 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmolVLM: Redefining small and efficient multimodal models
Apr 07, 2025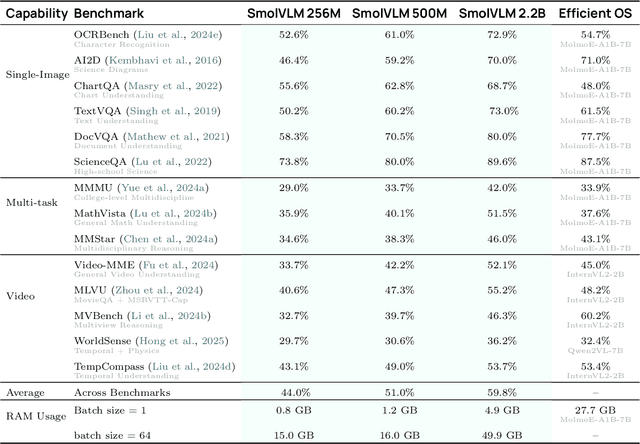
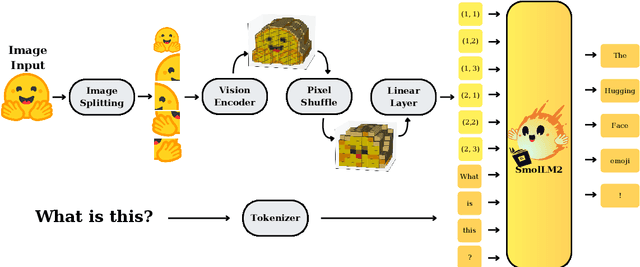
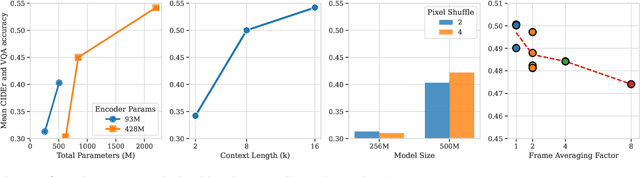

Large Vision-Language Models (VLMs) deliver exceptional performance but require significant computational resources, limiting their deployment on mobile and edge devices. Smaller VLMs typically mirror design choices of larger models, such as extensive image tokenization, leading to inefficient GPU memory usage and constrained practicality for on-device applications. We introduce SmolVLM, a series of compact multimodal models specifically engineered for resource-efficient inference. We systematically explore architectural configurations, tokenization strategies, and data curation optimized for low computational overhead. Through this, we identify key design choices that yield substantial performance gains on image and video tasks with minimal memory footprints. Our smallest model, SmolVLM-256M, uses less than 1GB GPU memory during inference and outperforms the 300-times larger Idefics-80B model, despite an 18-month development gap. Our largest model, at 2.2B parameters, rivals state-of-the-art VLMs consuming twice the GPU memory. SmolVLM models extend beyond static images, demonstrating robust video comprehension capabilities. Our results emphasize that strategic architectural optimizations, aggressive yet efficient tokenization, and carefully curated training data significantly enhance multimodal performance, facilitating practical, energy-efficient deployments at significantly smaller scales.
