 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalcon-H1R: Pushing the Reasoning Frontiers with a Hybrid Model for Efficient Test-Time Scaling
Jan 05, 2026This work introduces Falcon-H1R, a 7B-parameter reasoning-optimized model that establishes the feasibility of achieving competitive reasoning performance with small language models (SLMs). Falcon-H1R stands out for its parameter efficiency, consistently matching or outperforming SOTA reasoning models that are $2\times$ to $7\times$ larger across a variety of reasoning-intensive benchmarks. These results underscore the importance of careful data curation and targeted training strategies (via both efficient SFT and RL scaling) in delivering significant performance gains without increasing model size. Furthermore, Falcon-H1R advances the 3D limits of reasoning efficiency by combining faster inference (through its hybrid-parallel architecture design), token efficiency, and higher accuracy. This unique blend makes Falcon-H1R-7B a practical backbone for scaling advanced reasoning systems, particularly in scenarios requiring extensive chain-of-thoughts generation and parallel test-time scaling. Leveraging the recently introduced DeepConf approach, Falcon-H1R achieves state-of-the-art test-time scaling efficiency, offering substantial improvements in both accuracy and computational cost. As a result, Falcon-H1R demonstrates that compact models, through targeted model training and architectural choices, can deliver robust and scalable reasoning performance.
NeurIPS 2025 E2LM Competition : Early Training Evaluation of Language Models
Jun 09, 2025Existing benchmarks have proven effective for assessing the performance of fully trained large language models. However, we find striking differences in the early training stages of small models, where benchmarks often fail to provide meaningful or discriminative signals. To explore how these differences arise, this competition tackles the challenge of designing scientific knowledge evaluation tasks specifically tailored for measuring early training progress of language models. Participants are invited to develop novel evaluation methodologies or adapt existing benchmarks to better capture performance differences among language models. To support this effort, we provide three pre-trained small models (0.5B, 1B, and 3B parameters), along with intermediate checkpoints sampled during training up to 200B tokens. All experiments and development work can be run on widely available free cloud-based GPU platforms, making participation accessible to researchers with limited computational resources. Submissions will be evaluated based on three criteria: the quality of the performance signal they produce, the consistency of model rankings at 1 trillion tokens of training, and their relevance to the scientific knowledge domain. By promoting the design of tailored evaluation strategies for early training, this competition aims to attract a broad range of participants from various disciplines, including those who may not be machine learning experts or have access to dedicated GPU resources. Ultimately, this initiative seeks to make foundational LLM research more systematic and benchmark-informed from the earliest phases of model development.
Maximizing the Potential of Synthetic Data: Insights from Random Matrix Theory
Oct 11, 2024



Synthetic data has gained attention for training large language models, but poor-quality data can harm performance (see, e.g., Shumailov et al. (2023); Seddik et al. (2024)). A potential solution is data pruning, which retains only high-quality data based on a score function (human or machine feedback). Previous work Feng et al. (2024) analyzed models trained on synthetic data as sample size increases. We extend this by using random matrix theory to derive the performance of a binary classifier trained on a mix of real and pruned synthetic data in a high dimensional setting. Our findings identify conditions where synthetic data could improve performance, focusing on the quality of the generative model and verification strategy. We also show a smooth phase transition in synthetic label noise, contrasting with prior sharp behavior in infinite sample limits. Experiments with toy models and large language models validate our theoretical results.
