 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-Fed: SAM-Guided Federated Semi-Supervised Learning for Medical Image Segmentation
Nov 18, 2025Medical image segmentation is clinically important, yet data privacy and the cost of expert annotation limit the availability of labeled data. Federated semi-supervised learning (FSSL) offers a solution but faces two challenges: pseudo-label reliability depends on the strength of local models, and client devices often require compact or heterogeneous architectures due to limited computational resources. These constraints reduce the quality and stability of pseudo-labels, while large models, though more accurate, cannot be trained or used for routine inference on client devices. We propose SAM-Fed, a federated semi-supervised framework that leverages a high-capacity segmentation foundation model to guide lightweight clients during training. SAM-Fed combines dual knowledge distillation with an adaptive agreement mechanism to refine pixel-level supervision. Experiments on skin lesion and polyp segmentation across homogeneous and heterogeneous settings show that SAM-Fed consistently outperforms state-of-the-art FSSL methods.
lifeXplore at the Lifelog Search Challenge 2021
Sep 03, 2025Since its first iteration in 2018, the Lifelog Search Challenge (LSC) continues to rise in popularity as an interactive lifelog data retrieval competition, co-located at the ACM International Conference on Multimedia Retrieval (ICMR). The goal of this annual live event is to search a large corpus of lifelogging data for specifically announced memories using a purposefully developed tool within a limited amount of time. As long-standing participants, we present our improved lifeXplore - a retrieval system combining chronologic day summary browsing with interactive combinable concept filtering. Compared to previous versions, the tool is improved by incorporating temporal queries, advanced day summary features as well as usability improvements.
GynSurg: A Comprehensive Gynecology Laparoscopic Surgery Dataset
Jun 12, 2025Recent advances in deep learning have transformed computer-assisted intervention and surgical video analysis, driving improvements not only in surgical training, intraoperative decision support, and patient outcomes, but also in postoperative documentation and surgical discovery. Central to these developments is the availability of large, high-quality annotated datasets. In gynecologic laparoscopy, surgical scene understanding and action recognition are fundamental for building intelligent systems that assist surgeons during operations and provide deeper analysis after surgery. However, existing datasets are often limited by small scale, narrow task focus, or insufficiently detailed annotations, limiting their utility for comprehensive, end-to-end workflow analysis. To address these limitations, we introduce GynSurg, the largest and most diverse multi-task dataset for gynecologic laparoscopic surgery to date. GynSurg provides rich annotations across multiple tasks, supporting applications in action recognition, semantic segmentation, surgical documentation, and discovery of novel procedural insights. We demonstrate the dataset quality and versatility by benchmarking state-of-the-art models under a standardized training protocol. To accelerate progress in the field, we publicly release the GynSurg dataset and its annotations
WetCat: Automating Skill Assessment in Wetlab Cataract Surgery Videos
Jun 10, 2025To meet the growing demand for systematic surgical training, wetlab environments have become indispensable platforms for hands-on practice in ophthalmology. Yet, traditional wetlab training depends heavily on manual performance evaluations, which are labor-intensive, time-consuming, and often subject to variability. Recent advances in computer vision offer promising avenues for automated skill assessment, enhancing both the efficiency and objectivity of surgical education. Despite notable progress in ophthalmic surgical datasets, existing resources predominantly focus on real surgeries or isolated tasks, falling short of supporting comprehensive skill evaluation in controlled wetlab settings. To address these limitations, we introduce WetCat, the first dataset of wetlab cataract surgery videos specifically curated for automated skill assessment. WetCat comprises high-resolution recordings of surgeries performed by trainees on artificial eyes, featuring comprehensive phase annotations and semantic segmentations of key anatomical structures. These annotations are meticulously designed to facilitate skill assessment during the critical capsulorhexis and phacoemulsification phases, adhering to standardized surgical skill assessment frameworks. By focusing on these essential phases, WetCat enables the development of interpretable, AI-driven evaluation tools aligned with established clinical metrics. This dataset lays a strong foundation for advancing objective, scalable surgical education and sets a new benchmark for automated workflow analysis and skill assessment in ophthalmology training. The dataset and annotations are publicly available in Synapse https://www.synapse.org/Synapse:syn66401174/files.
