 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabiGEE: A Hierarchical Taxonomy for Arabic Grammatical Error Explanation
Jun 09, 2026We introduce ArabiGEE, the first comprehensive Arabic grammatical error explanation (GEE) taxonomy grounded in explicit error types. Unlike existing GEE approaches that treat explanation generation as free-form text, ArabiGEE organizes grammatical explanations through a hierarchical structure spanning orthographic, morphological, syntactic, and lexical dimensions. The taxonomy consists of 27 error types, 140 correction types, and 324 associated explanations. We apply ArabiGEE to manually annotate portions of existing Arabic grammatical error correction corpora and demonstrate how structured grammatical explanations can support automatic evaluation of LLMs on Arabic GEE. Our code and data are publicly available.
Arabic Sentence Segmentation Across Genres and Punctuation Conditions
Jun 06, 2026Sentence segmentation in Arabic is challenging due to ambiguous and inconsistent punctuation, with many texts lacking reliable sentence boundary markers. Existing approaches rely heavily on punctuation cues and are typically evaluated on well-formed text, limiting their robustness in realistic Arabic settings. To address this, we introduce AraSEG, a genre-diverse sentence segmentation corpus spanning eight genres and a wide range of punctuation and document structure conditions. Using AraSEG, we evaluate LLMs, lightweight encoder models, and dependency parser-based models under increasingly challenging segmentation settings. Our experiments show that lightweight encoders, and even dependency parser-based models, outperform LLMs in the most challenging settings. We further investigate the effects of training data size and genre diversity, finding that performance eventually saturates and cross-genre generalization remains challenging. We also demonstrate that accurate sentence segmentation substantially improves downstream dependency parsing. We make our code, data, and models publicly available.
Arabic Morphosyntactic Tagging and Dependency Parsing with Large Language Models
Mar 17, 2026Large language models (LLMs) perform strongly on many NLP tasks, but their ability to produce explicit linguistic structure remains unclear. We evaluate instruction-tuned LLMs on two structured prediction tasks for Standard Arabic: morphosyntactic tagging and labeled dependency parsing. Arabic provides a challenging testbed due to its rich morphology and orthographic ambiguity, which create strong morphology-syntax interactions. We compare zero-shot prompting with retrieval-based in-context learning (ICL) using examples from Arabic treebanks. Results show that prompt design and demonstration selection strongly affect performance: proprietary models approach supervised baselines for feature-level tagging and become competitive with specialized dependency parsers. In raw-text settings, tokenization remains challenging, though retrieval-based ICL improves both parsing and tokenization. Our analysis highlights which aspects of Arabic morphosyntax and syntax LLMs capture reliably and which remain difficult.
Cross-Lingual Empirical Evaluation of Large Language Models for Arabic Medical Tasks
Feb 05, 2026In recent years, Large Language Models (LLMs) have become widely used in medical applications, such as clinical decision support, medical education, and medical question answering. Yet, these models are often English-centric, limiting their robustness and reliability for linguistically diverse communities. Recent work has highlighted discrepancies in performance in low-resource languages for various medical tasks, but the underlying causes remain poorly understood. In this study, we conduct a cross-lingual empirical analysis of LLM performance on Arabic and English medical question and answering. Our findings reveal a persistent language-driven performance gap that intensifies with increasing task complexity. Tokenization analysis exposes structural fragmentation in Arabic medical text, while reliability analysis suggests that model-reported confidence and explanations exhibit limited correlation with correctness. Together, these findings underscore the need for language-aware design and evaluation strategies in LLMs for medical tasks.
MedAraBench: Large-Scale Arabic Medical Question Answering Dataset and Benchmark
Feb 02, 2026Arabic remains one of the most underrepresented languages in natural language processing research, particularly in medical applications, due to the limited availability of open-source data and benchmarks. The lack of resources hinders efforts to evaluate and advance the multilingual capabilities of Large Language Models (LLMs). In this paper, we introduce MedAraBench, a large-scale dataset consisting of Arabic multiple-choice question-answer pairs across various medical specialties. We constructed the dataset by manually digitizing a large repository of academic materials created by medical professionals in the Arabic-speaking region. We then conducted extensive preprocessing and split the dataset into training and test sets to support future research efforts in the area. To assess the quality of the data, we adopted two frameworks, namely expert human evaluation and LLM-as-a-judge. Our dataset is diverse and of high quality, spanning 19 specialties and five difficulty levels. For benchmarking purposes, we assessed the performance of eight state-of-the-art open-source and proprietary models, such as GPT-5, Gemini 2.0 Flash, and Claude 4-Sonnet. Our findings highlight the need for further domain-specific enhancements. We release the dataset and evaluation scripts to broaden the diversity of medical data benchmarks, expand the scope of evaluation suites for LLMs, and enhance the multilingual capabilities of models for deployment in clinical settings.
DialectalArabicMMLU: Benchmarking Dialectal Capabilities in Arabic and Multilingual Language Models
Oct 31, 2025We present DialectalArabicMMLU, a new benchmark for evaluating the performance of large language models (LLMs) across Arabic dialects. While recently developed Arabic and multilingual benchmarks have advanced LLM evaluation for Modern Standard Arabic (MSA), dialectal varieties remain underrepresented despite their prevalence in everyday communication. DialectalArabicMMLU extends the MMLU-Redux framework through manual translation and adaptation of 3K multiple-choice question-answer pairs into five major dialects (Syrian, Egyptian, Emirati, Saudi, and Moroccan), yielding a total of 15K QA pairs across 32 academic and professional domains (22K QA pairs when also including English and MSA). The benchmark enables systematic assessment of LLM reasoning and comprehension beyond MSA, supporting both task-based and linguistic analysis. We evaluate 19 open-weight Arabic and multilingual LLMs (1B-13B parameters) and report substantial performance variation across dialects, revealing persistent gaps in dialectal generalization. DialectalArabicMMLU provides the first unified, human-curated resource for measuring dialectal understanding in Arabic, thus promoting more inclusive evaluation and future model development.
