 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGridRoute: A Benchmark for LLM-Based Route Planning with Cardinal Movement in Grid Environments
May 30, 2025



Recent advancements in Large Language Models (LLMs) have demonstrated their potential in planning and reasoning tasks, offering a flexible alternative to classical pathfinding algorithms. However, most existing studies focus on LLMs' independent reasoning capabilities and overlook the potential synergy between LLMs and traditional algorithms. To fill this gap, we propose a comprehensive evaluation benchmark GridRoute to assess how LLMs can take advantage of traditional algorithms. We also propose a novel hybrid prompting technique called Algorithm of Thought (AoT), which introduces traditional algorithms' guidance into prompting. Our benchmark evaluates six LLMs ranging from 7B to 72B parameters across various map sizes, assessing their performance in correctness, optimality, and efficiency in grid environments with varying sizes. Our results show that AoT significantly boosts performance across all model sizes, particularly in larger or more complex environments, suggesting a promising approach to addressing path planning challenges. Our code is open-sourced at https://github.com/LinChance/GridRoute.
LoKI: Low-damage Knowledge Implanting of Large Language Models
May 28, 2025Fine-tuning adapts pretrained models for specific tasks but poses the risk of catastrophic forgetting (CF), where critical knowledge from pre-training is overwritten. Current Parameter-Efficient Fine-Tuning (PEFT) methods for Large Language Models (LLMs), while efficient, often sacrifice general capabilities. To address the issue of CF in a general-purpose PEFT framework, we propose \textbf{Lo}w-damage \textbf{K}nowledge \textbf{I}mplanting (\textbf{LoKI}), a PEFT technique that is based on a mechanistic understanding of how knowledge is stored in transformer architectures. In two real-world scenarios, LoKI demonstrates task-specific performance that is comparable to or even surpasses that of full fine-tuning and LoRA-based methods across various model types, while significantly better preserving general capabilities. Our work connects mechanistic insights into LLM knowledge storage with practical fine-tuning objectives, achieving state-of-the-art trade-offs between task specialization and the preservation of general capabilities. Our implementation is publicly available as ready-to-use code\footnote{https://github.com/Nexround/LoKI}.
SoS1: O1 and R1-Like Reasoning LLMs are Sum-of-Square Solvers
Feb 27, 2025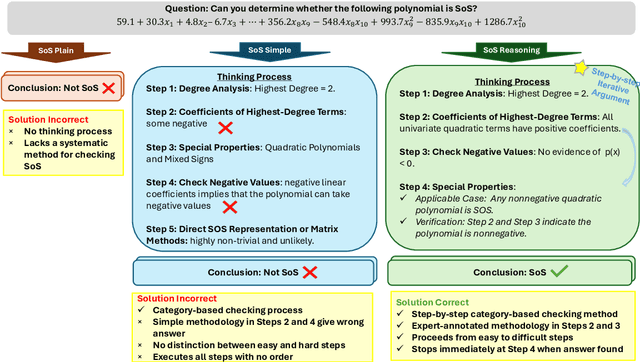
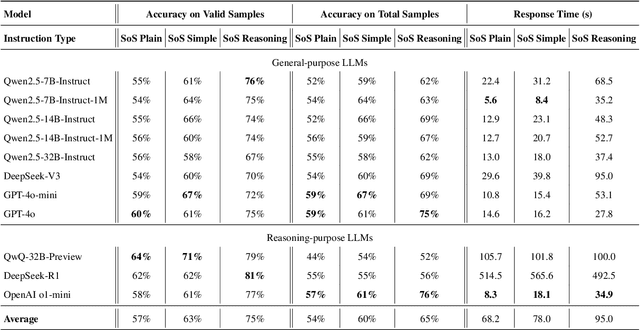
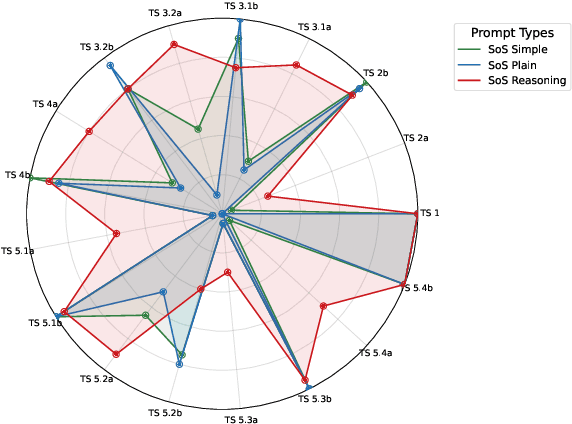
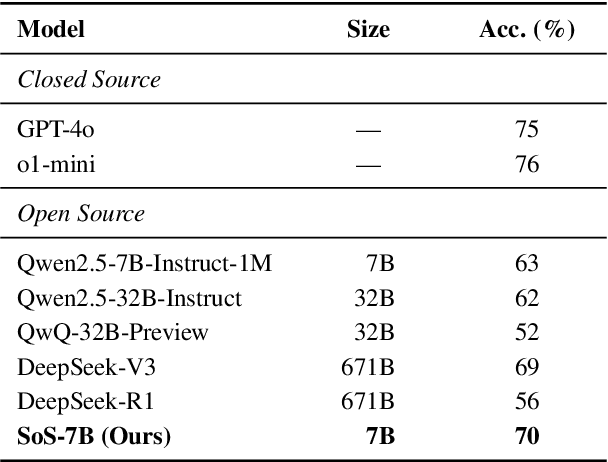
Large Language Models (LLMs) have achieved human-level proficiency across diverse tasks, but their ability to perform rigorous mathematical problem solving remains an open challenge. In this work, we investigate a fundamental yet computationally intractable problem: determining whether a given multivariate polynomial is nonnegative. This problem, closely related to Hilbert's Seventeenth Problem, plays a crucial role in global polynomial optimization and has applications in various fields. First, we introduce SoS-1K, a meticulously curated dataset of approximately 1,000 polynomials, along with expert-designed reasoning instructions based on five progressively challenging criteria. Evaluating multiple state-of-the-art LLMs, we find that without structured guidance, all models perform only slightly above the random guess baseline 50%. However, high-quality reasoning instructions significantly improve accuracy, boosting performance up to 81%. Furthermore, our 7B model, SoS-7B, fine-tuned on SoS-1K for just 4 hours, outperforms the 671B DeepSeek-V3 and GPT-4o-mini in accuracy while only requiring 1.8% and 5% of the computation time needed for letters, respectively. Our findings highlight the potential of LLMs to push the boundaries of mathematical reasoning and tackle NP-hard problems.
Large Language Models as Code Executors: An Exploratory Study
Oct 10, 2024



