 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue-to-Video Retrieval
Mar 23, 2023Recent years have witnessed an increasing amount of dialogue/conversation on the web especially on social media. That inspires the development of dialogue-based retrieval, in which retrieving videos based on dialogue is of increasing interest for recommendation systems. Different from other video retrieval tasks, dialogue-to-video retrieval uses structured queries in the form of user-generated dialogue as the search descriptor. We present a novel dialogue-to-video retrieval system, incorporating structured conversational information. Experiments conducted on the AVSD dataset show that our proposed approach using plain-text queries improves over the previous counterpart model by 15.8% on R@1. Furthermore, our approach using dialogue as a query, improves retrieval performance by 4.2%, 6.2%, 8.6% on R@1, R@5 and R@10 and outperforms the state-of-the-art model by 0.7%, 3.6% and 6.0% on R@1, R@5 and R@10 respectively.
HADA: A Graph-based Amalgamation Framework in Image-text Retrieval
Jan 11, 2023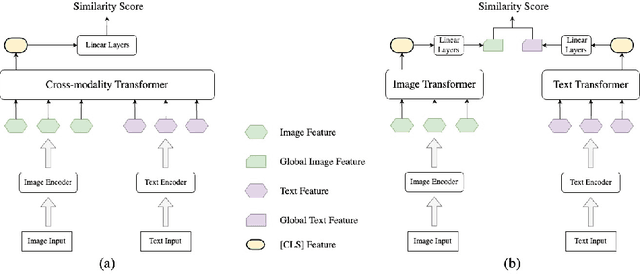
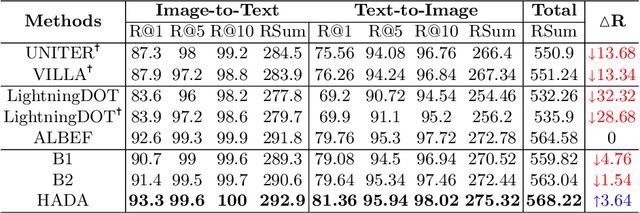
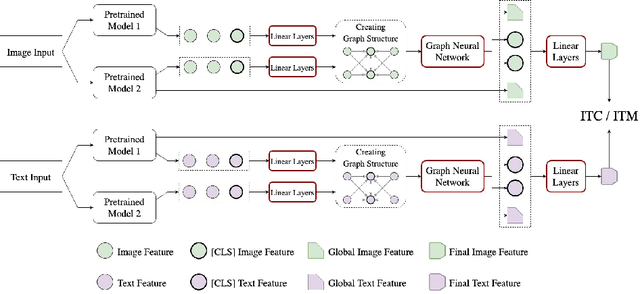
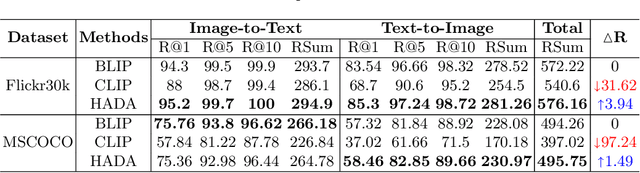
Many models have been proposed for vision and language tasks, especially the image-text retrieval task. All state-of-the-art (SOTA) models in this challenge contained hundreds of millions of parameters. They also were pretrained on a large external dataset that has been proven to make a big improvement in overall performance. It is not easy to propose a new model with a novel architecture and intensively train it on a massive dataset with many GPUs to surpass many SOTA models, which are already available to use on the Internet. In this paper, we proposed a compact graph-based framework, named HADA, which can combine pretrained models to produce a better result, rather than building from scratch. First, we created a graph structure in which the nodes were the features extracted from the pretrained models and the edges connecting them. The graph structure was employed to capture and fuse the information from every pretrained model with each other. Then a graph neural network was applied to update the connection between the nodes to get the representative embedding vector for an image and text. Finally, we used the cosine similarity to match images with their relevant texts and vice versa to ensure a low inference time. Our experiments showed that, although HADA contained a tiny number of trainable parameters, it could increase baseline performance by more than 3.6% in terms of evaluation metrics in the Flickr30k dataset. Additionally, the proposed model did not train on any external dataset and did not require many GPUs but only 1 to train due to its small number of parameters. The source code is available at https://github.com/m2man/HADA.
