 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepFense: A Unified, Modular, and Extensible Framework for Robust Deepfake Audio Detection
Apr 09, 2026Speech deepfake detection is a well-established research field with different models, datasets, and training strategies. However, the lack of standardized implementations and evaluation protocols limits reproducibility, benchmarking, and comparison across studies. In this work, we present DeepFense, a comprehensive, open-source PyTorch toolkit integrating the latest architectures, loss functions, and augmentation pipelines, alongside over 100 recipes. Using DeepFense, we conducted a large-scale evaluation of more than 400 models. Our findings reveal that while carefully curated training data improves cross-domain generalization, the choice of pre-trained front-end feature extractor dominates overall performance variance. Crucially, we show severe biases in high-performing models regarding audio quality, speaker gender, and language. DeepFense is expected to facilitate real-world deployment with the necessary tools to address equitable training data selection and front-end fine-tuning.
How to Label Resynthesized Audio: The Dual Role of Neural Audio Codecs in Audio Deepfake Detection
Feb 18, 2026Since Text-to-Speech systems typically don't produce waveforms directly, recent spoof detection studies use resynthesized waveforms from vocoders and neural audio codecs to simulate an attacker. Unlike vocoders, which are specifically designed for speech synthesis, neural audio codecs were originally developed for compressing audio for storage and transmission. However, their ability to discretize speech also sparked interest in language-modeling-based speech synthesis. Owing to this dual functionality, codec resynthesized data may be labeled as either bonafide or spoof. So far, very little research has addressed this issue. In this study, we present a challenging extension of the ASVspoof 5 dataset constructed for this purpose. We examine how different labeling choices affect detection performance and provide insights into labeling strategies.
A Toolbox for Improving Evolutionary Prompt Search
Nov 07, 2025Evolutionary prompt optimization has demonstrated effectiveness in refining prompts for LLMs. However, existing approaches lack robust operators and efficient evaluation mechanisms. In this work, we propose several key improvements to evolutionary prompt optimization that can partially generalize to prompt optimization in general: 1) decomposing evolution into distinct steps to enhance the evolution and its control, 2) introducing an LLM-based judge to verify the evolutions, 3) integrating human feedback to refine the evolutionary operator, and 4) developing more efficient evaluation strategies that maintain performance while reducing computational overhead. Our approach improves both optimization quality and efficiency. We release our code, enabling prompt optimization on new tasks and facilitating further research in this area.
Use Cases for Voice Anonymization
Aug 08, 2025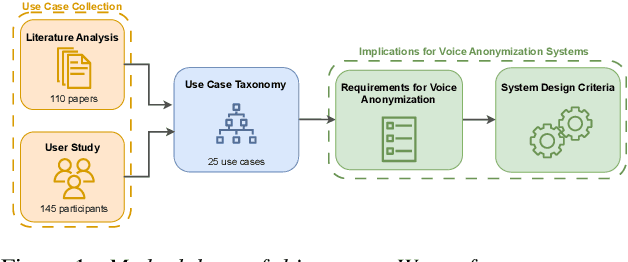



The performance of a voice anonymization system is typically measured according to its ability to hide the speaker's identity and keep the data's utility for downstream tasks. This means that the requirements the anonymization should fulfill depend on the context in which it is used and may differ greatly between use cases. However, these use cases are rarely specified in research papers. In this paper, we study the implications of use case-specific requirements on the design of voice anonymization methods. We perform an extensive literature analysis and user study to collect possible use cases and to understand the expectations of the general public towards such tools. Based on these studies, we propose the first taxonomy of use cases for voice anonymization, and derive a set of requirements and design criteria for method development and evaluation. Using this scheme, we propose to focus more on use case-oriented research and development of voice anonymization systems.
The Risks and Detection of Overestimated Privacy Protection in Voice Anonymisation
Jul 30, 2025Voice anonymisation aims to conceal the voice identity of speakers in speech recordings. Privacy protection is usually estimated from the difficulty of using a speaker verification system to re-identify the speaker post-anonymisation. Performance assessments are therefore dependent on the verification model as well as the anonymisation system. There is hence potential for privacy protection to be overestimated when the verification system is poorly trained, perhaps with mismatched data. In this paper, we demonstrate the insidious risk of overestimating anonymisation performance and show examples of exaggerated performance reported in the literature. For the worst case we identified, performance is overestimated by 74% relative. We then introduce a means to detect when performance assessment might be untrustworthy and show that it can identify all overestimation scenarios presented in the paper. Our solution is openly available as a fork of the 2024 VoicePrivacy Challenge evaluation toolkit.
