 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuizzard@INOVA Challenge 2025 -- Track A: Plug-and-Play Technique in Interleaved Multi-Image Model
Jun 13, 2025This paper addresses two main objectives. Firstly, we demonstrate the impressive performance of the LLaVA-NeXT-interleave on 22 datasets across three different tasks: Multi-Image Reasoning, Documents and Knowledge-Based Understanding and Interactive Multi-Modal Communication. Secondly, we add the Dense Channel Integration (DCI) connector to the LLaVA-NeXT-Interleave and compare its performance against the standard model. We find that the standard model achieves the highest overall accuracy, excelling in vision-heavy tasks like VISION, NLVR2, and Fashion200K. Meanwhile, the DCI-enhanced version shows particular strength on datasets requiring deeper semantic coherence or structured change understanding such as MIT-States_PropertyCoherence and SlideVQA. Our results highlight the potential of combining powerful foundation models with plug-and-play techniques for Interleave tasks. The code is available at https://github.com/dinhvietcuong1996/icme25-inova.
SEAR: A Multimodal Dataset for Analyzing AR-LLM-Driven Social Engineering Behaviors
May 30, 2025The SEAR Dataset is a novel multimodal resource designed to study the emerging threat of social engineering (SE) attacks orchestrated through augmented reality (AR) and multimodal large language models (LLMs). This dataset captures 180 annotated conversations across 60 participants in simulated adversarial scenarios, including meetings, classes and networking events. It comprises synchronized AR-captured visual/audio cues (e.g., facial expressions, vocal tones), environmental context, and curated social media profiles, alongside subjective metrics such as trust ratings and susceptibility assessments. Key findings reveal SEAR's alarming efficacy in eliciting compliance (e.g., 93.3% phishing link clicks, 85% call acceptance) and hijacking trust (76.7% post-interaction trust surge). The dataset supports research in detecting AR-driven SE attacks, designing defensive frameworks, and understanding multimodal adversarial manipulation. Rigorous ethical safeguards, including anonymization and IRB compliance, ensure responsible use. The SEAR dataset is available at https://github.com/INSLabCN/SEAR-Dataset.
LoKI: Low-damage Knowledge Implanting of Large Language Models
May 28, 2025Fine-tuning adapts pretrained models for specific tasks but poses the risk of catastrophic forgetting (CF), where critical knowledge from pre-training is overwritten. Current Parameter-Efficient Fine-Tuning (PEFT) methods for Large Language Models (LLMs), while efficient, often sacrifice general capabilities. To address the issue of CF in a general-purpose PEFT framework, we propose \textbf{Lo}w-damage \textbf{K}nowledge \textbf{I}mplanting (\textbf{LoKI}), a PEFT technique that is based on a mechanistic understanding of how knowledge is stored in transformer architectures. In two real-world scenarios, LoKI demonstrates task-specific performance that is comparable to or even surpasses that of full fine-tuning and LoRA-based methods across various model types, while significantly better preserving general capabilities. Our work connects mechanistic insights into LLM knowledge storage with practical fine-tuning objectives, achieving state-of-the-art trade-offs between task specialization and the preservation of general capabilities. Our implementation is publicly available as ready-to-use code\footnote{https://github.com/Nexround/LoKI}.
On the Feasibility of Using MultiModal LLMs to Execute AR Social Engineering Attacks
Apr 16, 2025Augmented Reality (AR) and Multimodal Large Language Models (LLMs) are rapidly evolving, providing unprecedented capabilities for human-computer interaction. However, their integration introduces a new attack surface for social engineering. In this paper, we systematically investigate the feasibility of orchestrating AR-driven Social Engineering attacks using Multimodal LLM for the first time, via our proposed SEAR framework, which operates through three key phases: (1) AR-based social context synthesis, which fuses Multimodal inputs (visual, auditory and environmental cues); (2) role-based Multimodal RAG (Retrieval-Augmented Generation), which dynamically retrieves and integrates contextual data while preserving character differentiation; and (3) ReInteract social engineering agents, which execute adaptive multiphase attack strategies through inference interaction loops. To verify SEAR, we conducted an IRB-approved study with 60 participants in three experimental configurations (unassisted, AR+LLM, and full SEAR pipeline) compiling a new dataset of 180 annotated conversations in simulated social scenarios. Our results show that SEAR is highly effective at eliciting high-risk behaviors (e.g., 93.3% of participants susceptible to email phishing). The framework was particularly effective in building trust, with 85% of targets willing to accept an attacker's call after an interaction. Also, we identified notable limitations such as ``occasionally artificial'' due to perceived authenticity gaps. This work provides proof-of-concept for AR-LLM driven social engineering attacks and insights for developing defensive countermeasures against next-generation augmented reality threats.