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
Feb 04, 2025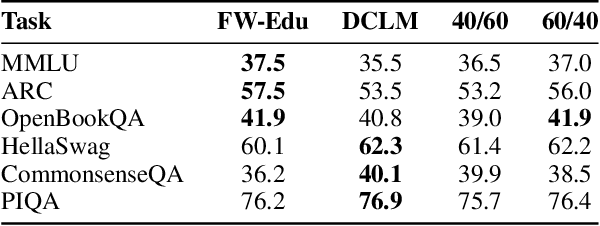
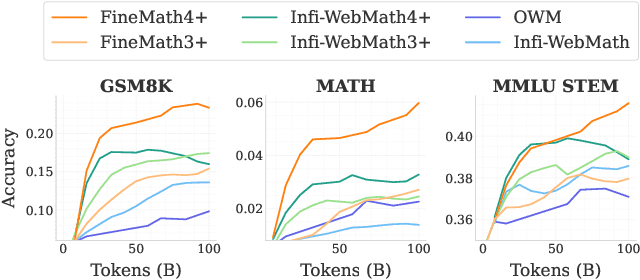
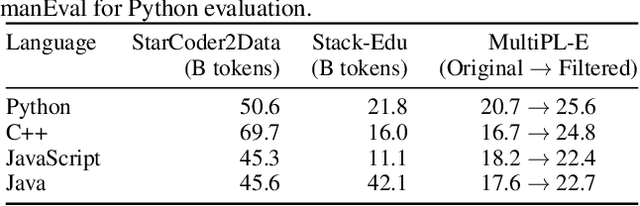
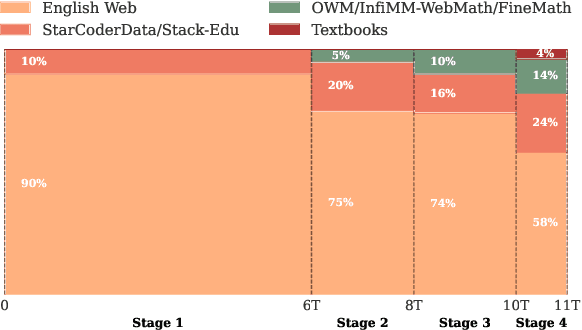
While large language models have facilitated breakthroughs in many applications of artificial intelligence, their inherent largeness makes them computationally expensive and challenging to deploy in resource-constrained settings. In this paper, we document the development of SmolLM2, a state-of-the-art "small" (1.7 billion parameter) language model (LM). To attain strong performance, we overtrain SmolLM2 on ~11 trillion tokens of data using a multi-stage training process that mixes web text with specialized math, code, and instruction-following data. We additionally introduce new specialized datasets (FineMath, Stack-Edu, and SmolTalk) at stages where we found existing datasets to be problematically small or low-quality. To inform our design decisions, we perform both small-scale ablations as well as a manual refinement process that updates the dataset mixing rates at each stage based on the performance at the previous stage. Ultimately, we demonstrate that SmolLM2 outperforms other recent small LMs including Qwen2.5-1.5B and Llama3.2-1B. To facilitate future research on LM development as well as applications of small LMs, we release both SmolLM2 as well as all of the datasets we prepared in the course of this project.
Building and better understanding vision-language models: insights and future directions
Aug 22, 2024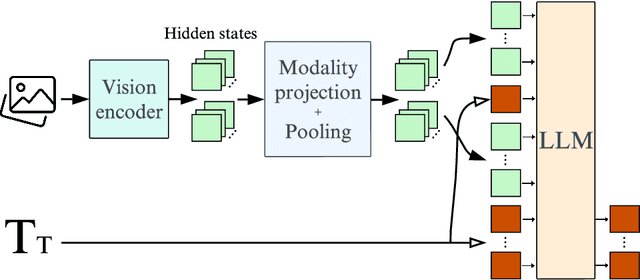
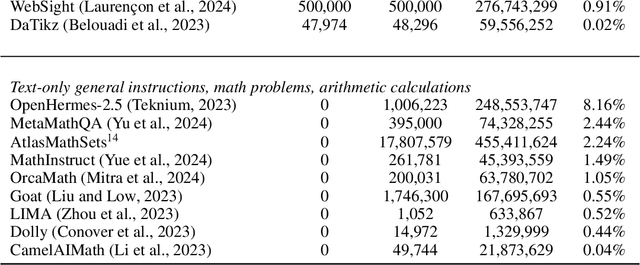

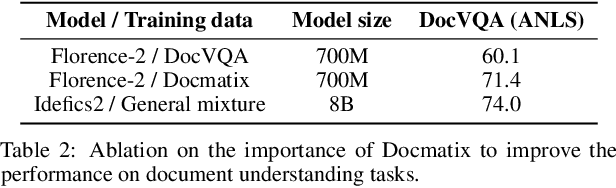
The field of vision-language models (VLMs), which take images and texts as inputs and output texts, is rapidly evolving and has yet to reach consensus on several key aspects of the development pipeline, including data, architecture, and training methods. This paper can be seen as a tutorial for building a VLM. We begin by providing a comprehensive overview of the current state-of-the-art approaches, highlighting the strengths and weaknesses of each, addressing the major challenges in the field, and suggesting promising research directions for underexplored areas. We then walk through the practical steps to build Idefics3-8B, a powerful VLM that significantly outperforms its predecessor Idefics2-8B, while being trained efficiently, exclusively on open datasets, and using a straightforward pipeline. These steps include the creation of Docmatix, a dataset for improving document understanding capabilities, which is 240 times larger than previously available datasets. We release the model along with the datasets created for its training.
