 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Falcon Series of Open Language Models
Nov 29, 2023



We introduce the Falcon series: 7B, 40B, and 180B parameters causal decoder-only models trained on a diverse high-quality corpora predominantly assembled from web data. The largest model, Falcon-180B, has been trained on over 3.5 trillion tokens of text--the largest openly documented pretraining run. Falcon-180B significantly outperforms models such as PaLM or Chinchilla, and improves upon concurrently developed models such as LLaMA 2 or Inflection-1. It nears the performance of PaLM-2-Large at a reduced pretraining and inference cost, making it, to our knowledge, one of the three best language models in the world along with GPT-4 and PaLM-2-Large. We report detailed evaluations, as well as a deep dive into the methods and custom tooling employed to pretrain Falcon. Notably, we report on our custom distributed training codebase, allowing us to efficiently pretrain these models on up to 4,096 A100s on cloud AWS infrastructure with limited interconnect. We release a 600B tokens extract of our web dataset, as well as the Falcon-7/40/180B models under a permissive license to foster open-science and accelerate the development of an open ecosystem of large language models.
Emergent Communication in Multi-Agent Reinforcement Learning for Future Wireless Networks
Sep 12, 2023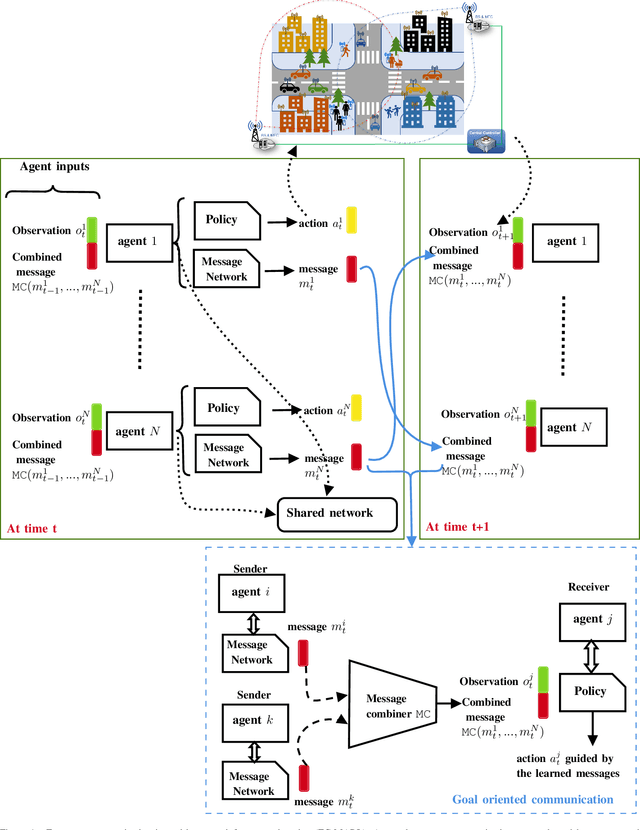
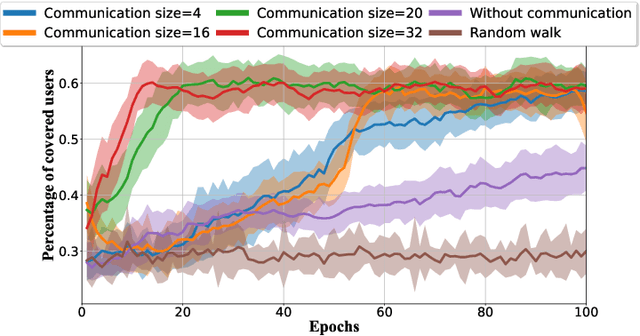
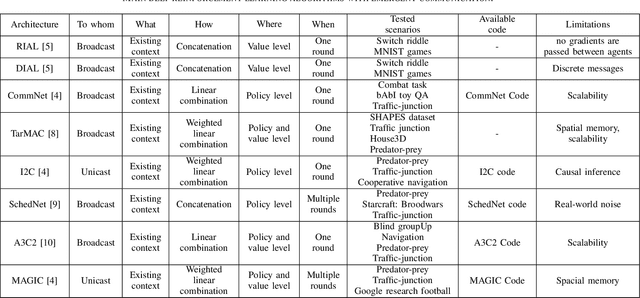
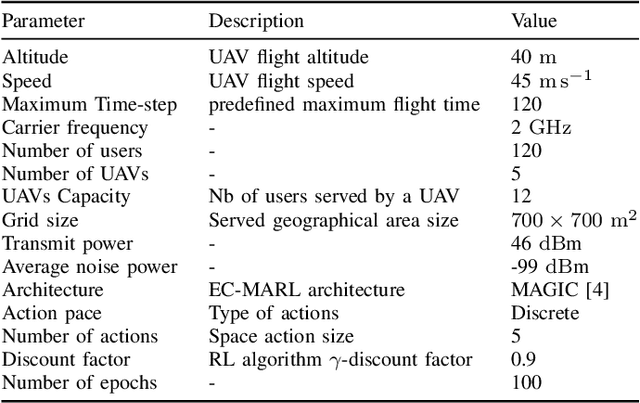
In different wireless network scenarios, multiple network entities need to cooperate in order to achieve a common task with minimum delay and energy consumption. Future wireless networks mandate exchanging high dimensional data in dynamic and uncertain environments, therefore implementing communication control tasks becomes challenging and highly complex. Multi-agent reinforcement learning with emergent communication (EC-MARL) is a promising solution to address high dimensional continuous control problems with partially observable states in a cooperative fashion where agents build an emergent communication protocol to solve complex tasks. This paper articulates the importance of EC-MARL within the context of future 6G wireless networks, which imbues autonomous decision-making capabilities into network entities to solve complex tasks such as autonomous driving, robot navigation, flying base stations network planning, and smart city applications. An overview of EC-MARL algorithms and their design criteria are provided while presenting use cases and research opportunities on this emerging topic.
Joint Semantic-Native Communication and Inference via Minimal Simplicial Structures
Aug 31, 2023