The capabilities of Large Language Models (LLMs) have significantly evolved, extending from natural language processing to complex tasks like code understanding and generation. We expand the scope of LLMs' capabilities to a broader context, using LLMs to execute code snippets to obtain the output. This paper pioneers the exploration of LLMs as code executors, where code snippets are directly fed to the models for execution, and outputs are returned. We are the first to comprehensively examine this feasibility across various LLMs, including OpenAI's o1, GPT-4o, GPT-3.5, DeepSeek, and Qwen-Coder. Notably, the o1 model achieved over 90% accuracy in code execution, while others demonstrated lower accuracy levels. Furthermore, we introduce an Iterative Instruction Prompting (IIP) technique that processes code snippets line by line, enhancing the accuracy of weaker models by an average of 7.22% (with the highest improvement of 18.96%) and an absolute average improvement of 3.86% against CoT prompting (with the highest improvement of 19.46%). Our study not only highlights the transformative potential of LLMs in coding but also lays the groundwork for future advancements in automated programming and the completion of complex tasks.
Is a Video worth $n\times n$ Images? A Highly Efficient Approach to Transformer-based Video Question Answering
May 16, 2023



Conventional Transformer-based Video Question Answering (VideoQA) approaches generally encode frames independently through one or more image encoders followed by interaction between frames and question. However, such schema would incur significant memory use and inevitably slow down the training and inference speed. In this work, we present a highly efficient approach for VideoQA based on existing vision-language pre-trained models where we concatenate video frames to a $n\times n$ matrix and then convert it to one image. By doing so, we reduce the use of the image encoder from $n^{2}$ to $1$ while maintaining the temporal structure of the original video. Experimental results on MSRVTT and TrafficQA show that our proposed approach achieves state-of-the-art performance with nearly $4\times$ faster speed and only 30% memory use. We show that by integrating our approach into VideoQA systems we can achieve comparable, even superior, performance with a significant speed up for training and inference. We believe the proposed approach can facilitate VideoQA-related research by reducing the computational requirements for those who have limited access to budgets and resources. Our code will be made publicly available for research use.
Semantic-aware Dynamic Retrospective-Prospective Reasoning for Event-level Video Question Answering
May 14, 2023



