 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Security Beyond Core Domains: Resume Screening as a Case Study of Adversarial Vulnerabilities in Specialized LLM Applications
Dec 23, 2025



Large Language Models (LLMs) excel at text comprehension and generation, making them ideal for automated tasks like code review and content moderation. However, our research identifies a vulnerability: LLMs can be manipulated by "adversarial instructions" hidden in input data, such as resumes or code, causing them to deviate from their intended task. Notably, while defenses may exist for mature domains such as code review, they are often absent in other common applications such as resume screening and peer review. This paper introduces a benchmark to assess this vulnerability in resume screening, revealing attack success rates exceeding 80% for certain attack types. We evaluate two defense mechanisms: prompt-based defenses achieve 10.1% attack reduction with 12.5% false rejection increase, while our proposed FIDS (Foreign Instruction Detection through Separation) using LoRA adaptation achieves 15.4% attack reduction with 10.4% false rejection increase. The combined approach provides 26.3% attack reduction, demonstrating that training-time defenses outperform inference-time mitigations in both security and utility preservation.
Towards Ancient Plant Seed Classification: A Benchmark Dataset and Baseline Model
Dec 20, 2025Understanding the dietary preferences of ancient societies and their evolution across periods and regions is crucial for revealing human-environment interactions. Seeds, as important archaeological artifacts, represent a fundamental subject of archaeobotanical research. However, traditional studies rely heavily on expert knowledge, which is often time-consuming and inefficient. Intelligent analysis methods have made progress in various fields of archaeology, but there remains a research gap in data and methods in archaeobotany, especially in the classification task of ancient plant seeds. To address this, we construct the first Ancient Plant Seed Image Classification (APS) dataset. It contains 8,340 images from 17 genus- or species-level seed categories excavated from 18 archaeological sites across China. In addition, we design a framework specifically for the ancient plant seed classification task (APSNet), which introduces the scale feature (size) of seeds based on learning fine-grained information to guide the network in discovering key "evidence" for sufficient classification. Specifically, we design a Size Perception and Embedding (SPE) module in the encoder part to explicitly extract size information for the purpose of complementing fine-grained information. We propose an Asynchronous Decoupled Decoding (ADD) architecture based on traditional progressive learning to decode features from both channel and spatial perspectives, enabling efficient learning of discriminative features. In both quantitative and qualitative analyses, our approach surpasses existing state-of-the-art image classification methods, achieving an accuracy of 90.5%. This demonstrates that our work provides an effective tool for large-scale, systematic archaeological research.
A Two-Stage Data Selection Framework for Data-Efficient Model Training on Edge Devices
May 22, 2025The demand for machine learning (ML) model training on edge devices is escalating due to data privacy and personalized service needs. However, we observe that current on-device model training is hampered by the under-utilization of on-device data, due to low training throughput, limited storage and diverse data importance. To improve data resource utilization, we propose a two-stage data selection framework {\sf Titan} to select the most important data batch from streaming data for model training with guaranteed efficiency and effectiveness. Specifically, in the first stage, {\sf Titan} filters out a candidate dataset with potentially high importance in a coarse-grained manner.In the second stage of fine-grained selection, we propose a theoretically optimal data selection strategy to identify the data batch with the highest model performance improvement to current training round. To further enhance time-and-resource efficiency, {\sf Titan} leverages a pipeline to co-execute data selection and model training, and avoids resource conflicts by exploiting idle computing resources. We evaluate {\sf Titan} on real-world edge devices and three representative edge computing tasks with diverse models and data modalities. Empirical results demonstrate that {\sf Titan} achieves up to $43\%$ reduction in training time and $6.2\%$ increase in final accuracy with minor system overhead, such as data processing delay, memory footprint and energy consumption.
Deliberation on Priors: Trustworthy Reasoning of Large Language Models on Knowledge Graphs
May 21, 2025Knowledge graph-based retrieval-augmented generation seeks to mitigate hallucinations in Large Language Models (LLMs) caused by insufficient or outdated knowledge. However, existing methods often fail to fully exploit the prior knowledge embedded in knowledge graphs (KGs), particularly their structural information and explicit or implicit constraints. The former can enhance the faithfulness of LLMs' reasoning, while the latter can improve the reliability of response generation. Motivated by these, we propose a trustworthy reasoning framework, termed Deliberation over Priors (DP), which sufficiently utilizes the priors contained in KGs. Specifically, DP adopts a progressive knowledge distillation strategy that integrates structural priors into LLMs through a combination of supervised fine-tuning and Kahneman-Tversky optimization, thereby improving the faithfulness of relation path generation. Furthermore, our framework employs a reasoning-introspection strategy, which guides LLMs to perform refined reasoning verification based on extracted constraint priors, ensuring the reliability of response generation. Extensive experiments on three benchmark datasets demonstrate that DP achieves new state-of-the-art performance, especially a Hit@1 improvement of 13% on the ComplexWebQuestions dataset, and generates highly trustworthy responses. We also conduct various analyses to verify its flexibility and practicality. The code is available at https://github.com/reml-group/Deliberation-on-Priors.
Analysis of Emotion in Rumour Threads on Social Media
Feb 23, 2025Rumours in online social media pose significant risks to modern society, motivating the need for better understanding of how they develop. We focus specifically on the interface between emotion and rumours in threaded discourses, building on the surprisingly sparse literature on the topic which has largely focused on emotions within the original rumour posts themselves, and largely overlooked the comparative differences between rumours and non-rumours. In this work, we provide a comprehensive analytical emotion framework, contrasting rumour and non-rumour cases using existing NLP datasets to further understand the emotion dynamics within rumours. Our framework reveals several findings: rumours exhibit more negative sentiment and emotions, including anger, fear and pessimism, while non-rumours evoke more positive emotions; emotions are contagious in online interactions, with rumours facilitate negative emotions and non-rumours foster positive emotions; and based on causal analysis, surprise acts as a bridge between rumours and other emotions, pessimism is driven by sadness and fear, optimism by joy and love.
Is Human-Like Text Liked by Humans? Multilingual Human Detection and Preference Against AI
Feb 17, 2025



