 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuizzard@INOVA Challenge 2025 -- Track A: Plug-and-Play Technique in Interleaved Multi-Image Model
Jun 13, 2025This paper addresses two main objectives. Firstly, we demonstrate the impressive performance of the LLaVA-NeXT-interleave on 22 datasets across three different tasks: Multi-Image Reasoning, Documents and Knowledge-Based Understanding and Interactive Multi-Modal Communication. Secondly, we add the Dense Channel Integration (DCI) connector to the LLaVA-NeXT-Interleave and compare its performance against the standard model. We find that the standard model achieves the highest overall accuracy, excelling in vision-heavy tasks like VISION, NLVR2, and Fashion200K. Meanwhile, the DCI-enhanced version shows particular strength on datasets requiring deeper semantic coherence or structured change understanding such as MIT-States_PropertyCoherence and SlideVQA. Our results highlight the potential of combining powerful foundation models with plug-and-play techniques for Interleave tasks. The code is available at https://github.com/dinhvietcuong1996/icme25-inova.
The State-of-the-Art in Lifelog Retrieval: A Review of Progress at the ACM Lifelog Search Challenge Workshop 2022-24
Jun 07, 2025The ACM Lifelog Search Challenge (LSC) is a venue that welcomes and compares systems that support the exploration of lifelog data, and in particular the retrieval of specific information, through an interactive competition format. This paper reviews the recent advances in interactive lifelog retrieval as demonstrated at the ACM LSC from 2022 to 2024. Through a detailed comparative analysis, we highlight key improvements across three main retrieval tasks: known-item search, question answering, and ad-hoc search. Our analysis identifies trends such as the widespread adoption of embedding-based retrieval methods (e.g., CLIP, BLIP), increased integration of large language models (LLMs) for conversational retrieval, and continued innovation in multimodal and collaborative search interfaces. We further discuss how specific retrieval techniques and user interface (UI) designs have impacted system performance, emphasizing the importance of balancing retrieval complexity with usability. Our findings indicate that embedding-driven approaches combined with LLMs show promise for lifelog retrieval systems. Likewise, improving UI design can enhance usability and efficiency. Additionally, we recommend reconsidering multi-instance system evaluations within the expert track to better manage variability in user familiarity and configuration effectiveness.
LSC-ADL: An Activity of Daily Living (ADL)-Annotated Lifelog Dataset Generated via Semi-Automatic Clustering
Apr 02, 2025Lifelogging involves continuously capturing personal data through wearable cameras, providing an egocentric view of daily activities. Lifelog retrieval aims to search and retrieve relevant moments from this data, yet existing methods largely overlook activity-level annotations, which capture temporal relationships and enrich semantic understanding. In this work, we introduce LSC-ADL, an ADL-annotated lifelog dataset derived from the LSC dataset, incorporating Activities of Daily Living (ADLs) as a structured semantic layer. Using a semi-automatic approach featuring the HDBSCAN algorithm for intra-class clustering and human-in-the-loop verification, we generate accurate ADL annotations to enhance retrieval explainability. By integrating action recognition into lifelog retrieval, LSC-ADL bridges a critical gap in existing research, offering a more context-aware representation of daily life. We believe this dataset will advance research in lifelog retrieval, activity recognition, and egocentric vision, ultimately improving the accuracy and interpretability of retrieved content. The ADL annotations can be downloaded at https://bit.ly/lsc-adl-annotations.
The CASTLE 2024 Dataset: Advancing the Art of Multimodal Understanding
Mar 21, 2025Egocentric video has seen increased interest in recent years, as it is used in a range of areas. However, most existing datasets are limited to a single perspective. In this paper, we present the CASTLE 2024 dataset, a multimodal collection containing ego- and exo-centric (i.e., first- and third-person perspective) video and audio from 15 time-aligned sources, as well as other sensor streams and auxiliary data. The dataset was recorded by volunteer participants over four days in a fixed location and includes the point of view of 10 participants, with an additional 5 fixed cameras providing an exocentric perspective. The entire dataset contains over 600 hours of UHD video recorded at 50 frames per second. In contrast to other datasets, CASTLE 2024 does not contain any partial censoring, such as blurred faces or distorted audio. The dataset is available via https://castle-dataset.github.io/.
