 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation for Medical Image Segmentation using Transformation-Invariant Self-Training
Paper and Code
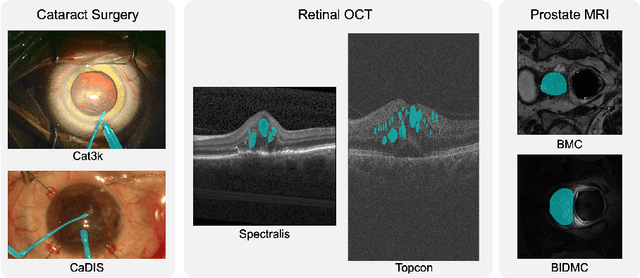

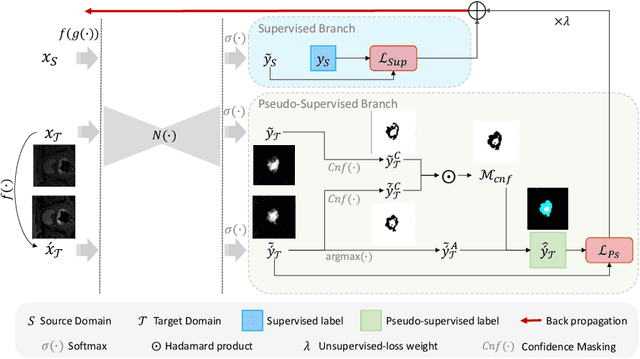

Models capable of leveraging unlabelled data are crucial in overcoming large distribution gaps between the acquired datasets across different imaging devices and configurations. In this regard, self-training techniques based on pseudo-labeling have been shown to be highly effective for semi-supervised domain adaptation. However, the unreliability of pseudo labels can hinder the capability of self-training techniques to induce abstract representation from the unlabeled target dataset, especially in the case of large distribution gaps. Since the neural network performance should be invariant to image transformations, we look to this fact to identify uncertain pseudo labels. Indeed, we argue that transformation invariant detections can provide more reasonable approximations of ground truth. Accordingly, we propose a semi-supervised learning strategy for domain adaptation termed transformation-invariant self-training (TI-ST). The proposed method assesses pixel-wise pseudo-labels' reliability and filters out unreliable detections during self-training. We perform comprehensive evaluations for domain adaptation using three different modalities of medical images, two different network architectures, and several alternative state-of-the-art domain adaptation methods. Experimental results confirm the superiority of our proposed method in mitigating the lack of target domain annotation and boosting segmentation performance in the target domain.