 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language
Jun 26, 2025Pre-training state-of-the-art large language models (LLMs) requires vast amounts of clean and diverse text data. While the open development of large high-quality English pre-training datasets has seen substantial recent progress, training performant multilingual LLMs remains a challenge, in large part due to the inherent difficulty of tailoring filtering and deduplication pipelines to a large number of languages. In this work, we introduce a new pre-training dataset curation pipeline based on FineWeb that can be automatically adapted to support any language. We extensively ablate our pipeline design choices on a set of nine diverse languages, guided by a set of meaningful and informative evaluation tasks that were chosen through a novel selection process based on measurable criteria. Ultimately, we show that our pipeline can be used to create non-English corpora that produce more performant models than prior datasets. We additionally introduce a straightforward and principled approach to rebalance datasets that takes into consideration both duplication count and quality, providing an additional performance uplift. Finally, we scale our pipeline to over 1000 languages using almost 100 Common Crawl snapshots to produce FineWeb2, a new 20 terabyte (5 billion document) multilingual dataset which we release along with our pipeline, training, and evaluation codebases.
The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
Jun 05, 2025Large language models (LLMs) are typically trained on enormous quantities of unlicensed text, a practice that has led to scrutiny due to possible intellectual property infringement and ethical concerns. Training LLMs on openly licensed text presents a first step towards addressing these issues, but prior data collection efforts have yielded datasets too small or low-quality to produce performant LLMs. To address this gap, we collect, curate, and release the Common Pile v0.1, an eight terabyte collection of openly licensed text designed for LLM pretraining. The Common Pile comprises content from 30 sources that span diverse domains including research papers, code, books, encyclopedias, educational materials, audio transcripts, and more. Crucially, we validate our efforts by training two 7 billion parameter LLMs on text from the Common Pile: Comma v0.1-1T and Comma v0.1-2T, trained on 1 and 2 trillion tokens respectively. Both models attain competitive performance to LLMs trained on unlicensed text with similar computational budgets, such as Llama 1 and 2 7B. In addition to releasing the Common Pile v0.1 itself, we also release the code used in its creation as well as the training mixture and checkpoints for the Comma v0.1 models.
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
Feb 04, 2025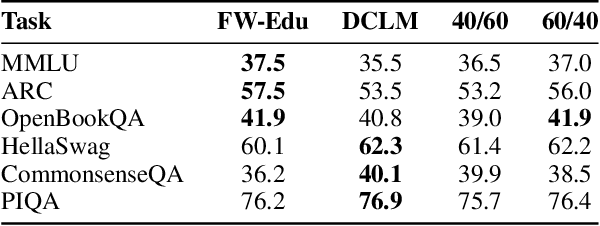
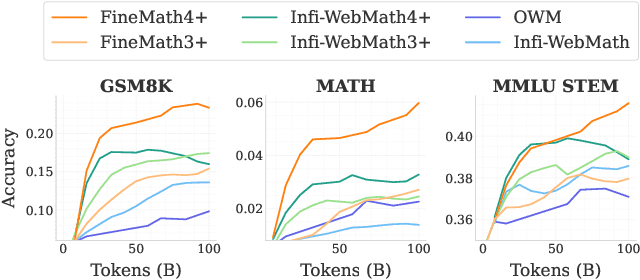
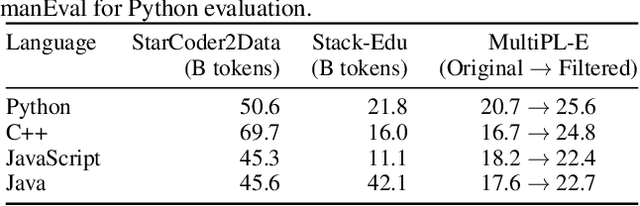
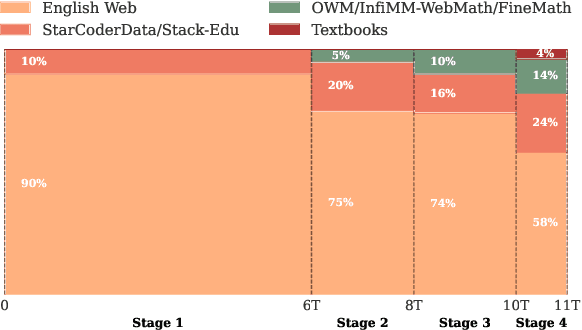
While large language models have facilitated breakthroughs in many applications of artificial intelligence, their inherent largeness makes them computationally expensive and challenging to deploy in resource-constrained settings. In this paper, we document the development of SmolLM2, a state-of-the-art "small" (1.7 billion parameter) language model (LM). To attain strong performance, we overtrain SmolLM2 on ~11 trillion tokens of data using a multi-stage training process that mixes web text with specialized math, code, and instruction-following data. We additionally introduce new specialized datasets (FineMath, Stack-Edu, and SmolTalk) at stages where we found existing datasets to be problematically small or low-quality. To inform our design decisions, we perform both small-scale ablations as well as a manual refinement process that updates the dataset mixing rates at each stage based on the performance at the previous stage. Ultimately, we demonstrate that SmolLM2 outperforms other recent small LMs including Qwen2.5-1.5B and Llama3.2-1B. To facilitate future research on LM development as well as applications of small LMs, we release both SmolLM2 as well as all of the datasets we prepared in the course of this project.
Towards Best Practices for Open Datasets for LLM Training
Jan 14, 2025Many AI companies are training their large language models (LLMs) on data without the permission of the copyright owners. The permissibility of doing so varies by jurisdiction: in countries like the EU and Japan, this is allowed under certain restrictions, while in the United States, the legal landscape is more ambiguous. Regardless of the legal status, concerns from creative producers have led to several high-profile copyright lawsuits, and the threat of litigation is commonly cited as a reason for the recent trend towards minimizing the information shared about training datasets by both corporate and public interest actors. This trend in limiting data information causes harm by hindering transparency, accountability, and innovation in the broader ecosystem by denying researchers, auditors, and impacted individuals access to the information needed to understand AI models. While this could be mitigated by training language models on open access and public domain data, at the time of writing, there are no such models (trained at a meaningful scale) due to the substantial technical and sociological challenges in assembling the necessary corpus. These challenges include incomplete and unreliable metadata, the cost and complexity of digitizing physical records, and the diverse set of legal and technical skills required to ensure relevance and responsibility in a quickly changing landscape. Building towards a future where AI systems can be trained on openly licensed data that is responsibly curated and governed requires collaboration across legal, technical, and policy domains, along with investments in metadata standards, digitization, and fostering a culture of openness.
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Jun 25, 2024