Lifelogging As An Extreme Form of Personal Information Management -- What Lessons To Learn
Jan 11, 2024
Personal data includes the digital footprints that we leave behind as part of our everyday activities, both online and offline in the real world. It includes data we collect ourselves, such as from wearables, as well as the data collected by others about our online behaviour and activities. Sometimes we are able to use the personal data we ourselves collect, in order to examine some parts of our lives but for the most part, our personal data is leveraged by third parties including internet companies, for services like targeted advertising and recommendations. Lifelogging is a form of extreme personal data gathering and in this article we present an overview of the tools used to manage access to lifelogs as demonstrated at the most recent of the annual Lifelog Search Challenge benchmarking workshops. Here, experimental systems are showcased in live, real time information seeking tasks by real users. This overview of these systems' capabilities show the range of possibilities for accessing our own personal data which may, in time, become more easily available as consumer-level services.
Dialogue-to-Video Retrieval
Mar 23, 2023Recent years have witnessed an increasing amount of dialogue/conversation on the web especially on social media. That inspires the development of dialogue-based retrieval, in which retrieving videos based on dialogue is of increasing interest for recommendation systems. Different from other video retrieval tasks, dialogue-to-video retrieval uses structured queries in the form of user-generated dialogue as the search descriptor. We present a novel dialogue-to-video retrieval system, incorporating structured conversational information. Experiments conducted on the AVSD dataset show that our proposed approach using plain-text queries improves over the previous counterpart model by 15.8% on R@1. Furthermore, our approach using dialogue as a query, improves retrieval performance by 4.2%, 6.2%, 8.6% on R@1, R@5 and R@10 and outperforms the state-of-the-art model by 0.7%, 3.6% and 6.0% on R@1, R@5 and R@10 respectively.
HADA: A Graph-based Amalgamation Framework in Image-text Retrieval
Jan 11, 2023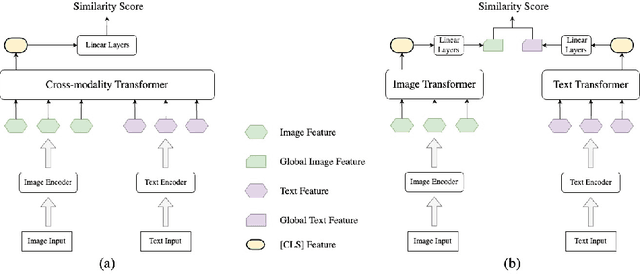
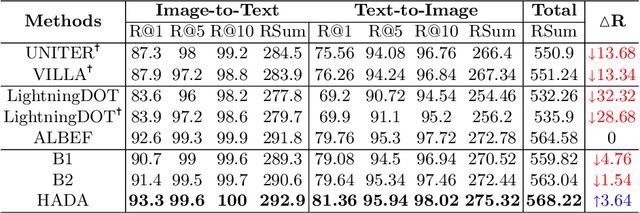
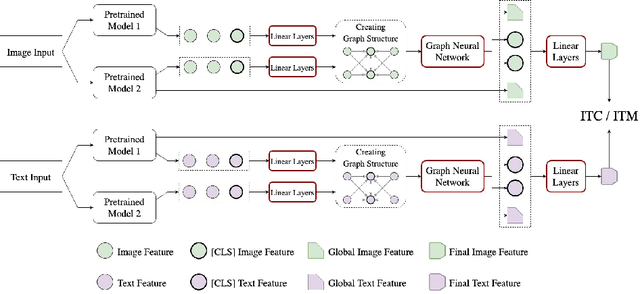
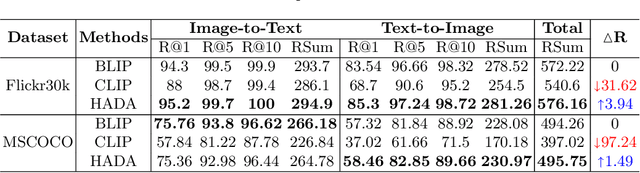
Many models have been proposed for vision and language tasks, especially the image-text retrieval task. All state-of-the-art (SOTA) models in this challenge contained hundreds of millions of parameters. They also were pretrained on a large external dataset that has been proven to make a big improvement in overall performance. It is not easy to propose a new model with a novel architecture and intensively train it on a massive dataset with many GPUs to surpass many SOTA models, which are already available to use on the Internet. In this paper, we proposed a compact graph-based framework, named HADA, which can combine pretrained models to produce a better result, rather than building from scratch. First, we created a graph structure in which the nodes were the features extracted from the pretrained models and the edges connecting them. The graph structure was employed to capture and fuse the information from every pretrained model with each other. Then a graph neural network was applied to update the connection between the nodes to get the representative embedding vector for an image and text. Finally, we used the cosine similarity to match images with their relevant texts and vice versa to ensure a low inference time. Our experiments showed that, although HADA contained a tiny number of trainable parameters, it could increase baseline performance by more than 3.6% in terms of evaluation metrics in the Flickr30k dataset. Additionally, the proposed model did not train on any external dataset and did not require many GPUs but only 1 to train due to its small number of parameters. The source code is available at https://github.com/m2man/HADA.