An Improved Subject-Independent Stress Detection Model Applied to Consumer-grade Wearable Devices
Mar 18, 2022
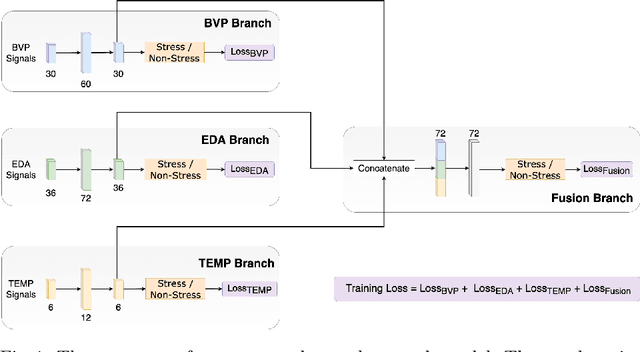
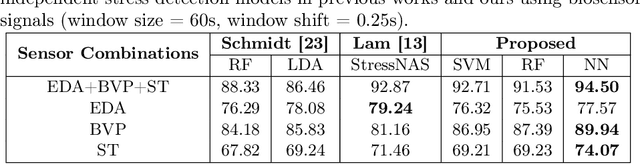
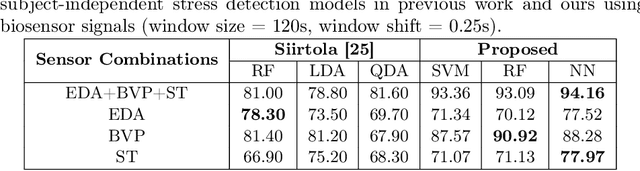
Stress is a complex issue with wide-ranging physical and psychological impacts on human daily performance. Specifically, acute stress detection is becoming a valuable application in contextual human understanding. Two common approaches to training a stress detection model are subject-dependent and subject-independent training methods. Although subject-dependent training methods have proven to be the most accurate approach to build stress detection models, subject-independent models are a more practical and cost-efficient method, as they allow for the deployment of stress level detection and management systems in consumer-grade wearable devices without requiring training data for the end-user. To improve the performance of subject-independent stress detection models, in this paper, we introduce a stress-related bio-signal processing pipeline with a simple neural network architecture using statistical features extracted from multimodal contextual sensing sources including Electrodermal Activity (EDA), Blood Volume Pulse (BVP), and Skin Temperature (ST) captured from a consumer-grade wearable device. Using our proposed model architecture, we compare the accuracy between stress detection models that use measures from each individual signal source, and one model employing the fusion of multiple sensor sources. Extensive experiments on the publicly available WESAD dataset demonstrate that our proposed model outperforms conventional methods as well as providing 1.63% higher mean accuracy score compared to the state-of-the-art model while maintaining a low standard deviation. Our experiments also show that combining features from multiple sources produce more accurate predictions than using only one sensor source individually.
A Deep Local and Global Scene-Graph Matching for Image-Text Retrieval
Jun 04, 2021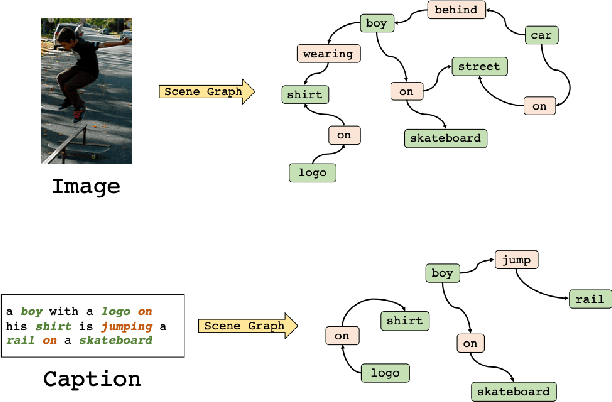
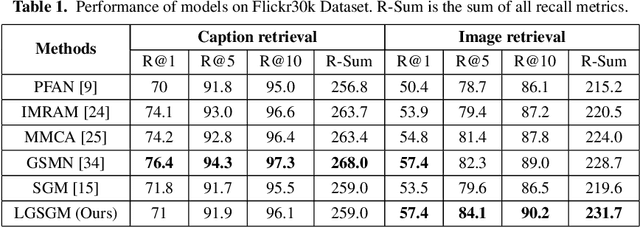
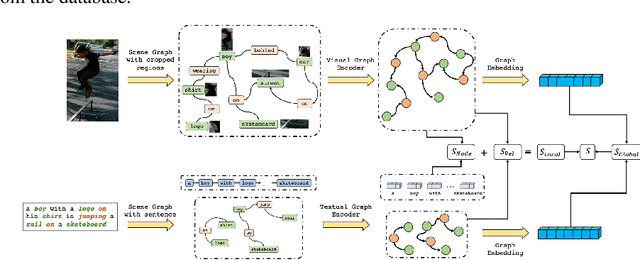
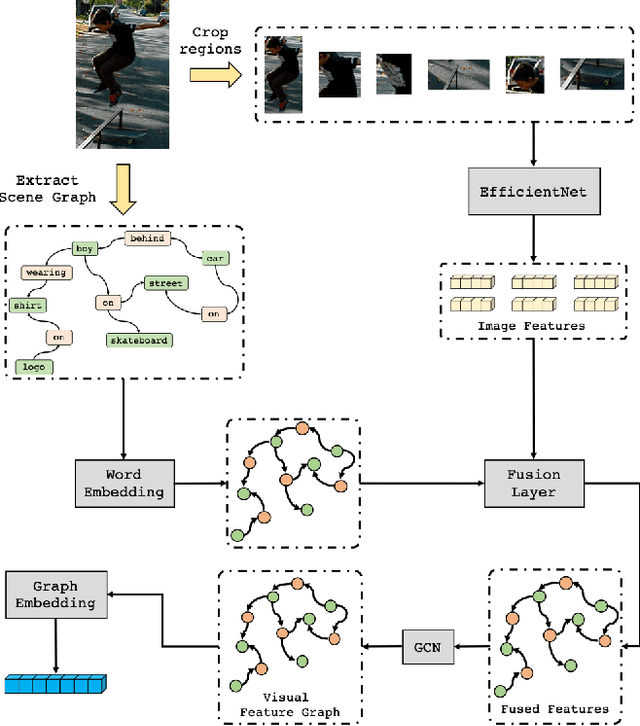