First Steps Towards Voice Anonymization for Code-Switching Speech
Jul 02, 2025The goal of voice anonymization is to modify an audio such that the true identity of its speaker is hidden. Research on this task is typically limited to the same English read speech datasets, thus the efficacy of current methods for other types of speech data remains unknown. In this paper, we present the first investigation of voice anonymization for the multilingual phenomenon of code-switching speech. We prepare two corpora for this task and propose adaptations to a multilingual anonymization model to make it applicable for code-switching speech. By testing the anonymization performance of this and two language-independent methods on the datasets, we find that only the multilingual system performs well in terms of privacy and utility preservation. Furthermore, we observe challenges in performing utility evaluations on this data because of its spontaneous character and the limited code-switching support by the multilingual speech recognition model.
The Impact of Code-switched Synthetic Data Quality is Task Dependent: Insights from MT and ASR
Mar 30, 2025

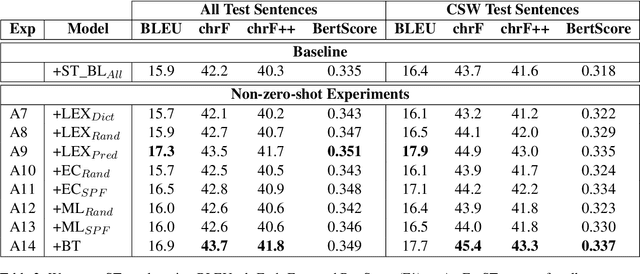

Code-switching, the act of alternating between languages, emerged as a prevalent global phenomenon that needs to be addressed for building user-friendly language technologies. A main bottleneck in this pursuit is data scarcity, motivating research in the direction of code-switched data augmentation. However, current literature lacks comprehensive studies that enable us to understand the relation between the quality of synthetic data and improvements on NLP tasks. We extend previous research conducted in this direction on machine translation (MT) with results on automatic speech recognition (ASR) and cascaded speech translation (ST) to test generalizability of findings. Our experiments involve a wide range of augmentation techniques, covering lexical replacements, linguistic theories, and back-translation. Based on the results of MT, ASR, and ST, we draw conclusions and insights regarding the efficacy of various augmentation techniques and the impact of quality on performance.
Discrete Subgraph Sampling for Interpretable Graph based Visual Question Answering
Dec 11, 2024Explainable artificial intelligence (XAI) aims to make machine learning models more transparent. While many approaches focus on generating explanations post-hoc, interpretable approaches, which generate the explanations intrinsically alongside the predictions, are relatively rare. In this work, we integrate different discrete subset sampling methods into a graph-based visual question answering system to compare their effectiveness in generating interpretable explanatory subgraphs intrinsically. We evaluate the methods on the GQA dataset and show that the integrated methods effectively mitigate the performance trade-off between interpretability and answer accuracy, while also achieving strong co-occurrences between answer and question tokens. Furthermore, we conduct a human evaluation to assess the interpretability of the generated subgraphs using a comparative setting with the extended Bradley-Terry model, showing that the answer and question token co-occurrence metrics strongly correlate with human preferences. Our source code is publicly available.
A Zero-Shot approach to the Conversational Tree Search Task
Oct 08, 2024



In sensitive domains, such as legal or medial domains, the correctness of information given to users is critical. To address this, the recently introduced task Conversational Tree Search (CTS) provides a graph-based framework for controllable task-oriented dialog in sensitive domains. However, a big drawback of state-of-the-art CTS agents is their long training time, which is especially problematic as a new agent must be trained every time the associated domain graph is updated. The goal of this paper is to eliminate the need for training CTS agents altogether. To achieve this, we implement a novel LLM-based method for zero-shot, controllable CTS agents. We show that these agents significantly outperform state-of-the-art CTS agents (p<0.0001; Barnard Exact test) in simulation. This generalizes to all available CTS domains. Finally, we perform user evaluation to test the agent performance in the wild, showing that our policy significantly (p<0.05; Barnard Exact) improves task-success compared to the state-of-the-art Reinforcement Learning-based CTS agent.