Analysing the Performance of Stress Detection Models on Consumer-Grade Wearable Devices
Mar 18, 2022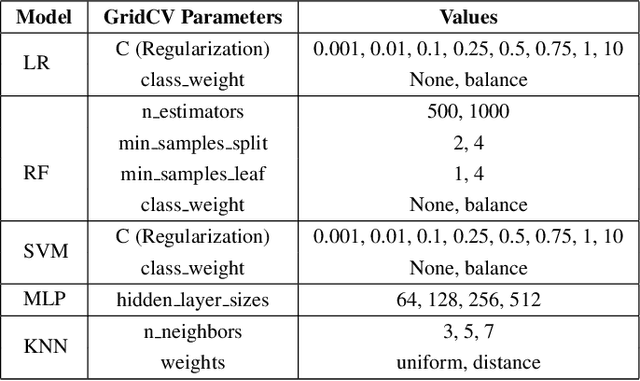
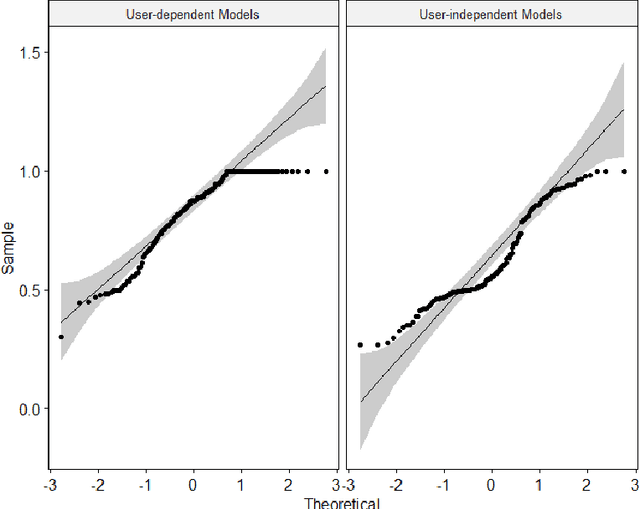
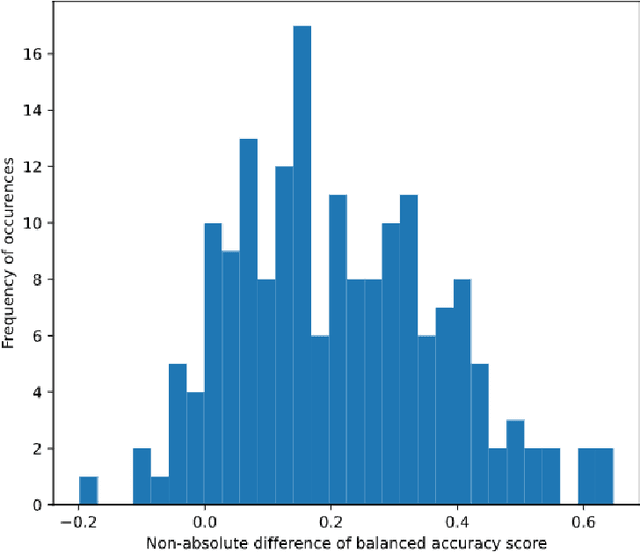
Identifying stress levels can provide valuable data for mental health analytics as well as labels for annotation systems. Although much research has been conducted into stress detection models using heart rate variability at a higher cost of data collection, there is a lack of research on the potential of using low-resolution Electrodermal Activity (EDA) signals from consumer-grade wearable devices to identify stress patterns. In this paper, we concentrate on performing statistical analyses on the stress detection capability of two popular approaches of training stress detection models with stress-related biometric signals: user-dependent and user-independent models. Our research manages to show that user-dependent models are statistically more accurate for stress detection. In terms of effectiveness assessment, the balanced accuracy (BA) metric is employed to evaluate the capability of distinguishing stress and non-stress conditions of the models trained on either low-resolution or high-resolution Electrodermal Activity (EDA) signals. The results from the experiment show that training the model with (comparatively low-cost) low-resolution EDA signal does not affect the stress detection accuracy of the model significantly compared to using a high-resolution EDA signal. Our research results demonstrate the potential of attaching the user-dependent stress detection model trained on personal low-resolution EDA signal recorded to collect data in daily life to provide users with personal stress level insight and analysis.