The State-of-the-Art in Lifelog Retrieval: A Review of Progress at the ACM Lifelog Search Challenge Workshop 2022-24
Jun 07, 2025The ACM Lifelog Search Challenge (LSC) is a venue that welcomes and compares systems that support the exploration of lifelog data, and in particular the retrieval of specific information, through an interactive competition format. This paper reviews the recent advances in interactive lifelog retrieval as demonstrated at the ACM LSC from 2022 to 2024. Through a detailed comparative analysis, we highlight key improvements across three main retrieval tasks: known-item search, question answering, and ad-hoc search. Our analysis identifies trends such as the widespread adoption of embedding-based retrieval methods (e.g., CLIP, BLIP), increased integration of large language models (LLMs) for conversational retrieval, and continued innovation in multimodal and collaborative search interfaces. We further discuss how specific retrieval techniques and user interface (UI) designs have impacted system performance, emphasizing the importance of balancing retrieval complexity with usability. Our findings indicate that embedding-driven approaches combined with LLMs show promise for lifelog retrieval systems. Likewise, improving UI design can enhance usability and efficiency. Additionally, we recommend reconsidering multi-instance system evaluations within the expert track to better manage variability in user familiarity and configuration effectiveness.
Feedback-Driven Pseudo-Label Reliability Assessment: Redefining Thresholding for Semi-Supervised Semantic Segmentation
May 12, 2025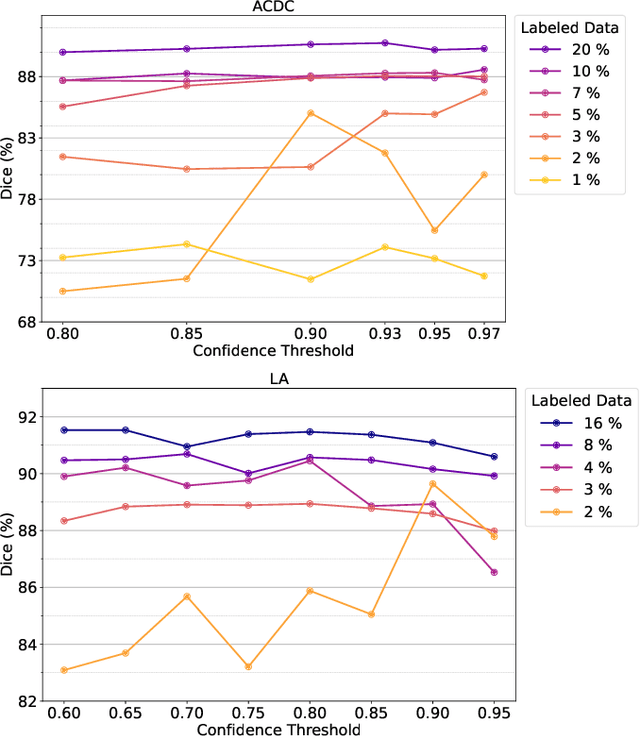
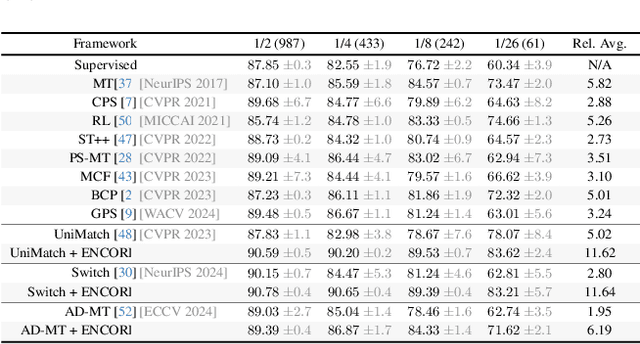
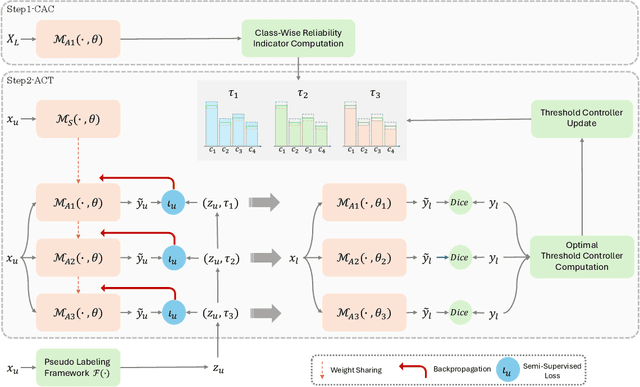
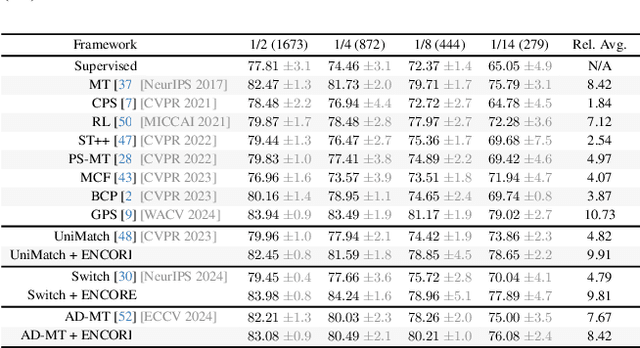
Semi-supervised learning leverages unlabeled data to enhance model performance, addressing the limitations of fully supervised approaches. Among its strategies, pseudo-supervision has proven highly effective, typically relying on one or multiple teacher networks to refine pseudo-labels before training a student network. A common practice in pseudo-supervision is filtering pseudo-labels based on pre-defined confidence thresholds or entropy. However, selecting