 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Preferences Estimation and Disambiguation in Hybrid Participatory Systems
Feb 26, 2024Understanding citizens' values in participatory systems is crucial for citizen-centric policy-making. We envision a hybrid participatory system where participants make choices and provide motivations for those choices, and AI agents estimate their value preferences by interacting with them. We focus on situations where a conflict is detected between participants' choices and motivations, and propose methods for estimating value preferences while addressing detected inconsistencies by interacting with the participants. We operationalize the philosophical stance that "valuing is deliberatively consequential." That is, if a participant's choice is based on a deliberation of value preferences, the value preferences can be observed in the motivation the participant provides for the choice. Thus, we propose and compare value estimation methods that prioritize the values estimated from motivations over the values estimated from choices alone. Then, we introduce a disambiguation strategy that addresses the detected inconsistencies between choices and motivations by directly interacting with the participants. We evaluate the proposed methods on a dataset of a large-scale survey on energy transition. The results show that explicitly addressing inconsistencies between choices and motivations improves the estimation of an individual's value preferences. The disambiguation strategy does not show substantial improvements when compared to similar baselines--however, we discuss how the novelty of the approach can open new research avenues and propose improvements to address the current limitations.
MORAL: Aligning AI with Human Norms through Multi-Objective Reinforced Active Learning
Dec 30, 2021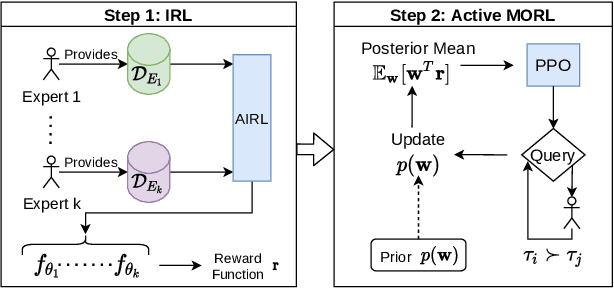


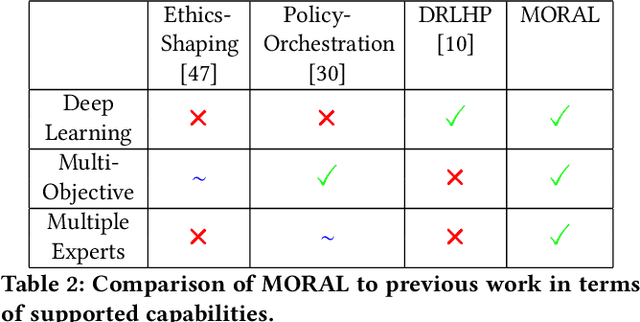
Inferring reward functions from demonstrations and pairwise preferences are auspicious approaches for aligning Reinforcement Learning (RL) agents with human intentions. However, state-of-the art methods typically focus on learning a single reward model, thus rendering it difficult to trade off different reward functions from multiple experts. We propose Multi-Objective Reinforced Active Learning (MORAL), a novel method for combining diverse demonstrations of social norms into a Pareto-optimal policy. Through maintaining a distribution over scalarization weights, our approach is able to interactively tune a deep RL agent towards a variety of preferences, while eliminating the need for computing multiple policies. We empirically demonstrate the effectiveness of MORAL in two scenarios, which model a delivery and an emergency task that require an agent to act in the presence of normative conflicts. Overall, we consider our research a step towards multi-objective RL with learned rewards, bridging the gap between current reward learning and machine ethics literature.