The performance of a large language model (LLM) depends heavily on the quality and size of its pretraining dataset. However, the pretraining datasets for state-of-the-art open LLMs like Llama 3 and Mixtral are not publicly available and very little is known about how they were created. In this work, we introduce FineWeb, a 15-trillion token dataset derived from 96 Common Crawl snapshots that produces better-performing LLMs than other open pretraining datasets. To advance the understanding of how best to curate high-quality pretraining datasets, we carefully document and ablate all of the design choices used in FineWeb, including in-depth investigations of deduplication and filtering strategies. In addition, we introduce FineWeb-Edu, a 1.3-trillion token collection of educational text filtered from FineWeb. LLMs pretrained on FineWeb-Edu exhibit dramatically better performance on knowledge- and reasoning-intensive benchmarks like MMLU and ARC. Along with our datasets, we publicly release our data curation codebase and all of the models trained during our ablation experiments.
The Falcon Series of Open Language Models
Nov 29, 2023



We introduce the Falcon series: 7B, 40B, and 180B parameters causal decoder-only models trained on a diverse high-quality corpora predominantly assembled from web data. The largest model, Falcon-180B, has been trained on over 3.5 trillion tokens of text--the largest openly documented pretraining run. Falcon-180B significantly outperforms models such as PaLM or Chinchilla, and improves upon concurrently developed models such as LLaMA 2 or Inflection-1. It nears the performance of PaLM-2-Large at a reduced pretraining and inference cost, making it, to our knowledge, one of the three best language models in the world along with GPT-4 and PaLM-2-Large. We report detailed evaluations, as well as a deep dive into the methods and custom tooling employed to pretrain Falcon. Notably, we report on our custom distributed training codebase, allowing us to efficiently pretrain these models on up to 4,096 A100s on cloud AWS infrastructure with limited interconnect. We release a 600B tokens extract of our web dataset, as well as the Falcon-7/40/180B models under a permissive license to foster open-science and accelerate the development of an open ecosystem of large language models.
The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only
Jun 01, 2023



Large language models are commonly trained on a mixture of filtered web data and curated high-quality corpora, such as social media conversations, books, or technical papers. This curation process is believed to be necessary to produce performant models with broad zero-shot generalization abilities. However, as larger models requiring pretraining on trillions of tokens are considered, it is unclear how scalable is curation and whether we will run out of unique high-quality data soon. At variance with previous beliefs, we show that properly filtered and deduplicated web data alone can lead to powerful models; even significantly outperforming models from the state-of-the-art trained on The Pile. Despite extensive filtering, the high-quality data we extract from the web is still plentiful, and we are able to obtain five trillion tokens from CommonCrawl. We publicly release an extract of 600 billion tokens from our RefinedWeb dataset, and 1.3/7.5B parameters language models trained on it.