 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe State-of-the-Art in Lifelog Retrieval: A Review of Progress at the ACM Lifelog Search Challenge Workshop 2022-24
Jun 07, 2025The ACM Lifelog Search Challenge (LSC) is a venue that welcomes and compares systems that support the exploration of lifelog data, and in particular the retrieval of specific information, through an interactive competition format. This paper reviews the recent advances in interactive lifelog retrieval as demonstrated at the ACM LSC from 2022 to 2024. Through a detailed comparative analysis, we highlight key improvements across three main retrieval tasks: known-item search, question answering, and ad-hoc search. Our analysis identifies trends such as the widespread adoption of embedding-based retrieval methods (e.g., CLIP, BLIP), increased integration of large language models (LLMs) for conversational retrieval, and continued innovation in multimodal and collaborative search interfaces. We further discuss how specific retrieval techniques and user interface (UI) designs have impacted system performance, emphasizing the importance of balancing retrieval complexity with usability. Our findings indicate that embedding-driven approaches combined with LLMs show promise for lifelog retrieval systems. Likewise, improving UI design can enhance usability and efficiency. Additionally, we recommend reconsidering multi-instance system evaluations within the expert track to better manage variability in user familiarity and configuration effectiveness.
The CASTLE 2024 Dataset: Advancing the Art of Multimodal Understanding
Mar 21, 2025Egocentric video has seen increased interest in recent years, as it is used in a range of areas. However, most existing datasets are limited to a single perspective. In this paper, we present the CASTLE 2024 dataset, a multimodal collection containing ego- and exo-centric (i.e., first- and third-person perspective) video and audio from 15 time-aligned sources, as well as other sensor streams and auxiliary data. The dataset was recorded by volunteer participants over four days in a fixed location and includes the point of view of 10 participants, with an additional 5 fixed cameras providing an exocentric perspective. The entire dataset contains over 600 hours of UHD video recorded at 50 frames per second. In contrast to other datasets, CASTLE 2024 does not contain any partial censoring, such as blurred faces or distorted audio. The dataset is available via https://castle-dataset.github.io/.
Efficient Object-centric Representation Learning with Pre-trained Geometric Prior
Dec 16, 2024This paper addresses key challenges in object-centric representation learning of video. While existing approaches struggle with complex scenes, we propose a novel weakly-supervised framework that emphasises geometric understanding and leverages pre-trained vision models to enhance object discovery. Our method introduces an efficient slot decoder specifically designed for object-centric learning, enabling effective representation of multi-object scenes without requiring explicit depth information. Results on synthetic video benchmarks with increasing complexity in terms of objects and their movement, object occlusion and camera motion demonstrate that our approach achieves comparable performance to supervised methods while maintaining computational efficiency. This advances the field towards more practical applications in complex real-world scenarios.
Diffusing Surrogate Dreams of Video Scenes to Predict Video Memorability
Dec 19, 2022


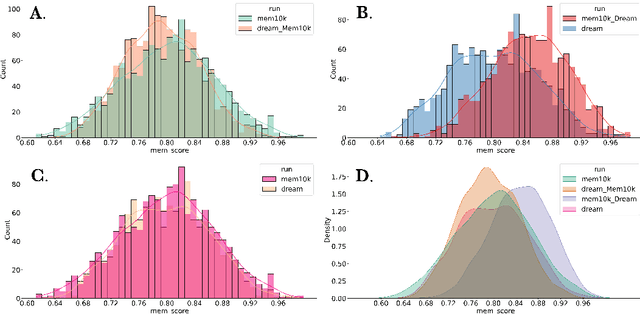
As part of the MediaEval 2022 Predicting Video Memorability task we explore the relationship between visual memorability, the visual representation that characterises it, and the underlying concept portrayed by that visual representation. We achieve state-of-the-art memorability prediction performance with a model trained and tested exclusively on surrogate dream images, elevating concepts to the status of a cornerstone memorability feature, and finding strong evidence to suggest that the intrinsic memorability of visual content can be distilled to its underlying concept or meaning irrespective of its specific visual representational.
Overview of The MediaEval 2022 Predicting Video Memorability Task
Dec 13, 2022This paper describes the 5th edition of the Predicting Video Memorability Task as part of MediaEval2022. This year we have reorganised and simplified the task in order to lubricate a greater depth of inquiry. Similar to last year, two datasets are provided in order to facilitate generalisation, however, this year we have replaced the TRECVid2019 Video-to-Text dataset with the VideoMem dataset in order to remedy underlying data quality issues, and to prioritise short-term memorability prediction by elevating the Memento10k dataset as the primary dataset. Additionally, a fully fledged electroencephalography (EEG)-based prediction sub-task is introduced. In this paper, we outline the core facets of the task and its constituent sub-tasks; describing the datasets, evaluation metrics, and requirements for participant submissions.