Event-Level Video Question Answering (EVQA) requires complex reasoning across video events to obtain the visual information needed to provide optimal answers. However, despite significant progress in model performance, few studies have focused on using the explicit semantic connections between the question and visual information especially at the event level. There is need for using such semantic connections to facilitate complex reasoning across video frames. Therefore, we propose a semantic-aware dynamic retrospective-prospective reasoning approach for video-based question answering. Specifically, we explicitly use the Semantic Role Labeling (SRL) structure of the question in the dynamic reasoning process where we decide to move to the next frame based on which part of the SRL structure (agent, verb, patient, etc.) of the question is being focused on. We conduct experiments on a benchmark EVQA dataset - TrafficQA. Results show that our proposed approach achieves superior performance compared to previous state-of-the-art models. Our code will be made publicly available for research use.
Document-Level Machine Translation with Large Language Models
Apr 05, 2023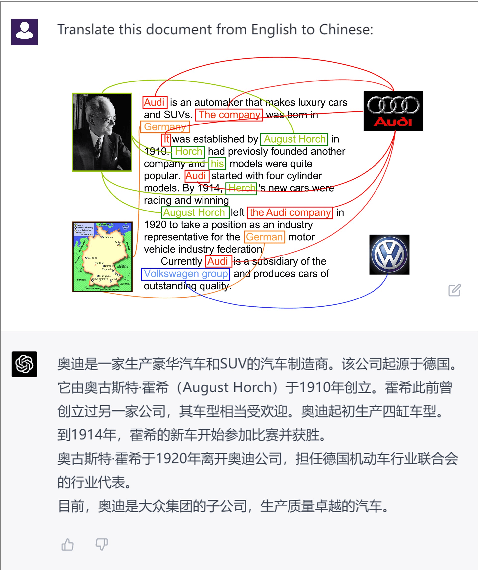

Large language models (LLMs) such as Chat-GPT can produce coherent, cohesive, relevant, and fluent answers for various natural language processing (NLP) tasks. Taking document-level machine translation (MT) as a testbed, this paper provides an in-depth evaluation of LLMs' ability on discourse modeling. The study fo-cuses on three aspects: 1) Effects of Discourse-Aware Prompts, where we investigate the impact of different prompts on document-level translation quality and discourse phenomena; 2) Comparison of Translation Models, where we compare the translation performance of Chat-GPT with commercial MT systems and advanced document-level MT methods; 3) Analysis of Discourse Modelling Abilities, where we further probe discourse knowledge encoded in LLMs and examine the impact of training techniques on discourse modeling. By evaluating a number of benchmarks, we surprisingly find that 1) leveraging their powerful long-text mod-eling capabilities, ChatGPT outperforms commercial MT systems in terms of human evaluation. 2) GPT-4 demonstrates a strong ability to explain discourse knowledge, even through it may select incorrect translation candidates in contrastive testing. 3) ChatGPT and GPT-4 have demonstrated superior performance and show potential to become a new and promising paradigm for document-level translation. This work highlights the challenges and opportunities of discourse modeling for LLMs, which we hope can inspire the future design and evaluation of LLMs.
QAScore -- An Unsupervised Unreferenced Metric for the Question Generation Evaluation
Oct 09, 2022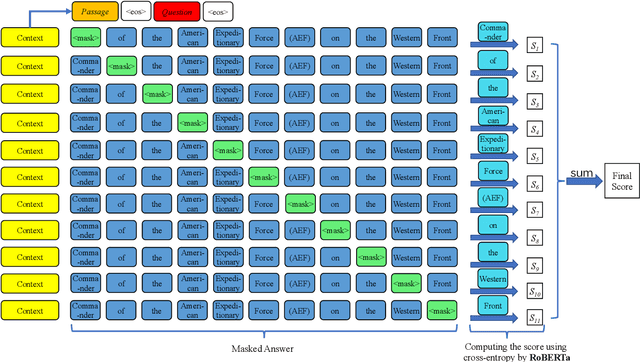
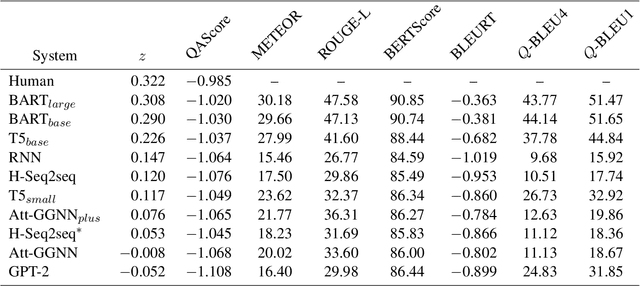
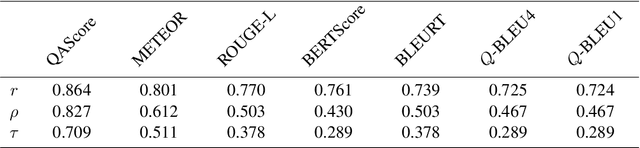