optimal thresholds requires large labeled datasets, which are often scarce in real-world semi-supervised scenarios. To overcome this challenge, we propose Ensemble-of-Confidence Reinforcement (ENCORE), a dynamic feedback-driven thresholding strategy for pseudo-label selection. Instead of relying on static confidence thresholds, ENCORE estimates class-wise true-positive confidence within the unlabeled dataset and continuously adjusts thresholds based on the model's response to different levels of pseudo-label filtering. This feedback-driven mechanism ensures the retention of informative pseudo-labels while filtering unreliable ones, enhancing model training without manual threshold tuning. Our method seamlessly integrates into existing pseudo-supervision frameworks and significantly improves segmentation performance, particularly in data-scarce conditions. Extensive experiments demonstrate that integrating ENCORE with existing pseudo-supervision frameworks enhances performance across multiple datasets and network architectures, validating its effectiveness in semi-supervised learning.
Dual Invariance Self-training for Reliable Semi-supervised Surgical Phase Recognition
Jan 29, 2025



Accurate surgical phase recognition is crucial for advancing computer-assisted interventions, yet the scarcity of labeled data hinders training reliable deep learning models. Semi-supervised learning (SSL), particularly with pseudo-labeling, shows promise over fully supervised methods but often lacks reliable pseudo-label assessment mechanisms. To address this gap, we propose a novel SSL framework, Dual Invariance Self-Training (DIST), that incorporates both Temporal and Transformation Invariance to enhance surgical phase recognition. Our two-step self-training process dynamically selects reliable pseudo-labels, ensuring robust pseudo-supervision. Our approach mitigates the risk of noisy pseudo-labels, steering decision boundaries toward true data distribution and improving generalization to unseen data. Evaluations on Cataract and Cholec80 datasets show our method outperforms state-of-the-art SSL approaches, consistently surpassing both supervised and SSL baselines across various network architectures.