Alignment with Preference Optimization Is All You Need for LLM Safety
Sep 12, 2024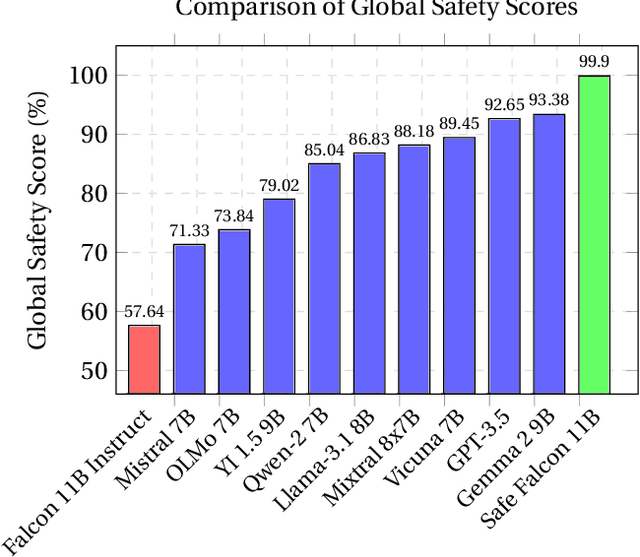
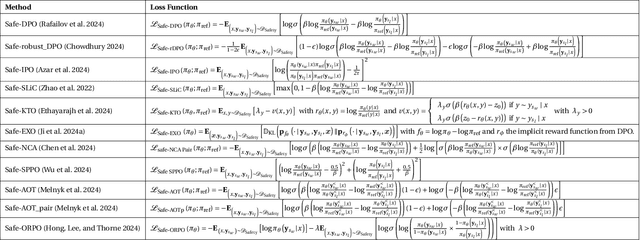
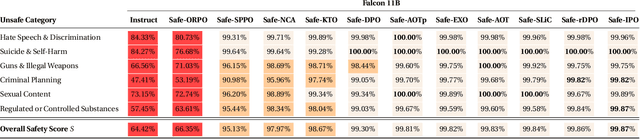

We demonstrate that preference optimization methods can effectively enhance LLM safety. Applying various alignment techniques to the Falcon 11B model using safety datasets, we achieve a significant boost in global safety score (from $57.64\%$ to $99.90\%$) as measured by LlamaGuard 3 8B, competing with state-of-the-art models. On toxicity benchmarks, average scores in adversarial settings dropped from over $0.6$ to less than $0.07$. However, this safety improvement comes at the cost of reduced general capabilities, particularly in math, suggesting a trade-off. We identify noise contrastive alignment (Safe-NCA) as an optimal method for balancing safety and performance. Our study ultimately shows that alignment techniques can be sufficient for building safe and robust models.
Falcon2-11B Technical Report
Jul 20, 2024



We introduce Falcon2-11B, a foundation model trained on over five trillion tokens, and its multimodal counterpart, Falcon2-11B-vlm, which is a vision-to-text model. We report our findings during the training of the Falcon2-11B which follows a multi-stage approach where the early stages are distinguished by their context length and a final stage where we use a curated, high-quality dataset. Additionally, we report the effect of doubling the batch size mid-training and how training loss spikes are affected by the learning rate. The downstream performance of the foundation model is evaluated on established benchmarks, including multilingual and code datasets. The foundation model shows strong generalization across all the tasks which makes it suitable for downstream finetuning use cases. For the vision language model, we report the performance on several benchmarks and show that our model achieves a higher average score compared to open-source models of similar size. The model weights and code of both Falcon2-11B and Falcon2-11B-vlm are made available under a permissive license.
Investigating Regularization of Self-Play Language Models
Apr 04, 2024



This paper explores the effects of various forms of regularization in the context of language model alignment via self-play. While both reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO) require to collect costly human-annotated pairwise preferences, the self-play fine-tuning (SPIN) approach replaces the rejected answers by data generated from the previous iterate. However, the SPIN method presents a performance instability issue in the learning phase, which can be mitigated by playing against a mixture of the two previous iterates. In the same vein, we propose in this work to address this issue from two perspectives: first, by incorporating an additional Kullback-Leibler (KL) regularization to stay at the proximity of the reference policy; second, by using the idea of fictitious play which smoothens the opponent policy across all previous iterations. In particular, we show that the KL-based regularizer boils down to replacing the previous policy by its geometric mixture with the base policy inside of the SPIN loss function. We finally discuss empirical results on MT-Bench as well as on the Hugging Face Open LLM Leaderboard.