Prior studies have shown that distinguishing text generated by large language models (LLMs) from human-written one is highly challenging, and often no better than random guessing. To verify the generalizability of this finding across languages and domains, we perform an extensive case study to identify the upper bound of human detection accuracy. Across 16 datasets covering 9 languages and 9 domains, 19 annotators achieved an average detection accuracy of 87.6%, thus challenging previous conclusions. We find that major gaps between human and machine text lie in concreteness, cultural nuances, and diversity. Prompting by explicitly explaining the distinctions in the prompts can partially bridge the gaps in over 50% of the cases. However, we also find that humans do not always prefer human-written text, particularly when they cannot clearly identify its source.
GenAI Content Detection Task 1: English and Multilingual Machine-Generated Text Detection: AI vs. Human
Jan 19, 2025We present the GenAI Content Detection Task~1 -- a shared task on binary machine generated text detection, conducted as a part of the GenAI workshop at COLING 2025. The task consists of two subtasks: Monolingual (English) and Multilingual. The shared task attracted many participants: 36 teams made official submissions to the Monolingual subtask during the test phase and 26 teams -- to the Multilingual. We provide a comprehensive overview of the data, a summary of the results -- including system rankings and performance scores -- detailed descriptions of the participating systems, and an in-depth analysis of submissions. https://github.com/mbzuai-nlp/COLING-2025-Workshop-on-MGT-Detection-Task1
Large Language Models as Code Executors: An Exploratory Study
Oct 10, 2024



The capabilities of Large Language Models (LLMs) have significantly evolved, extending from natural language processing to complex tasks like code understanding and generation. We expand the scope of LLMs' capabilities to a broader context, using LLMs to execute code snippets to obtain the output. This paper pioneers the exploration of LLMs as code executors, where code snippets are directly fed to the models for execution, and outputs are returned. We are the first to comprehensively examine this feasibility across various LLMs, including OpenAI's o1, GPT-4o, GPT-3.5, DeepSeek, and Qwen-Coder. Notably, the o1 model achieved over 90% accuracy in code execution, while others demonstrated lower accuracy levels. Furthermore, we introduce an Iterative Instruction Prompting (IIP) technique that processes code snippets line by line, enhancing the accuracy of weaker models by an average of 7.22% (with the highest improvement of 18.96%) and an absolute average improvement of 3.86% against CoT prompting (with the highest improvement of 19.46%). Our study not only highlights the transformative potential of LLMs in coding but also lays the groundwork for future advancements in automated programming and the completion of complex tasks.
Loki: An Open-Source Tool for Fact Verification
Oct 02, 2024



We introduce Loki, an open-source tool designed to address the growing problem of misinformation. Loki adopts a human-centered approach, striking a balance between the quality of fact-checking and the cost of human involvement. It decomposes the fact-checking task into a five-step pipeline: breaking down long texts into individual claims, assessing their check-worthiness, generating queries, retrieving evidence, and verifying the claims. Instead of fully automating the claim verification process, Loki provides essential information at each step to assist human judgment, especially for general users such as journalists and content moderators. Moreover, it has been optimized for latency, robustness, and cost efficiency at a commercially usable level. Loki is released under an MIT license and is available on GitHub. We also provide a video presenting the system and its capabilities.
Unconditional Truthfulness: Learning Conditional Dependency for Uncertainty Quantification of Large Language Models
Aug 20, 2024


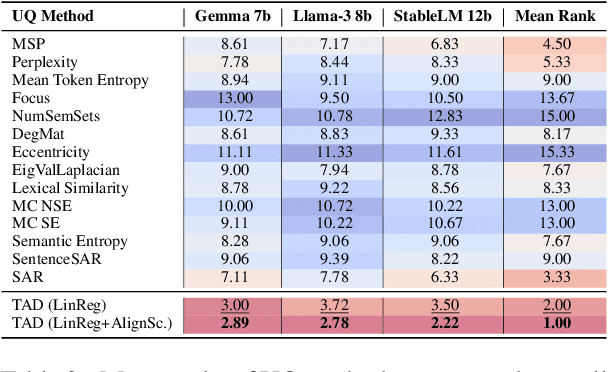
Uncertainty quantification (UQ) is a perspective approach to detecting Large Language Model (LLM) hallucinations and low quality output. In this work, we address one of the challenges of UQ in generation tasks that arises from the conditional dependency between the generation steps of an LLM. We propose to learn this dependency from data. We train a regression model, which target variable is the gap between the conditional and the unconditional generation confidence. During LLM inference, we use this learned conditional dependency model to modulate the uncertainty of the current generation step based on the uncertainty of the previous step. Our experimental evaluation on nine datasets and three LLMs shows that the proposed method is highly effective for uncertainty quantification, achieving substantial improvements over rivaling approaches.