Findings of the WMT 2024 Shared Task on Discourse-Level Literary Translation
Dec 16, 2024Following last year, we have continued to host the WMT translation shared task this year, the second edition of the Discourse-Level Literary Translation. We focus on three language directions: Chinese-English, Chinese-German, and Chinese-Russian, with the latter two ones newly added. This year, we totally received 10 submissions from 5 academia and industry teams. We employ both automatic and human evaluations to measure the performance of the submitted systems. The official ranking of the systems is based on the overall human judgments. We release data, system outputs, and leaderboard at https://www2.statmt.org/wmt24/literary-translation-task.html.
Findings of the WMT 2023 Shared Task on Discourse-Level Literary Translation: A Fresh Orb in the Cosmos of LLMs
Nov 06, 2023Translating literary works has perennially stood as an elusive dream in machine translation (MT), a journey steeped in intricate challenges. To foster progress in this domain, we hold a new shared task at WMT 2023, the first edition of the Discourse-Level Literary Translation. First, we (Tencent AI Lab and China Literature Ltd.) release a copyrighted and document-level Chinese-English web novel corpus. Furthermore, we put forth an industry-endorsed criteria to guide human evaluation process. This year, we totally received 14 submissions from 7 academia and industry teams. We employ both automatic and human evaluations to measure the performance of the submitted systems. The official ranking of the systems is based on the overall human judgments. In addition, our extensive analysis reveals a series of interesting findings on literary and discourse-aware MT. We release data, system outputs, and leaderboard at http://www2.statmt.org/wmt23/literary-translation-task.html.
Dialogue-to-Video Retrieval
Mar 23, 2023Recent years have witnessed an increasing amount of dialogue/conversation on the web especially on social media. That inspires the development of dialogue-based retrieval, in which retrieving videos based on dialogue is of increasing interest for recommendation systems. Different from other video retrieval tasks, dialogue-to-video retrieval uses structured queries in the form of user-generated dialogue as the search descriptor. We present a novel dialogue-to-video retrieval system, incorporating structured conversational information. Experiments conducted on the AVSD dataset show that our proposed approach using plain-text queries improves over the previous counterpart model by 15.8% on R@1. Furthermore, our approach using dialogue as a query, improves retrieval performance by 4.2%, 6.2%, 8.6% on R@1, R@5 and R@10 and outperforms the state-of-the-art model by 0.7%, 3.6% and 6.0% on R@1, R@5 and R@10 respectively.
QAScore -- An Unsupervised Unreferenced Metric for the Question Generation Evaluation
Oct 09, 2022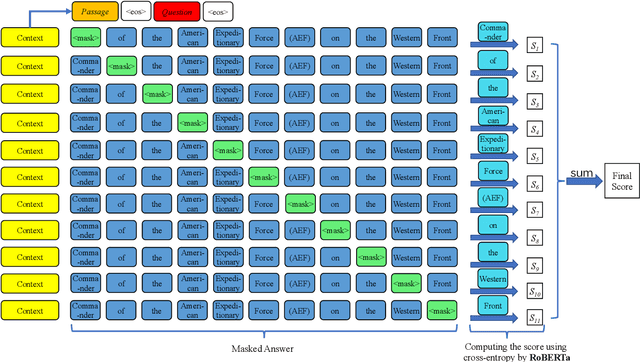
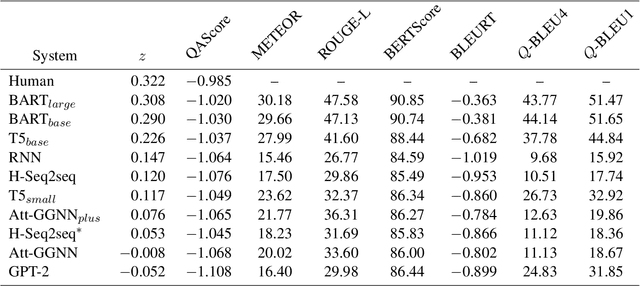
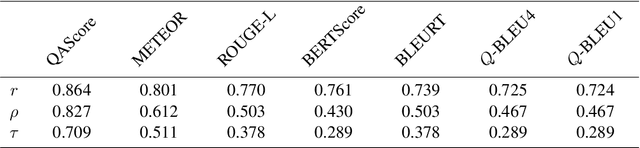

Question Generation (QG) aims to automate the task of composing questions for a passage with a set of chosen answers found within the passage. In recent years, the introduction of neural generation models has resulted in substantial improvements of automatically generated questions in terms of quality, especially compared to traditional approaches that employ manually crafted heuristics. However, the metrics commonly applied in QG evaluations have been criticized for their low agreement with human judgement. We therefore propose a new reference-free evaluation metric that has the potential to provide a better mechanism for evaluating QG systems, called QAScore. Instead of fine-tuning a language model to maximize its correlation with human judgements, QAScore evaluates a question by computing the cross entropy according to the probability that the language model can correctly generate the masked words in the answer to that question. Furthermore, we conduct a new crowd-sourcing human evaluation experiment for the QG evaluation to investigate how QAScore and other metrics can correlate with human judgements. Experiments show that QAScore obtains a stronger correlation with the results of our proposed human evaluation method compared to existing traditional word-overlap-based metrics such as BLEU and ROUGE, as well as the existing pretrained-model-based metric BERTScore.