SCAFFLSA: Quantifying and Eliminating Heterogeneity Bias in Federated Linear Stochastic Approximation and Temporal Difference Learning
Feb 06, 2024In this paper, we perform a non-asymptotic analysis of the federated linear stochastic approximation (FedLSA) algorithm. We explicitly quantify the bias introduced by local training with heterogeneous agents, and investigate the sample complexity of the algorithm. We show that the communication complexity of FedLSA scales polynomially with the desired precision $\epsilon$, which limits the benefits of federation. To overcome this, we propose SCAFFLSA, a novel variant of FedLSA, that uses control variates to correct the bias of local training, and prove its convergence without assumptions on statistical heterogeneity. We apply the proposed methodology to federated temporal difference learning with linear function approximation, and analyze the corresponding complexity improvements.
A Risk-Averse Framework for Non-Stationary Stochastic Multi-Armed Bandits
Oct 24, 2023

In a typical stochastic multi-armed bandit problem, the objective is often to maximize the expected sum of rewards over some time horizon $T$. While the choice of a strategy that accomplishes that is optimal with no additional information, it is no longer the case when provided additional environment-specific knowledge. In particular, in areas of high volatility like healthcare or finance, a naive reward maximization approach often does not accurately capture the complexity of the learning problem and results in unreliable solutions. To tackle problems of this nature, we propose a framework of adaptive risk-aware strategies that operate in non-stationary environments. Our framework incorporates various risk measures prevalent in the literature to map multiple families of multi-armed bandit algorithms into a risk-sensitive setting. In addition, we equip the resulting algorithms with the Restarted Bayesian Online Change-Point Detection (R-BOCPD) algorithm and impose a (tunable) forced exploration strategy to detect local (per-arm) switches. We provide finite-time theoretical guarantees and an asymptotic regret bound of order $\tilde O(\sqrt{K_T T})$ up to time horizon $T$ with $K_T$ the total number of change-points. In practice, our framework compares favorably to the state-of-the-art in both synthetic and real-world environments and manages to perform efficiently with respect to both risk-sensitivity and non-stationarity.
Deep Reinforcement Learning Algorithms for Hybrid V2X Communication: A Benchmarking Study
Oct 04, 2023



In today's era, autonomous vehicles demand a safety level on par with aircraft. Taking a cue from the aerospace industry, which relies on redundancy to achieve high reliability, the automotive sector can also leverage this concept by building redundancy in V2X (Vehicle-to-Everything) technologies. Given the current lack of reliable V2X technologies, this idea is particularly promising. By deploying multiple RATs (Radio Access Technologies) in parallel, the ongoing debate over the standard technology for future vehicles can be put to rest. However, coordinating multiple communication technologies is a complex task due to dynamic, time-varying channels and varying traffic conditions. This paper addresses the vertical handover problem in V2X using Deep Reinforcement Learning (DRL) algorithms. The goal is to assist vehicles in selecting the most appropriate V2X technology (DSRC/V-VLC) in a serpentine environment. The results show that the benchmarked algorithms outperform the current state-of-the-art approaches in terms of redundancy and usage rate of V-VLC headlights. This result is a significant reduction in communication costs while maintaining a high level of reliability. These results provide strong evidence for integrating advanced DRL decision mechanisms into the architecture as a promising approach to solving the vertical handover problem in V2X.
