-generated news summaries. We propose an approach that leverages the intuition that journalists intentionally use or report specific moral-laden words, which should be retained in summaries. Through automated, crowd-sourced, and expert evaluations, we demonstrate that our approach enhances the preservation of moral framing while maintaining overall summary quality.
Reproducing the Metric-Based Evaluation of a Set of Controllable Text Generation Techniques
May 13, 2024



Rerunning a metric-based evaluation should be more straightforward, and results should be closer, than in a human-based evaluation, especially where code and model checkpoints are made available by the original authors. As this report of our efforts to rerun a metric-based evaluation of a set of single-attribute and multiple-attribute controllable text generation (CTG) techniques shows however, such reruns of evaluations do not always produce results that are the same as the original results, and can reveal errors in the reporting of the original work.
High-quality Data-to-Text Generation for Severely Under-Resourced Languages with Out-of-the-box Large Language Models
Feb 19, 2024



The performance of NLP methods for severely under-resourced languages cannot currently hope to match the state of the art in NLP methods for well resourced languages. We explore the extent to which pretrained large language models (LLMs) can bridge this gap, via the example of data-to-text generation for Irish, Welsh, Breton and Maltese. We test LLMs on these under-resourced languages and English, in a range of scenarios. We find that LLMs easily set the state of the art for the under-resourced languages by substantial margins, as measured by both automatic and human evaluations. For all our languages, human evaluation shows on-a-par performance with humans for our best systems, but BLEU scores collapse compared to English, casting doubt on the metric's suitability for evaluating non-task-specific systems. Overall, our results demonstrate the great potential of LLMs to bridge the performance gap for under-resourced languages.
Data-to-text Generation for Severely Under-Resourced Languages with GPT-3.5: A Bit of Help Needed from Google Translate
Aug 19, 2023LLMs like GPT are great at tasks involving English which dominates in their training data. In this paper, we look at how they cope with tasks involving languages that are severely under-represented in their training data, in the context of data-to-text generation for Irish, Maltese, Welsh and Breton. During the prompt-engineering phase we tested a range of prompt types and formats on GPT-3.5 and~4 with a small sample of example input/output pairs. We then fully evaluated the two most promising prompts in two scenarios: (i) direct generation into the under-resourced language, and (ii) generation into English followed by translation into the under-resourced language. We find that few-shot prompting works better for direct generation into under-resourced languages, but that the difference disappears when pivoting via English. The few-shot + translation system variants were submitted to the WebNLG 2023 shared task where they outperformed competitor systems by substantial margins in all languages on all metrics. We conclude that good performance on under-resourced languages can be achieved out-of-the box with state-of-the-art LLMs. However, our best results (for Welsh) remain well below the lowest ranked English system at WebNLG'20.
Genetic Improvement of Routing Protocols for Delay Tolerant Networks
Mar 12, 2021
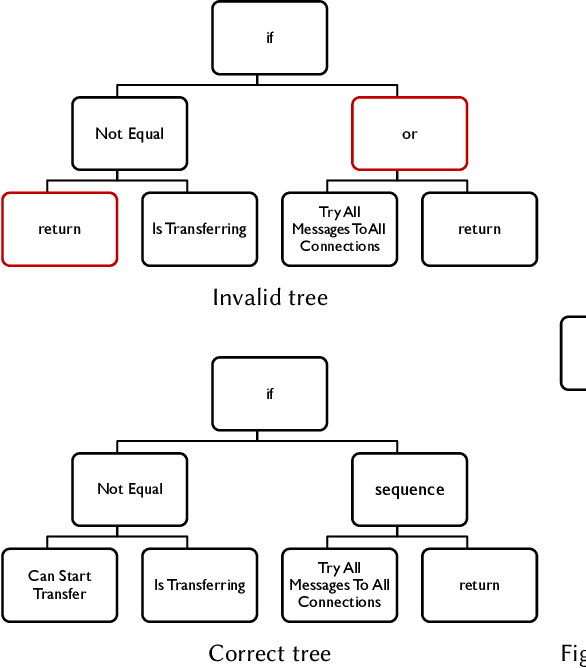


Routing plays a fundamental role in network applications, but it is especially challenging in Delay Tolerant Networks (DTNs). These are a kind of mobile ad hoc networks made of e.g. (possibly, unmanned) vehicles and humans where, despite a lack of continuous connectivity, data must be transmitted while the network conditions change due to the nodes' mobility. In these contexts, routing is NP-hard and is usually solved by heuristic "store and forward" replication-based approaches, where multiple copies of the same message are moved and stored across nodes in the hope that at least one will reach its destination. Still, the existing routing protocols produce relatively low delivery probabilities. Here, we genetically improve two routing protocols widely adopted in DTNs, namely Epidemic and PRoPHET, in the attempt to optimize their delivery probability. First, we dissect them into their fundamental components, i.e., functionalities such as checking if a node can transfer data, or sending messages to all connections. Then, we apply Genetic Improvement (GI) to manipulate these components as terminal nodes of evolving trees. We apply this methodology, in silico, to six test cases of urban networks made of hundreds of nodes, and find that GI produces consistent gains in delivery probability in four cases. We then verify if this improvement entails a worsening of other relevant network metrics, such as latency and buffer time. Finally, we compare the logics of the best evolved protocols with those of the baseline protocols, and we discuss the generalizability of the results across test cases.