High-Resolution Speech Restoration with Latent Diffusion Model
Sep 17, 2024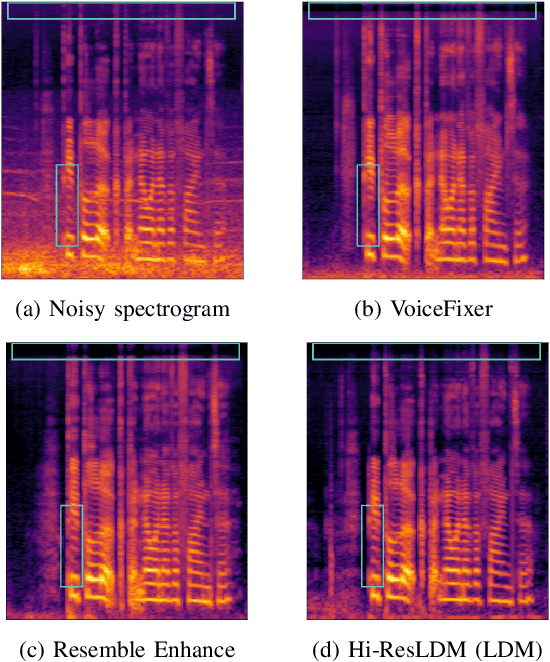
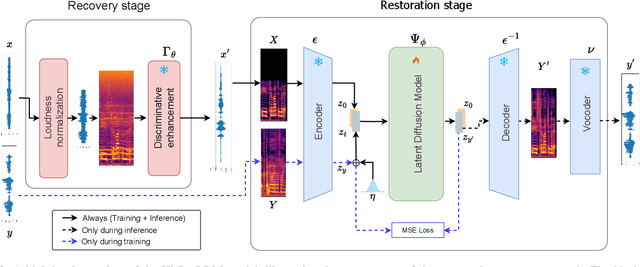
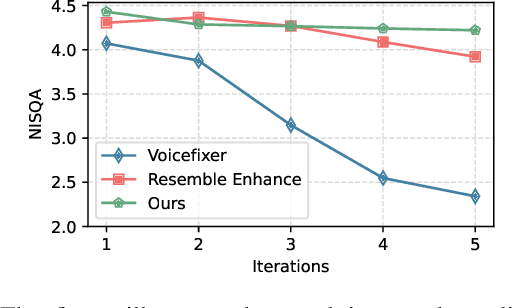
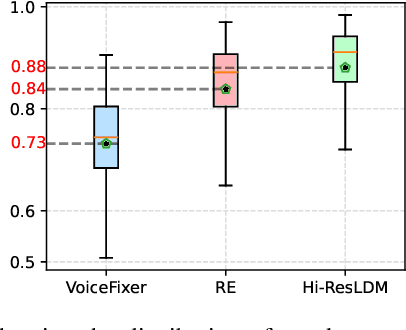
Traditional speech enhancement methods often oversimplify the task of restoration by focusing on a single type of distortion. Generative models that handle multiple distortions frequently struggle with phone reconstruction and high-frequency harmonics, leading to breathing and gasping artifacts that reduce the intelligibility of reconstructed speech. These models are also computationally demanding, and many solutions are restricted to producing outputs in the wide-band frequency range, which limits their suitability for professional applications. To address these challenges, we propose Hi-ResLDM, a novel generative model based on latent diffusion designed to remove multiple distortions and restore speech recordings to studio quality, sampled at 48kHz. We benchmark Hi-ResLDM against state-of-the-art methods that leverage GAN and Conditional Flow Matching (CFM) components, demonstrating superior performance in regenerating high-frequency-band details. Hi-ResLDM not only excels in non-instrusive metrics but is also consistently preferred in human evaluation and performs competitively on intrusive evaluations, making it ideal for high-resolution speech restoration.