CataNet: Predicting remaining cataract surgery duration
Jun 21, 2021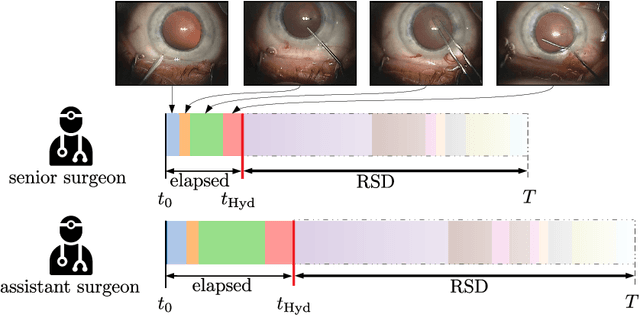
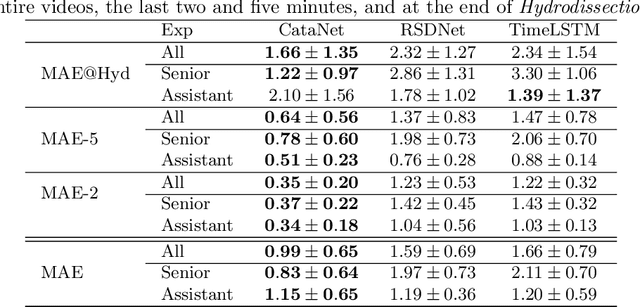
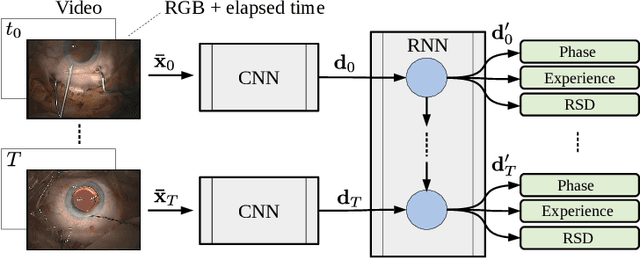

Cataract surgery is a sight saving surgery that is performed over 10 million times each year around the world. With such a large demand, the ability to organize surgical wards and operating rooms efficiently is critical to delivery this therapy in routine clinical care. In this context, estimating the remaining surgical duration (RSD) during procedures is one way to help streamline patient throughput and workflows. To this end, we propose CataNet, a method for cataract surgeries that predicts in real time the RSD jointly with two influential elements: the surgeon's experience, and the current phase of the surgery. We compare CataNet to state-of-the-art RSD estimation methods, showing that it outperforms them even when phase and experience are not considered. We investigate this improvement and show that a significant contributor is the way we integrate the elapsed time into CataNet's feature extractor.