Cataract-1K: Cataract Surgery Dataset for Scene Segmentation, Phase Recognition, and Irregularity Detection
Dec 11, 2023In recent years, the landscape of computer-assisted interventions and post-operative surgical video analysis has been dramatically reshaped by deep-learning techniques, resulting in significant advancements in surgeons' skills, operation room management, and overall surgical outcomes. However, the progression of deep-learning-powered surgical technologies is profoundly reliant on large-scale datasets and annotations. Particularly, surgical scene understanding and phase recognition stand as pivotal pillars within the realm of computer-assisted surgery and post-operative assessment of cataract surgery videos. In this context, we present the largest cataract surgery video dataset that addresses diverse requisites for constructing computerized surgical workflow analysis and detecting post-operative irregularities in cataract surgery. We validate the quality of annotations by benchmarking the performance of several state-of-the-art neural network architectures for phase recognition and surgical scene segmentation. Besides, we initiate the research on domain adaptation for instrument segmentation in cataract surgery by evaluating cross-domain instrument segmentation performance in cataract surgery videos. The dataset and annotations will be publicly available upon acceptance of the paper.
DeepPyramid+: Medical Image Segmentation using Pyramid View Fusion and Deformable Pyramid Reception
Dec 06, 2023Semantic Segmentation plays a pivotal role in many applications related to medical image and video analysis. However, designing a neural network architecture for medical image and surgical video segmentation is challenging due to the diverse features of relevant classes, including heterogeneity, deformability, transparency, blunt boundaries, and various distortions. We propose a network architecture, DeepPyramid+, which addresses diverse challenges encountered in medical image and surgical video segmentation. The proposed DeepPyramid+ incorporates two major modules, namely "Pyramid View Fusion" (PVF) and "Deformable Pyramid Reception," (DPR), to address the outlined challenges. PVF replicates a deduction process within the neural network, aligning with the human visual system, thereby enhancing the representation of relative information at each pixel position. Complementarily, DPR introduces shape- and scale-adaptive feature extraction techniques using dilated deformable convolutions, enhancing accuracy and robustness in handling heterogeneous classes and deformable shapes. Extensive experiments conducted on diverse datasets, including endometriosis videos, MRI images, OCT scans, and cataract and laparoscopy videos, demonstrate the effectiveness of DeepPyramid+ in handling various challenges such as shape and scale variation, reflection, and blur degradation. DeepPyramid+ demonstrates significant improvements in segmentation performance, achieving up to a 3.65% increase in Dice coefficient for intra-domain segmentation and up to a 17% increase in Dice coefficient for cross-domain segmentation. DeepPyramid+ consistently outperforms state-of-the-art networks across diverse modalities considering different backbone networks, showcasing its versatility.
Predicting Postoperative Intraocular Lens Dislocation in Cataract Surgery via Deep Learning
Dec 06, 2023



A critical yet unpredictable complication following cataract surgery is intraocular lens dislocation. Postoperative stability is imperative, as even a tiny decentration of multifocal lenses or inadequate alignment of the torus in toric lenses due to postoperative rotation can lead to a significant drop in visual acuity. Investigating possible intraoperative indicators that can predict post-surgical instabilities of intraocular lenses can help prevent this complication. In this paper, we develop and evaluate the first fully-automatic framework for the computation of lens unfolding delay, rotation, and instability during surgery. Adopting a combination of three types of CNNs, namely recurrent, region-based, and pixel-based, the proposed framework is employed to assess the possibility of predicting post-operative lens dislocation during cataract surgery. This is achieved via performing a large-scale study on the statistical differences between the behavior of different brands of intraocular lenses and aligning the results with expert surgeons' hypotheses and observations about the lenses. We exploit a large-scale dataset of cataract surgery videos featuring four intraocular lens brands. Experimental results confirm the reliability of the proposed framework in evaluating the lens' statistics during the surgery. The Pearson correlation and t-test results reveal significant correlations between lens unfolding delay and lens rotation and significant differences between the intra-operative rotations stability of four groups of lenses. These results suggest that the proposed framework can help surgeons select the lenses based on the patient's eye conditions and predict post-surgical lens dislocation.