Emergent Communication in Multi-Agent Reinforcement Learning for Future Wireless Networks
Sep 12, 2023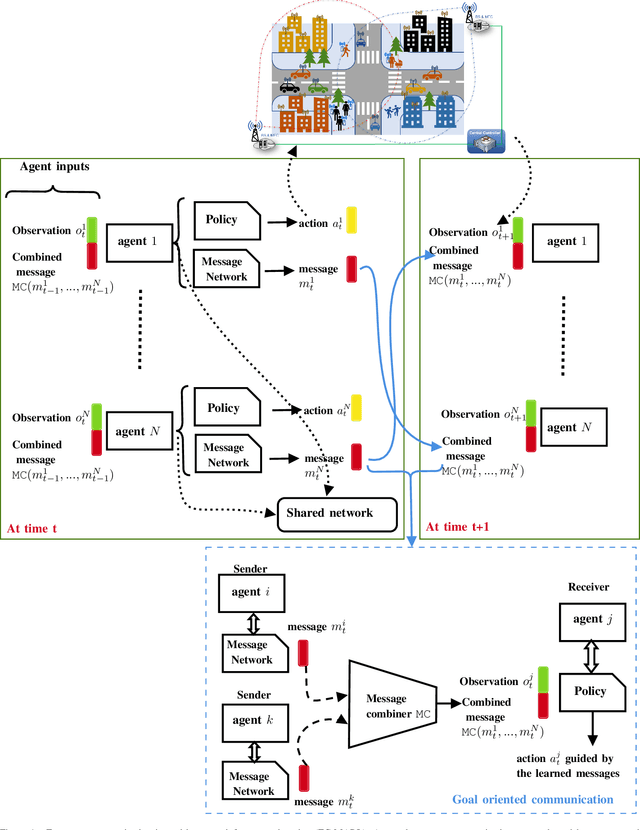
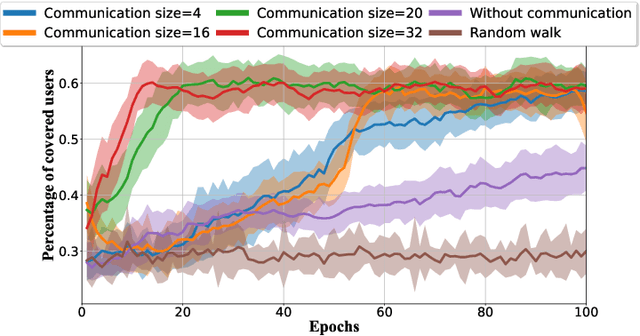
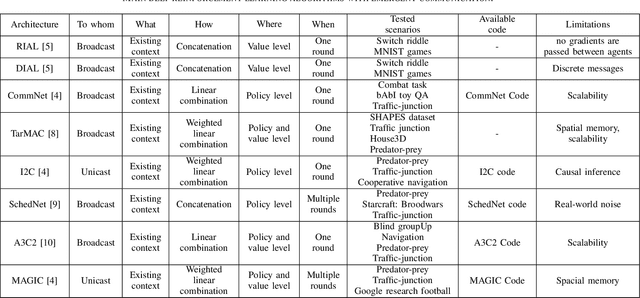
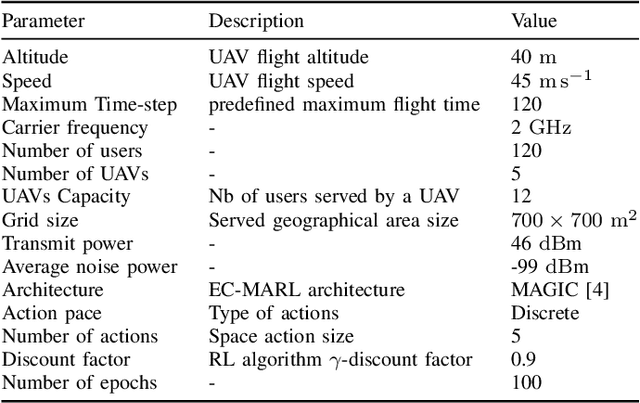
In different wireless network scenarios, multiple network entities need to cooperate in order to achieve a common task with minimum delay and energy consumption. Future wireless networks mandate exchanging high dimensional data in dynamic and uncertain environments, therefore implementing communication control tasks becomes challenging and highly complex. Multi-agent reinforcement learning with emergent communication (EC-MARL) is a promising solution to address high dimensional continuous control problems with partially observable states in a cooperative fashion where agents build an emergent communication protocol to solve complex tasks. This paper articulates the importance of EC-MARL within the context of future 6G wireless networks, which imbues autonomous decision-making capabilities into network entities to solve complex tasks such as autonomous driving, robot navigation, flying base stations network planning, and smart city applications. An overview of EC-MARL algorithms and their design criteria are provided while presenting use cases and research opportunities on this emerging topic.