Conventional approaches to image-text retrieval mainly focus on indexing visual objects appearing in pictures but ignore the interactions between these objects. Such objects occurrences and interactions are equivalently useful and important in this field as they are usually mentioned in the text. Scene graph presentation is a suitable method for the image-text matching challenge and obtained good results due to its ability to capture the inter-relationship information. Both images and text are represented in scene graph levels and formulate the retrieval challenge as a scene graph matching challenge. In this paper, we introduce the Local and Global Scene Graph Matching (LGSGM) model that enhances the state-of-the-art method by integrating an extra graph convolution network to capture the general information of a graph. Specifically, for a pair of scene graphs of an image and its caption, two separate models are used to learn the features of each graph's nodes and edges. Then a Siamese-structure graph convolution model is employed to embed graphs into vector forms. We finally combine the graph-level and the vector-level to calculate the similarity of this image-text pair. The empirical experiments show that our enhancement with the combination of levels can improve the performance of the baseline method by increasing the recall by more than 10% on the Flickr30k dataset.
TATL: Task Agnostic Transfer Learning for Skin Attributes Detection
Apr 04, 2021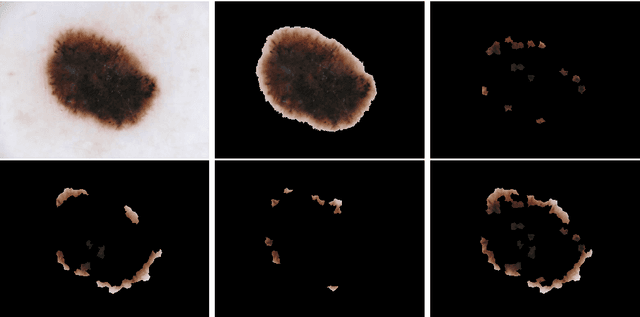
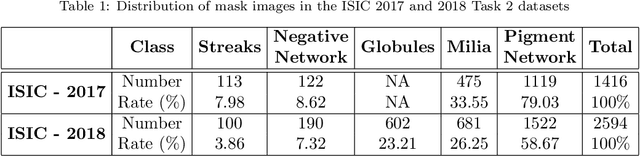
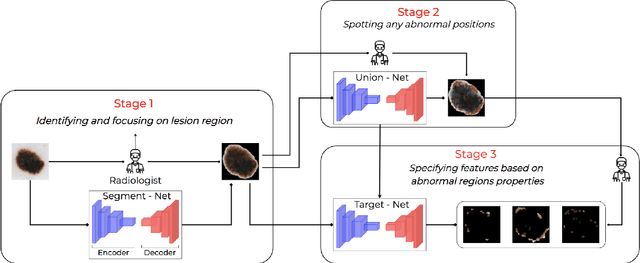
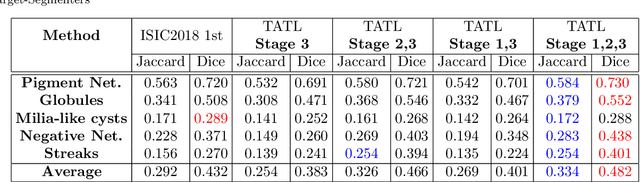
Existing skin attributes detection methods usually initialize with a pre-trained Imagenet network and then fine-tune the medical target task. However, we argue that such approaches are suboptimal because medical datasets are largely different from ImageNet and often contain limited training samples. In this work, we propose Task Agnostic Transfer Learning (TATL), a novel framework motivated by dermatologists' behaviors in the skincare context. TATL learns an attribute-agnostic segmenter that detects lesion skin regions and then transfers this knowledge to a set of attribute-specific classifiers to detect each particular region's attributes. Since TATL's attribute-agnostic segmenter only detects abnormal skin regions, it enjoys ample data from all attributes, allows transferring knowledge among features, and compensates for the lack of training data from rare attributes. We extensively evaluate TATL on two popular skin attributes detection benchmarks and show that TATL outperforms state-of-the-art methods while enjoying minimal model and computational complexity. We also provide theoretical insights and explanations for why TATL works well in practice.