 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Image Modelling for retinal OCT understanding
May 23, 2024



This work explores the effectiveness of masked image modelling for learning representations of retinal OCT images. To this end, we leverage Masked Autoencoders (MAE), a simple and scalable method for self-supervised learning, to obtain a powerful and general representation for OCT images by training on 700K OCT images from 41K patients collected under real world clinical settings. We also provide the first extensive evaluation for a model of OCT on a challenging battery of 6 downstream tasks. Our model achieves strong performance when fully finetuned but can also serve as a versatile frozen feature extractor for many tasks using lightweight adapters. Furthermore, we propose an extension of the MAE pretraining to fuse OCT with an auxiliary modality, namely, IR fundus images and learn a joint model for both. We demonstrate our approach improves performance on a multimodal downstream application. Our experiments utilize most publicly available OCT datasets, thus enabling future comparisons. Our code and model weights are publicly available https://github.com/TheoPis/MIM_OCT.
Cataract-1K: Cataract Surgery Dataset for Scene Segmentation, Phase Recognition, and Irregularity Detection
Dec 11, 2023In recent years, the landscape of computer-assisted interventions and post-operative surgical video analysis has been dramatically reshaped by deep-learning techniques, resulting in significant advancements in surgeons' skills, operation room management, and overall surgical outcomes. However, the progression of deep-learning-powered surgical technologies is profoundly reliant on large-scale datasets and annotations. Particularly, surgical scene understanding and phase recognition stand as pivotal pillars within the realm of computer-assisted surgery and post-operative assessment of cataract surgery videos. In this context, we present the largest cataract surgery video dataset that addresses diverse requisites for constructing computerized surgical workflow analysis and detecting post-operative irregularities in cataract surgery. We validate the quality of annotations by benchmarking the performance of several state-of-the-art neural network architectures for phase recognition and surgical scene segmentation. Besides, we initiate the research on domain adaptation for instrument segmentation in cataract surgery by evaluating cross-domain instrument segmentation performance in cataract surgery videos. The dataset and annotations will be publicly available upon acceptance of the paper.
DeepPyramid+: Medical Image Segmentation using Pyramid View Fusion and Deformable Pyramid Reception
Dec 06, 2023Semantic Segmentation plays a pivotal role in many applications related to medical image and video analysis. However, designing a neural network architecture for medical image and surgical video segmentation is challenging due to the diverse features of relevant classes, including heterogeneity, deformability, transparency, blunt boundaries, and various distortions. We propose a network architecture, DeepPyramid+, which addresses diverse challenges encountered in medical image and surgical video segmentation. The proposed DeepPyramid+ incorporates two major modules, namely "Pyramid View Fusion" (PVF) and "Deformable Pyramid Reception," (DPR), to address the outlined challenges. PVF replicates a deduction process within the neural network, aligning with the human visual system, thereby enhancing the representation of relative information at each pixel position. Complementarily, DPR introduces shape- and scale-adaptive feature extraction techniques using dilated deformable convolutions, enhancing accuracy and robustness in handling heterogeneous classes and deformable shapes. Extensive experiments conducted on diverse datasets, including endometriosis videos, MRI images, OCT scans, and cataract and laparoscopy videos, demonstrate the effectiveness of DeepPyramid+ in handling various challenges such as shape and scale variation, reflection, and blur degradation. DeepPyramid+ demonstrates significant improvements in segmentation performance, achieving up to a 3.65% increase in Dice coefficient for intra-domain segmentation and up to a 17% increase in Dice coefficient for cross-domain segmentation. DeepPyramid+ consistently outperforms state-of-the-art networks across diverse modalities considering different backbone networks, showcasing its versatility.
Domain Adaptation for Medical Image Segmentation using Transformation-Invariant Self-Training
Jul 31, 2023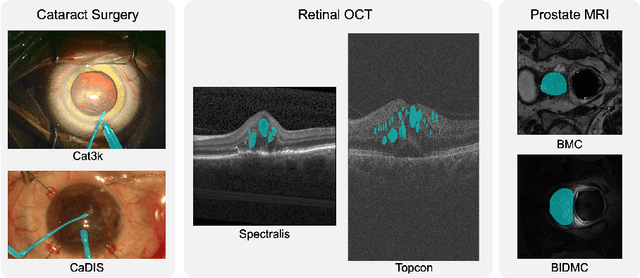