Time-Frequency Phase Retrieval for Audio -- The Effect of Transform Parameters
Jun 09, 2021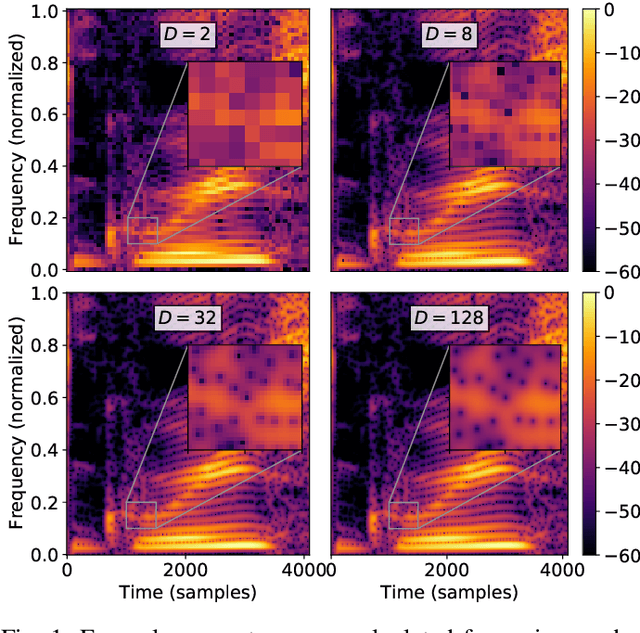
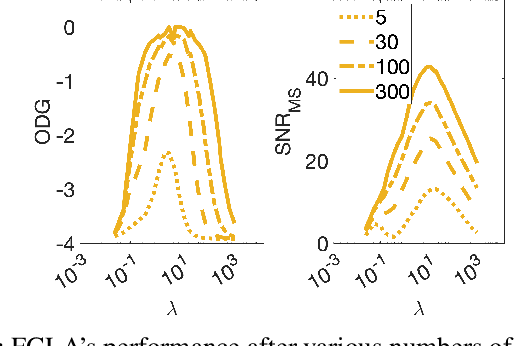
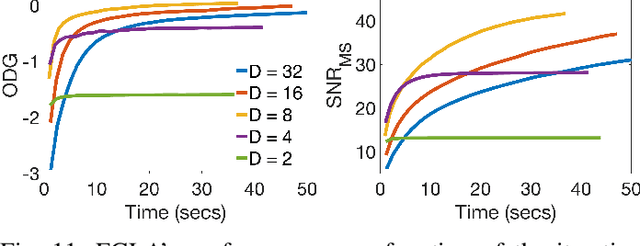
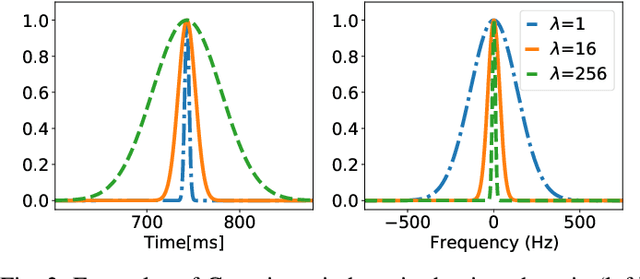
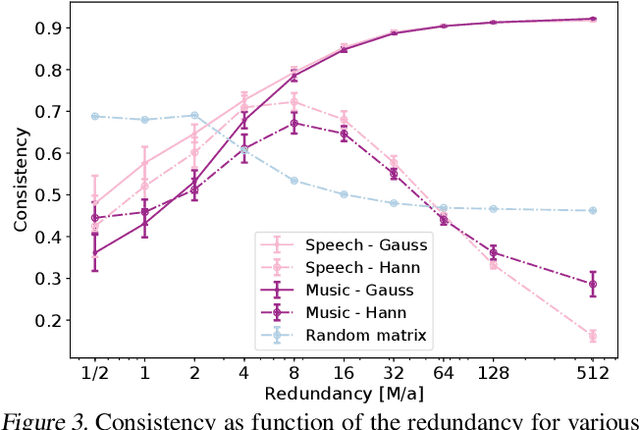
In audio processing applications, phase retrieval (PR) is often performed from the magnitude of short-time Fourier transform (STFT) coefficients. Although PR performance has been observed to depend on the considered STFT parameters and audio data, the extent of this dependence has not been systematically evaluated yet. To address this, we studied the performance of three PR algorithms for various types of audio content and various STFT parameters such as redundancy, time-frequency ratio, and the type of window. The quality of PR was studied in terms of objective difference grade and signal-to-noise ratio of the STFT magnitude, to provide auditory- and signal-based quality assessments. Our results show that PR quality improved with increasing redundancy, with a strong relevance of the time-frequency ratio. The effect of the audio content was smaller but still observable. The effect of the window was only significant for one of the PR algorithms. Interestingly, for a good PR quality, each of the three algorithms required a different set of parameters, demonstrating the relevance of individual parameter sets for a fair comparison across PR algorithms. Based on these results, we developed guidelines for optimizing STFT parameters for a given application.