An Improved Subject-Independent Stress Detection Model Applied to Consumer-grade Wearable Devices
Mar 18, 2022
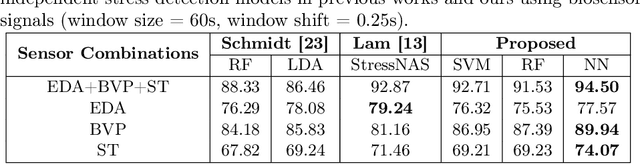
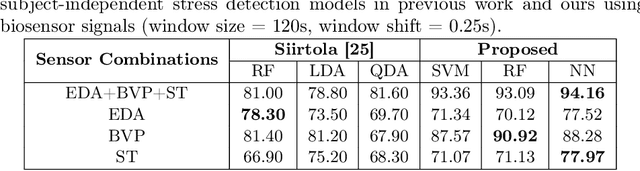
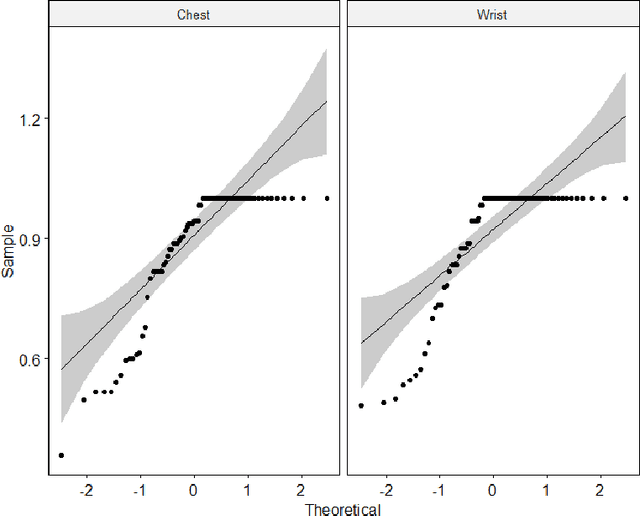
Stress is a complex issue with wide-ranging physical and psychological impacts on human daily performance. Specifically, acute stress detection is becoming a valuable application in contextual human understanding. Two common approaches to training a stress detection model are subject-dependent and subject-independent training methods. Although subject-dependent training methods have proven to be the most accurate approach to build stress detection models, subject-independent models are a more practical and cost-efficient method, as they allow for the deployment of stress level detection and management systems in consumer-grade wearable devices without requiring training data for the end-user. To improve the performance of subject-independent stress detection models, in this paper, we introduce a stress-related bio-signal processing pipeline with a simple neural network architecture using statistical features extracted from multimodal contextual sensing sources including Electrodermal Activity (EDA), Blood Volume Pulse (BVP), and Skin Temperature (ST) captured from a consumer-grade wearable device. Using our proposed model architecture, we compare the accuracy between stress detection models that use measures from each individual signal source, and one model employing the fusion of multiple sensor sources. Extensive experiments on the publicly available WESAD dataset demonstrate that our proposed model outperforms conventional methods as well as providing 1.63% higher mean accuracy score compared to the state-of-the-art model while maintaining a low standard deviation. Our experiments also show that combining features from multiple sources produce more accurate predictions than using only one sensor source individually.