Data Augmentation for Maltese NLP using Transliterated and Machine Translated Arabic Data
Sep 16, 2025Maltese is a unique Semitic language that has evolved under extensive influence from Romance and Germanic languages, particularly Italian and English. Despite its Semitic roots, its orthography is based on the Latin script, creating a gap between it and its closest linguistic relatives in Arabic. In this paper, we explore whether Arabic-language resources can support Maltese natural language processing (NLP) through cross-lingual augmentation techniques. We investigate multiple strategies for aligning Arabic textual data with Maltese, including various transliteration schemes and machine translation (MT) approaches. As part of this, we also introduce novel transliteration systems that better represent Maltese orthography. We evaluate the impact of these augmentations on monolingual and mutlilingual models and demonstrate that Arabic-based augmentation can significantly benefit Maltese NLP tasks.
AraHealthQA 2025: The First Shared Task on Arabic Health Question Answering
Aug 28, 2025We introduce {AraHealthQA 2025}, the {Comprehensive Arabic Health Question Answering Shared Task}, held in conjunction with {ArabicNLP 2025} (co-located with EMNLP 2025). This shared task addresses the paucity of high-quality Arabic medical QA resources by offering two complementary tracks: {MentalQA}, focusing on Arabic mental health Q\&A (e.g., anxiety, depression, stigma reduction), and {MedArabiQ}, covering broader medical domains such as internal medicine, pediatrics, and clinical decision making. Each track comprises multiple subtasks, evaluation datasets, and standardized metrics, facilitating fair benchmarking. The task was structured to promote modeling under realistic, multilingual, and culturally nuanced healthcare contexts. We outline the dataset creation, task design and evaluation framework, participation statistics, baseline systems, and summarize the overall outcomes. We conclude with reflections on the performance trends observed and prospects for future iterations in Arabic health QA.
The Arabic Generality Score: Another Dimension of Modeling Arabic Dialectness
Aug 24, 2025Arabic dialects form a diverse continuum, yet NLP models often treat them as discrete categories. Recent work addresses this issue by modeling dialectness as a continuous variable, notably through the Arabic Level of Dialectness (ALDi). However, ALDi reduces complex variation to a single dimension. We propose a complementary measure: the Arabic Generality Score (AGS), which quantifies how widely a word is used across dialects. We introduce a pipeline that combines word alignment, etymology-aware edit distance, and smoothing to annotate a parallel corpus with word-level AGS. A regression model is then trained to predict AGS in context. Our approach outperforms strong baselines, including state-of-the-art dialect ID systems, on a multi-dialect benchmark. AGS offers a scalable, linguistically grounded way to model lexical generality, enriching representations of Arabic dialectness.
BALSAM: A Platform for Benchmarking Arabic Large Language Models
Jul 30, 2025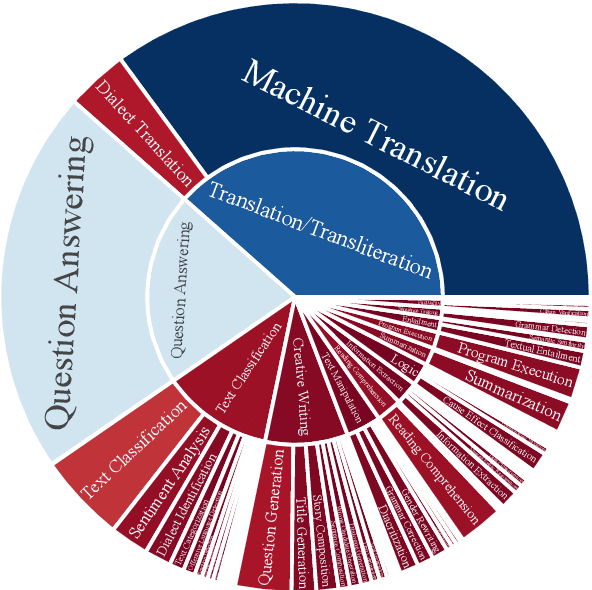



The impressive advancement of Large Language Models (LLMs) in English has not been matched across all languages. In particular, LLM performance in Arabic lags behind, due to data scarcity, linguistic diversity of Arabic and its dialects, morphological complexity, etc. Progress is further hindered by the quality of Arabic benchmarks, which typically rely on static, publicly available data, lack comprehensive task coverage, or do not provide dedicated platforms with blind test sets. This makes it challenging to measure actual progress and to mitigate data contamination. Here, we aim to bridge these gaps. In particular, we introduce BALSAM, a comprehensive, community-driven benchmark aimed at advancing Arabic LLM development and evaluation. It includes 78 NLP tasks from 14 broad categories, with 52K examples divided into 37K test and 15K development, and a centralized, transparent platform for blind evaluation. We envision BALSAM as a unifying platform that sets standards and promotes collaborative research to advance Arabic LLM capabilities.