Adversarial Generation of Time-Frequency Features with application in audio synthesis
Feb 11, 2019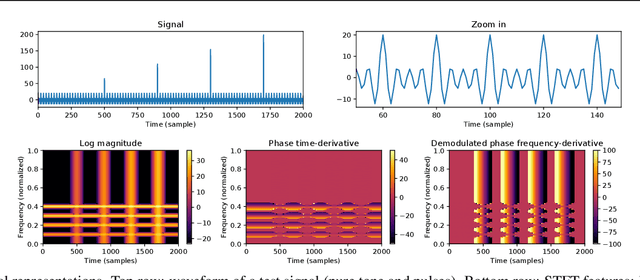

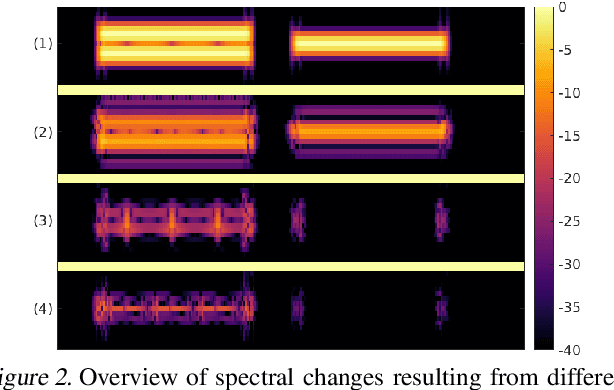
Time-frequency (TF) representations provide powerful and intuitive features for the analysis of time series such as audio. But still, generative modeling of audio in the TF domain is a subtle matter. Consequently, neural audio synthesis widely relies on directly modeling the waveform and previous attempts at unconditionally synthesizing audio from neurally generated TF features still struggle to produce audio at satisfying quality. In this contribution, focusing on the short-time Fourier transform, we discuss the challenges that arise in audio synthesis based on generated TF features and how to overcome them. We demonstrate the potential of deliberate generative TF modeling by training a generative adversarial network (GAN) on short-time Fourier features. We show that our TF-based network was able to outperform the state-of-the-art GAN generating waveform, despite the similar architecture in the two networks.
A context encoder for audio inpainting
Oct 29, 2018
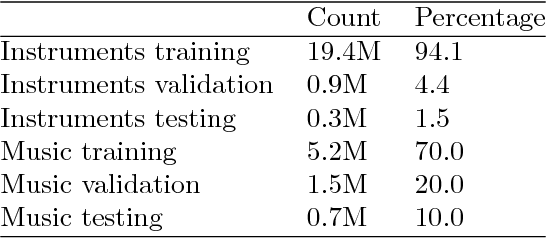
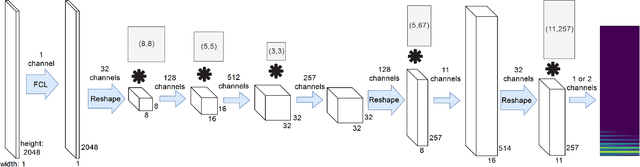
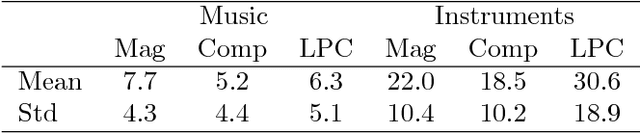
We studied the ability of deep neural networks (DNNs) to restore missing audio content based on its context, a process usually referred to as audio inpainting. We focused on gaps in the range of tens of milliseconds, a condition which has not received much attention yet. The proposed DNN structure was trained on audio signals containing music and musical instruments, separately, with 64-ms long gaps. The input to the DNN was the context, i.e., the signal surrounding the gap, transformed into time-frequency (TF) coefficients. Two networks were analyzed, a DNN with complex-valued TF coefficient output and another one producing magnitude TF coefficient output, both based on the same network architecture. We found significant differences in the inpainting results between the two DNNs. In particular, we discuss the observation that the complex-valued DNN fails to produce reliable results outside the low frequency range. Further, our results were compared to those obtained from a reference method based on linear predictive coding (LPC). For instruments, our DNNs were not able to match the performance of reference method, although the magnitude network provided good results as well. For music, however, our magnitude DNN significantly outperformed the reference method, demonstrating a generally good usability of the proposed DNN structure for inpainting complex audio signals like music. This paves the road towards future, more sophisticated audio inpainting approaches based on DNNs.