A Deep Local and Global Scene-Graph Matching for Image-Text Retrieval
Jun 04, 2021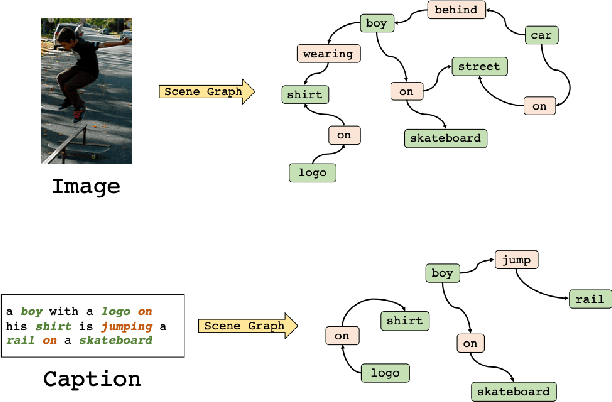
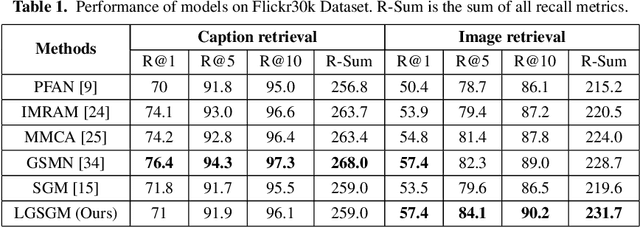
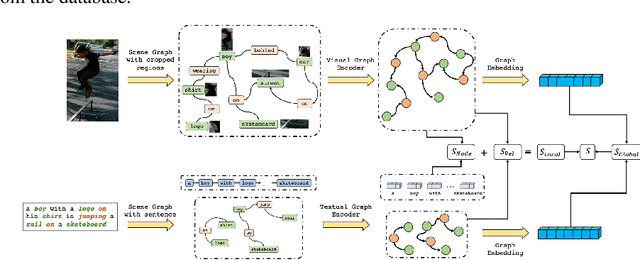
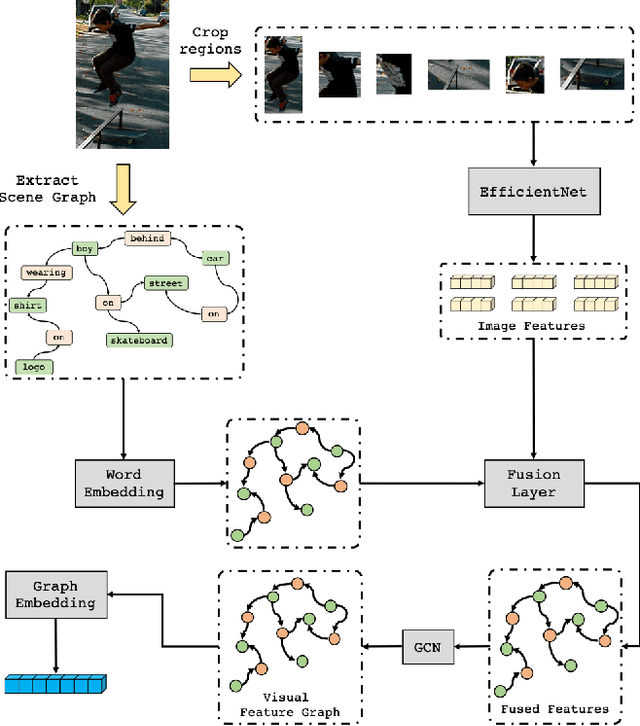
Conventional approaches to image-text retrieval mainly focus on indexing visual objects appearing in pictures but ignore the interactions between these objects. Such objects occurrences and interactions are equivalently useful and important in this field as they are usually mentioned in the text. Scene graph presentation is a suitable method for the image-text matching challenge and obtained good results due to its ability to capture the inter-relationship information. Both images and text are represented in scene graph levels and formulate the retrieval challenge as a scene graph matching challenge. In this paper, we introduce the Local and Global Scene Graph Matching (LGSGM) model that enhances the state-of-the-art method by integrating an extra graph convolution network to capture the general information of a graph. Specifically, for a pair of scene graphs of an image and its caption, two separate models are used to learn the features of each graph's nodes and edges. Then a Siamese-structure graph convolution model is employed to embed graphs into vector forms. We finally combine the graph-level and the vector-level to calculate the similarity of this image-text pair. The empirical experiments show that our enhancement with the combination of levels can improve the performance of the baseline method by increasing the recall by more than 10% on the Flickr30k dataset.