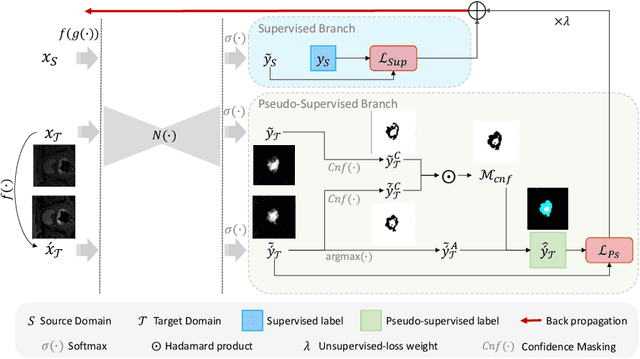

Models capable of leveraging unlabelled data are crucial in overcoming large distribution gaps between the acquired datasets across different imaging devices and configurations. In this regard, self-training techniques based on pseudo-labeling have been shown to be highly effective for semi-supervised domain adaptation. However, the unreliability of pseudo labels can hinder the capability of self-training techniques to induce abstract representation from the unlabeled target dataset, especially in the case of large distribution gaps. Since the neural network performance should be invariant to image transformations, we look to this fact to identify uncertain pseudo labels. Indeed, we argue that transformation invariant detections can provide more reasonable approximations of ground truth. Accordingly, we propose a semi-supervised learning strategy for domain adaptation termed transformation-invariant self-training (TI-ST). The proposed method assesses pixel-wise pseudo-labels' reliability and filters out unreliable detections during self-training. We perform comprehensive evaluations for domain adaptation using three different modalities of medical images, two different network architectures, and several alternative state-of-the-art domain adaptation methods. Experimental results confirm the superiority of our proposed method in mitigating the lack of target domain annotation and boosting segmentation performance in the target domain.
Unsupervised out-of-distribution detection for safer robotically guided retinal microsurgery
May 03, 2023Purpose: A fundamental problem in designing safe machine learning systems is identifying when samples presented to a deployed model differ from those observed at training time. Detecting so-called out-of-distribution (OoD) samples is crucial in safety-critical applications such as robotically guided retinal microsurgery, where distances between the instrument and the retina are derived from sequences of 1D images that are acquired by an instrument-integrated optical coherence tomography (iiOCT) probe. Methods: This work investigates the feasibility of using an OoD detector to identify when images from the iiOCT probe are inappropriate for subsequent machine learning-based distance estimation. We show how a simple OoD detector based on the Mahalanobis distance can successfully reject corrupted samples coming from real-world ex vivo porcine eyes. Results: Our results demonstrate that the proposed approach can successfully detect OoD samples and help maintain the performance of the downstream task within reasonable levels. MahaAD outperformed a supervised approach trained on the same kind of corruptions and achieved the best performance in detecting OoD cases from a collection of iiOCT samples with real-world corruptions. Conclusion: The results indicate that detecting corrupted iiOCT data through OoD detection is feasible and does not need prior knowledge of possible corruptions. Consequently, MahaAD could aid in ensuring patient safety during robotically guided microsurgery by preventing deployed prediction models from estimating distances that put the patient at risk.
CataNet: Predicting remaining cataract surgery duration
Jun 21, 2021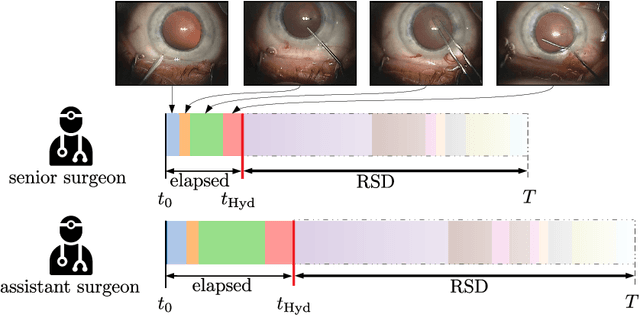
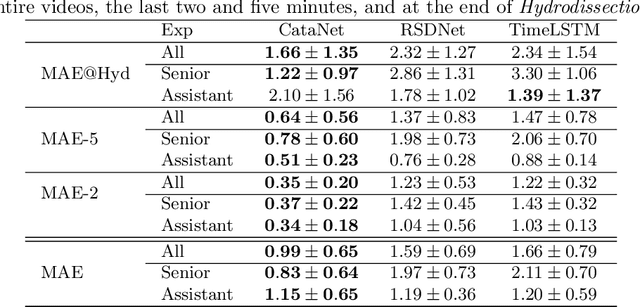
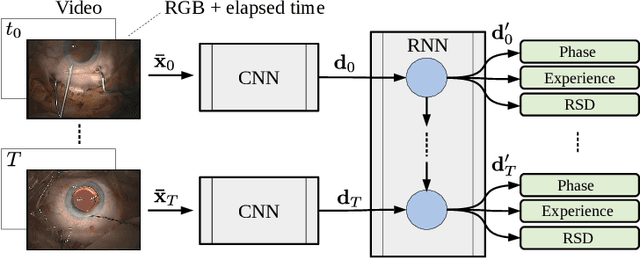

Cataract surgery is a sight saving surgery that is performed over 10 million times each year around the world. With such a large demand, the ability to organize surgical wards and operating rooms efficiently is critical to delivery this therapy in routine clinical care. In this context, estimating the remaining surgical duration (RSD) during procedures is one way to help streamline patient throughput and workflows. To this end, we propose CataNet, a method for cataract surgeries that predicts in real time the RSD jointly with two influential elements: the surgeon's experience, and the current phase of the surgery. We compare CataNet to state-of-the-art RSD estimation methods, showing that it outperforms them even when phase and experience are not considered. We investigate this improvement and show that a significant contributor is the way we integrate the elapsed time into CataNet's feature extractor.