Experiences from the MediaEval Predicting Media Memorability Task
Dec 07, 2022


The Predicting Media Memorability task in the MediaEval evaluation campaign has been running annually since 2018 and several different tasks and data sets have been used in this time. This has allowed us to compare the performance of many memorability prediction techniques on the same data and in a reproducible way and to refine and improve on those techniques. The resources created to compute media memorability are now being used by researchers well beyond the actual evaluation campaign. In this paper we present a summary of the task, including the collective lessons we have learned for the research community.
An Improved Subject-Independent Stress Detection Model Applied to Consumer-grade Wearable Devices
Mar 18, 2022
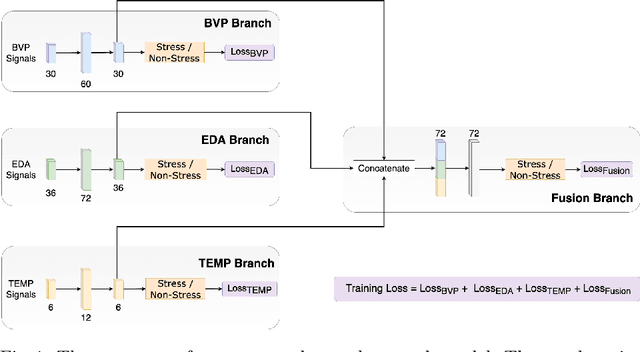
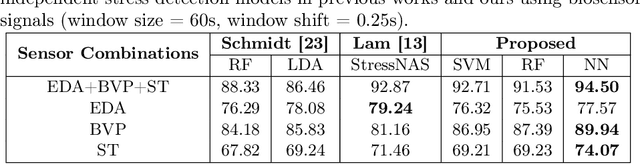
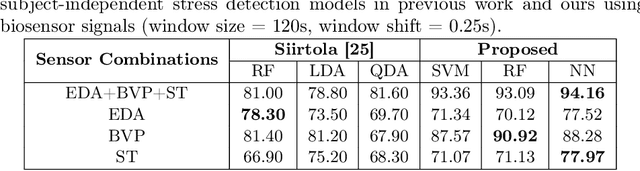
Stress is a complex issue with wide-ranging physical and psychological impacts on human daily performance. Specifically, acute stress detection is becoming a valuable application in contextual human understanding. Two common approaches to training a stress detection model are subject-dependent and subject-independent training methods. Although subject-dependent training methods have proven to be the most accurate approach to build stress detection models, subject-independent models are a more practical and cost-efficient method, as they allow for the deployment of stress level detection and management systems in consumer-grade wearable devices without requiring training data for the end-user. To improve the performance of subject-independent stress detection models, in this paper, we introduce a stress-related bio-signal processing pipeline with a simple neural network architecture using statistical features extracted from multimodal contextual sensing sources including Electrodermal Activity (EDA), Blood Volume Pulse (BVP), and Skin Temperature (ST) captured from a consumer-grade wearable device. Using our proposed model architecture, we compare the accuracy between stress detection models that use measures from each individual signal source, and one model employing the fusion of multiple sensor sources. Extensive experiments on the publicly available WESAD dataset demonstrate that our proposed model outperforms conventional methods as well as providing 1.63% higher mean accuracy score compared to the state-of-the-art model while maintaining a low standard deviation. Our experiments also show that combining features from multiple sources produce more accurate predictions than using only one sensor source individually.
