 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Code-switched Synthetic Data Quality is Task Dependent: Insights from MT and ASR
Paper and Code
Mar 30, 2025

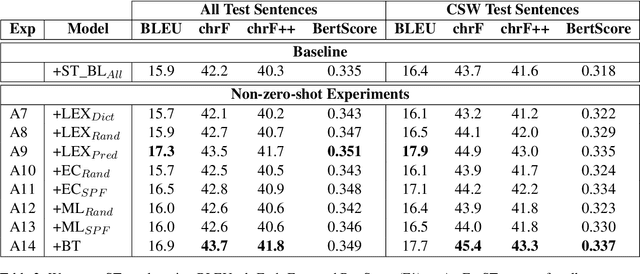

Code-switching, the act of alternating between languages, emerged as a prevalent global phenomenon that needs to be addressed for building user-friendly language technologies. A main bottleneck in this pursuit is data scarcity, motivating research in the direction of code-switched data augmentation. However, current literature lacks comprehensive studies that enable us to understand the relation between the quality of synthetic data and improvements on NLP tasks. We extend previous research conducted in this direction on machine translation (MT) with results on automatic speech recognition (ASR) and cascaded speech translation (ST) to test generalizability of findings. Our experiments involve a wide range of augmentation techniques, covering lexical replacements, linguistic theories, and back-translation. Based on the results of MT, ASR, and ST, we draw conclusions and insights regarding the efficacy of various augmentation techniques and the impact of quality on performance.