Question Generation (QG) aims to automate the task of composing questions for a passage with a set of chosen answers found within the passage. In recent years, the introduction of neural generation models has resulted in substantial improvements of automatically generated questions in terms of quality, especially compared to traditional approaches that employ manually crafted heuristics. However, the metrics commonly applied in QG evaluations have been criticized for their low agreement with human judgement. We therefore propose a new reference-free evaluation metric that has the potential to provide a better mechanism for evaluating QG systems, called QAScore. Instead of fine-tuning a language model to maximize its correlation with human judgements, QAScore evaluates a question by computing the cross entropy according to the probability that the language model can correctly generate the masked words in the answer to that question. Furthermore, we conduct a new crowd-sourcing human evaluation experiment for the QG evaluation to investigate how QAScore and other metrics can correlate with human judgements. Experiments show that QAScore obtains a stronger correlation with the results of our proposed human evaluation method compared to existing traditional word-overlap-based metrics such as BLEU and ROUGE, as well as the existing pretrained-model-based metric BERTScore.
Achieving Reliable Human Assessment of Open-Domain Dialogue Systems
Mar 11, 2022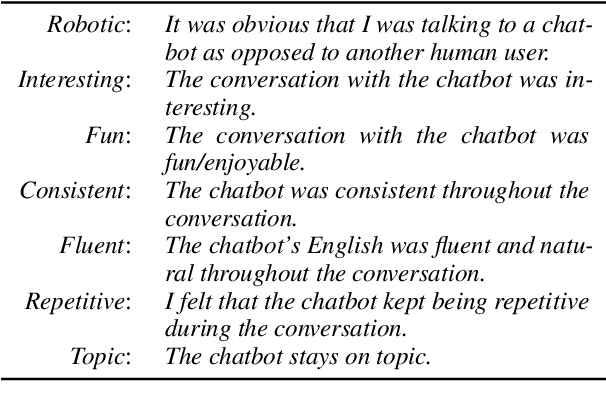

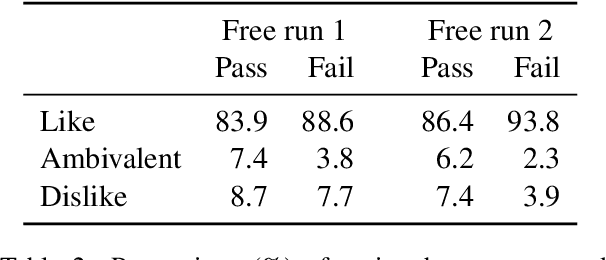
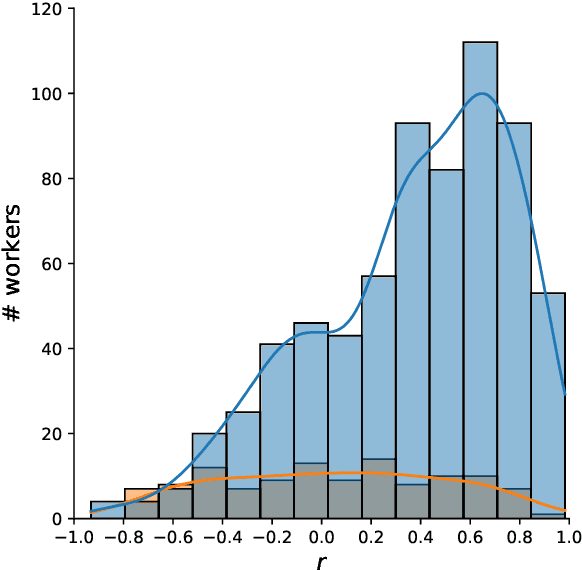
Evaluation of open-domain dialogue systems is highly challenging and development of better techniques is highlighted time and again as desperately needed. Despite substantial efforts to carry out reliable live evaluation of systems in recent competitions, annotations have been abandoned and reported as too unreliable to yield sensible results. This is a serious problem since automatic metrics are not known to provide a good indication of what may or may not be a high-quality conversation. Answering the distress call of competitions that have emphasized the urgent need for better evaluation techniques in dialogue, we present the successful development of human evaluation that is highly reliable while still remaining feasible and low cost. Self-replication experiments reveal almost perfectly repeatable results with a correlation of $r=0.969$. Furthermore, due to the lack of appropriate methods of statistical significance testing, the likelihood of potential improvements to systems occurring due to chance is rarely taken into account in dialogue evaluation, and the evaluation we propose facilitates application of standard tests. Since we have developed a highly reliable evaluation method, new insights into system performance can be revealed. We therefore include a comparison of state-of-the-art models (i) with and without personas, to measure the contribution of personas to conversation quality, as well as (ii) prescribed versus freely chosen topics. Interestingly with respect to personas, results indicate that personas do not positively contribute to conversation quality as expected.