Overview of the EEG Pilot Subtask at MediaEval 2021: Predicting Media Memorability
Dec 15, 2021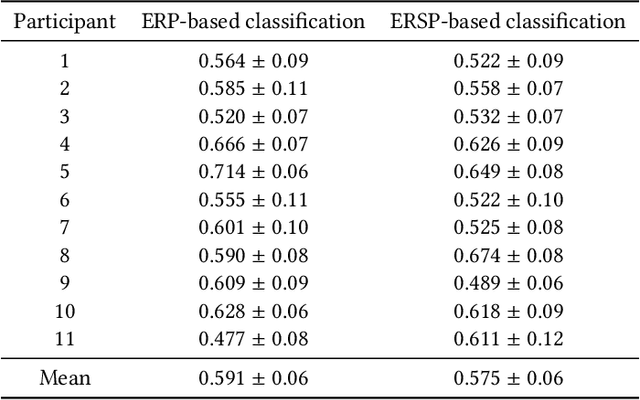
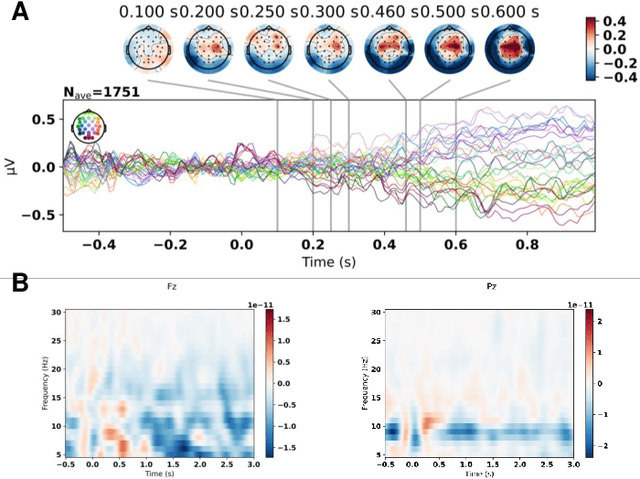
The aim of the Memorability-EEG pilot subtask at MediaEval'2021 is to promote interest in the use of neural signals -- either alone or in combination with other data sources -- in the context of predicting video memorability by highlighting the utility of EEG data. The dataset created consists of pre-extracted features from EEG recordings of subjects while watching a subset of videos from Predicting Media Memorability subtask 1. This demonstration pilot gives interested researchers a sense of how neural signals can be used without any prior domain knowledge, and enables them to do so in a future memorability task. The dataset can be used to support the exploration of novel machine learning and processing strategies for predicting video memorability, while potentially increasing interdisciplinary interest in the subject of memorability, and opening the door to new combined EEG-computer vision approaches.
Predicting Media Memorability: Comparing Visual, Textual and Auditory Features
Dec 15, 2021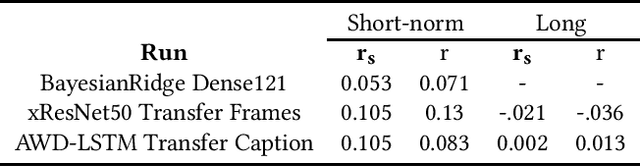
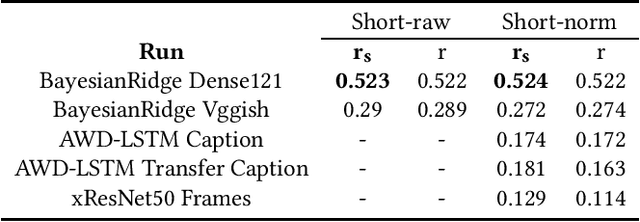
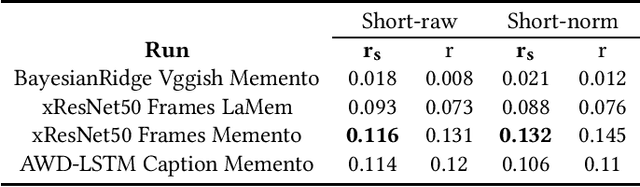
This paper describes our approach to the Predicting Media Memorability task in MediaEval 2021, which aims to address the question of media memorability by setting the task of automatically predicting video memorability. This year we tackle the task from a comparative standpoint, looking to gain deeper insights into each of three explored modalities, and using our results from last year's submission (2020) as a point of reference. Our best performing short-term memorability model (0.132) tested on the TRECVid2019 dataset -- just like last year -- was a frame based CNN that was not trained on any TRECVid data, and our best short-term memorability model (0.524) tested on the Memento10k dataset, was a Bayesian Ride Regressor fit with DenseNet121 visual features.
Overview of The MediaEval 2021 Predicting Media Memorability Task
Dec 11, 2021This paper describes the MediaEval 2021 Predicting Media Memorability}task, which is in its 4th edition this year, as the prediction of short-term and long-term video memorability remains a challenging task. In 2021, two datasets of videos are used: first, a subset of the TRECVid 2019 Video-to-Text dataset; second, the Memento10K dataset in order to provide opportunities to explore cross-dataset generalisation. In addition, an Electroencephalography (EEG)-based prediction pilot subtask is introduced. In this paper, we outline the main aspects of the task and describe the datasets, evaluation metrics, and requirements for participants' submissions.