In this work, we study the problem of semantic communication and inference, in which a student agent (i.e. mobile device) queries a teacher agent (i.e. cloud sever) to generate higher-order data semantics living in a simplicial complex. Specifically, the teacher first maps its data into a k-order simplicial complex and learns its high-order correlations. For effective communication and inference, the teacher seeks minimally sufficient and invariant semantic structures prior to conveying information. These minimal simplicial structures are found via judiciously removing simplices selected by the Hodge Laplacians without compromising the inference query accuracy. Subsequently, the student locally runs its own set of queries based on a masked simplicial convolutional autoencoder (SCAE) leveraging both local and remote teacher's knowledge. Numerical results corroborate the effectiveness of the proposed approach in terms of improving inference query accuracy under different channel conditions and simplicial structures. Experiments on a coauthorship dataset show that removing simplices by ranking the Laplacian values yields a 85% reduction in payload size without sacrificing accuracy. Joint semantic communication and inference by masked SCAE improves query accuracy by 25% compared to local student based query and 15% compared to remote teacher based query. Finally, incorporating channel semantics is shown to effectively improve inference accuracy, notably at low SNR values.
The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only
Jun 01, 2023



Large language models are commonly trained on a mixture of filtered web data and curated high-quality corpora, such as social media conversations, books, or technical papers. This curation process is believed to be necessary to produce performant models with broad zero-shot generalization abilities. However, as larger models requiring pretraining on trillions of tokens are considered, it is unclear how scalable is curation and whether we will run out of unique high-quality data soon. At variance with previous beliefs, we show that properly filtered and deduplicated web data alone can lead to powerful models; even significantly outperforming models from the state-of-the-art trained on The Pile. Despite extensive filtering, the high-quality data we extract from the web is still plentiful, and we are able to obtain five trillion tokens from CommonCrawl. We publicly release an extract of 600 billion tokens from our RefinedWeb dataset, and 1.3/7.5B parameters language models trained on it.
A Review and a Taxonomy of Edge Machine Learning: Requirements, Paradigms, and Techniques
Feb 16, 2023The union of Edge Computing (EC) and Artificial Intelligence (AI) has brought forward the Edge AI concept to provide intelligent solutions close to end-user environment, for privacy preservation, low latency to real-time performance, as well as resource optimization. Machine Learning (ML), as the most advanced branch of AI in the past few years, has shown encouraging results and applications in the edge environment. Nevertheless, edge powered ML solutions are more complex to realize due to the joint constraints from both edge computing and AI domains, and the corresponding solutions are expected to be efficient and adapted in technologies such as data processing, model compression, distributed inference, and advanced learning paradigms for Edge ML requirements. Despite that a great attention of Edge ML is gained in both academic and industrial communities, we noticed the lack of a complete survey on existing Edge ML technologies to provide a common understanding of this concept. To tackle this, this paper aims at providing a comprehensive taxonomy and a systematic review of Edge ML techniques: we start by identifying the Edge ML requirements driven by the joint constraints. We then survey more than twenty paradigms and techniques along with their representative work, covering two main parts: edge inference, and edge learning. In particular, we analyze how each technique fits into Edge ML by meeting a subset of the identified requirements. We also summarize Edge ML open issues to shed light on future directions for Edge ML.